一文快速入門分庫分表
本文轉載自微信公眾號「程序員內點事」,作者程序員內點事 。轉載本文請聯系程序員內點事公眾號。
之前有不少剛入坑 Java 的粉絲留言,想系統的學習一下分庫分表相關技術,可我一直沒下定決心搞,眼下趕上公司項目在使用 sharing-jdbc 對現有 MySQL 架構做分庫分表的改造,所以借此機會出一系分庫分表落地實踐的文章,也算是自己對架構學習的一個總結。
我在網上陸陸續續的也看了一些有關于分庫分表的文章,可發現網上同質化的資料有點多,而且知識點又都比較零碎,還沒有詳細的實戰案例。為了更深入的學習下,我在某些平臺買了點付費課程,看了幾節課發現有點經驗的人看還可以,但對于新手入門來說,其實學習難度還是蠻大的。
為了讓新手也能看得懂,有些知識點我可能會用更多的篇幅加以描述,希望大家不要嫌我啰嗦,等這分庫分表系列文章完結后,我會把它做成 PDF 文檔開源出去,能幫一個算一個吧!如果發現文中有哪些錯誤或不嚴謹之處,歡迎大家交流指正。
具體實踐分庫分表之前在啰嗦幾句,回頭復習下分庫分表的基礎概念。
什么是分庫分表
其實 分庫 和 分表 是兩個概念,只不過通常分庫與分表的操作會同時進行,以至于我們習慣性的將它們合在一起叫做分庫分表。
分庫分表是為了解決由于庫、表數據量過大,而導致數據庫性能持續下降的問題。按照一定的規則,將原本數據量大的數據庫拆分成多個單獨的數據庫,將原本數據量大的表拆分成若干個數據表,使得單一的庫、表性能達到最優的效果(響應速度快),以此提升整體數據庫性能。
如何分庫分表
分庫分表的核心理念就是對數據進行切分(Sharding),以及切分后如何對數據的快速定位與查詢結果整合。而分庫與分表都可以從:垂直(縱向)和 水平(橫向)兩種緯度進行切分。
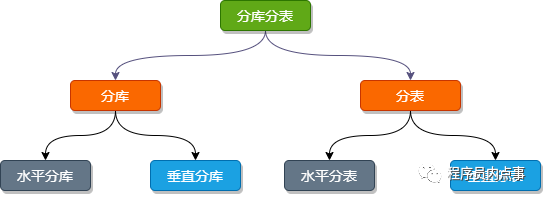
分庫分表
下邊我們就以訂單相關的業務舉例,看看如何做庫、表的 垂直 和 水平 切分。
垂直切分
垂直切分有 垂直 分庫 和 垂直分表。
1、垂直分庫
垂直分庫相對來說是比較好理解的,核心理念就四個字:專庫專用。
按業務類型對表進行分類,像訂單、支付、優惠券、積分等相應的表放在對應的數據庫中。開發者不可以跨庫直連別的業務數據庫,想要其他業務數據,對應業務方可以提供 API 接口,這就是微服務的初始形態。
垂直分庫很大程度上取決于業務的劃分,但有時候業務間的劃分并不是那么清晰,比如:訂單數據的拆分要考慮到與其他業務間的關聯關系,并不是說直接把訂單相關的表放在一個庫里這么簡單。
在一定程度上,垂直分庫似乎提升了一些數據庫性能,可實際上并沒有解決由于單表數據量過大導致的性能問題,所以就需要配合水平切分方式來解決。
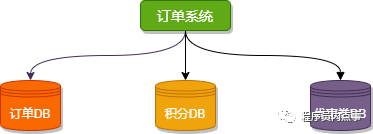
垂直分庫
2、垂直分表
垂直分表是基于數據表的列(字段)為依據切分的,是一種大表拆小表的模式。
例如:一張 order 訂單表,將訂單金額、訂單編號等訪問頻繁的字段,單獨拆成一張表,把 blob 類型這樣的大字段或訪問不頻繁的字段,拆分出來創建一個單獨的擴展表 work_extend ,這樣每張表只存儲原表的一部分字段,再將拆分出來的表分散到不同的庫中。
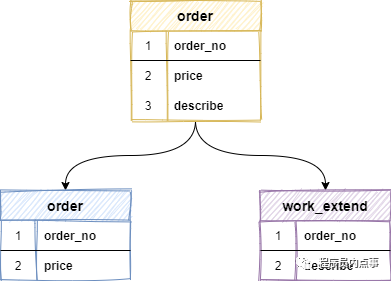
垂直分表
我們知道數據庫是以行為單位將數據加載到內存中,這樣拆分以后核心表大多是訪問頻率較高的字段,而且字段長度也都較短,因而可以加載更多數據到內存中,來增加查詢的命中率,減少磁盤IO,以此來提升數據庫性能。
垂直切分的優點:
