關于分庫分表,一文講透!
作為一個后端開發,分庫分表絕對是需要掌握的技術點,這篇文章,我們一起來聊聊如何分庫分表?為什么要分庫分表?如何分庫分表?

一、什么是分庫分表?
1. 分庫
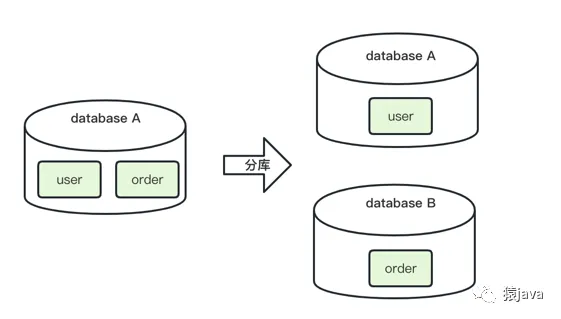
分庫是指在表數量不變的情況下對庫進行切分。
舉例:如下圖,數據庫 A 中存放了 user 和 order 兩張表,將兩張表切分到兩個數據庫中,user 表放到 database A,order 表放到 database B。
2. 分表
分表是指在庫數量不變的情況下對表進行切分。
舉例:如下圖,數據庫 A 中存放了 user 表,將 user 表切分成 user1 和 user2 兩張表并放到 database A 中。

3. 分庫分表