- 業務間數據解耦,不同業務的數據進行獨立的維護、監控、擴展。
- 在高并發場景下,一定程度上緩解了數據庫的壓力。
垂直切分的缺點:
- 提升了開發的復雜度,由于業務的隔離性,很多表無法直接訪問,必須通過接口方式聚合數據。
- 分布式事務管理難度增加。
- 數據庫還是存在單表數據量過大的問題,并未根本上解決,需要配合水平切分。
水平切分
前邊說了垂直切分還是會存在單庫、表數據量過大的問題,當我們的應用已經無法在細粒度的垂直切分時, 依舊存在單庫讀寫、存儲性能瓶頸,這時就要配合水平切分一起了,水平切分能大幅提升數據庫性能。
1、水平分庫
水平分庫是把同一個表按一定規則拆分到不同的數據庫中,每個庫可以位于不同的服務器上,以此實現水平擴展,是一種常見的提升數據庫性能的方式。
這種方案往往能解決單庫存儲量及性能瓶頸問題,但由于同一個表被分配在不同的數據庫中,數據的訪問需要額外的路由工作,因此系統的復雜度也被提升了。
例如下圖,訂單DB_1、訂單DB_1、訂單DB_3 三個數據庫內有完全相同的表 order,我們在訪問某一筆訂單時可以通過對訂單的訂單編號取模的方式 訂單編號 mod 3 (數據庫實例數) ,指定該訂單應該在哪個數據庫中操作。
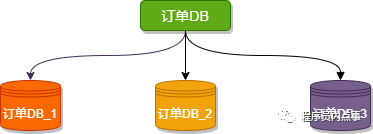
水平分庫
2、水平分表
水平分表是在同一個數據庫內,把一張大數據量的表按一定規則,切分成多個結構完全相同表,而每個表只存原表的一部分數據。
例如:一張 order 訂單表有 900萬數據,經過水平拆分出來三個表,order_1、order_2、order_3,每張表存有數據 300萬,以此類推。

水平分表
水平分表盡管拆分了表,但子表都還是在同一個數據庫實例中,只是解決了單一表數據量過大的問題,并沒有將拆分后的表分散到不同的機器上,還在競爭同一個物理機的CPU、內存、網絡IO等。要想進一步提升性能,就需要將拆分后的表分散到不同的數據庫中,達到分布式的效果。

分庫分表
水平切分的優點:
- 解決高并發時單庫數據量過大的問題,提升系統穩定性和負載能力。
- 業務系統改造的工作量不是很大。
水平切分的缺點:
- 跨分片的事務一致性難以保證。
- 跨庫的join關聯查詢性能較差。
- 擴容的難度和維護量較大,(拆分成幾千張子表想想都恐怖)。
一定規則是什么
我們上邊提到過很多次 一定規則 ,這個規則其實是一種路由算法,就是決定一條數據具體應該存在哪個數據庫的哪張表里。
常見的有 取模算法 和 范圍限定算法
1、取模算法
按字段取模(對hash結果取余數 (hash() mod N),N為數據庫實例數或子表數量)是最為常見的一種切分方式。
還拿 order 訂單表舉例,先對數據庫從 0 到 N-1進行編號,對 order 訂單表中work_no 訂單編號字段進行取模,得到余數 i,i=0存第一個庫,i=1存第二個庫,i=2存第三個庫....以此類推。
這樣同一筆訂單的數據都會存在同一個庫、表里,查詢時用相同的規則,用 work_no 訂單編號作為查詢條件,就能快速的定位到數據。
優點:
- 數據分片相對比較均勻,不易出現請求都打到一個庫上的情況。
缺點:
- 這種算法存在一些問題,當某一臺機器宕機,本應該落在該數據庫的請求就無法得到正確的處理,這時宕掉的實例會被踢出集群,此時算法變成hash(userId) mod N-1,用戶信息可能就不再在同一個庫中了。
2、范圍限定算法
按照 時間區間 或 ID區間 來切分,比如:我們切分的是用戶表,可以定義每個庫的User 表里只存10000條數據,第一個庫只存 userId 從1 ~ 9999的數據,第二個庫存 userId 為10000 ~ 20000,第三個庫存 userId 為 20001~ 30000......以此類推,按時間范圍也是同理。
優點:
- 單表數據量是可控的
- 水平擴展簡單只需增加節點即可,無需對其他分片的數據進行遷移
- 能快速定位要查詢的數據在哪個庫
缺點:
- 由于連續分片可能存在數據熱點,比如按時間字段分片,可能某一段時間內訂單驟增,可能會被頻繁的讀寫,而有些分片存儲的歷史數據,則很少被查詢。
分庫分表的難點
1、分布式事務
由于表分布在不同庫中,不可避免會帶來跨庫事務問題。一般可使用 "三階段提交 "和 "兩階段提交" 處理,但是這種方式性能較差,代碼開發量也比較大。通常做法是做到最終一致性的方案,如果不苛求系統的實時一致性,只要在允許的時間段內達到最終一致性即可,采用事務補償的方式。
這里我應用阿里的分布式事務框架Seata 來做分布式事務的管理,后邊會結合實際案例。
2、分頁、排序、跨庫聯合查詢
分頁、排序、聯合查詢是開發中使用頻率非常高的功能,但在分庫分表后,這些看似普通的操作卻是讓人非常頭疼的問題。將分散在不同庫中表的數據查詢出來,再將所有結果進行匯總整理后提供給用戶。
3、分布式主鍵
分庫分表后數據庫的自增主鍵意義就不大了,因為我們不能依靠單個數據庫實例上的自增主鍵來實現不同數據庫之間的全局唯一主鍵,此時一個能夠生成全局唯一ID的系統是非常必要的,那么這個全局唯一ID就叫 分布式ID。
4、讀寫分離
不難發現大部分主流的關系型數據庫都提供了主從架構的高可用方案,而我們需要實現 讀寫分離 + 分庫分表,讀庫與寫庫都要做分庫分表處理,后邊會有具體實戰案例。
5、數據脫敏
數據脫敏,是指對某些敏感信息通過脫敏規則進行數據轉換,從而實現敏感隱私數據的可靠保護,如身份證號、手機號、卡號、賬號密碼等個人信息,一般這些都需要進行做脫敏處理。
分庫分表工具
我還是那句話,盡量不要自己造輪子,因為自己造的輪子可能不那么圓,業界已經有了很多比較成熟的分庫分表中間件,我們根據自身的業務需求挑選,將更多的精力放在業務實現上。
- sharding-jdbc(當當)
- TSharding(蘑菇街)
- Atlas(奇虎360)
- Cobar(阿里巴巴)
- MyCAT(基于Cobar)
- Oceanus(58同城)
- Vitess(谷歌)
為什么選 sharding-jdbc
sharding-jdbc 是一款輕量級 Java 框架,以 jar 包形式提供服務,是屬于客戶端產品不需要額外部署,它相當于是個增強版的 JDBC 驅動;相比之下像 Mycat 這類需要單獨的部署服務的服務端產品,就稍顯復雜了。況且我想把更多精力放在實現業務,不想做額外的運維工作。
- sharding-jdbc的兼容性也非常強大,適用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate,Mybatis,Spring JDBC Template 或直接使用的JDBC。
- 完美兼容任何第三方的數據庫連接池,如:DBCP, C3P0, BoneCP,Druid, HikariCP 等,幾乎對所有關系型數據庫都支持。
不難發現確實是比較強大的一款工具,而且它對項目的侵入性很小,幾乎不用做任何代碼層的修改,也無需修改 SQL 語句,只需配置待分庫分表的數據表即可。
總結
簡單的回顧一下分庫分表的基礎知識,接下來的文章會配合實戰項目介紹 sharding-jdbc在分庫分表中的各個功能點。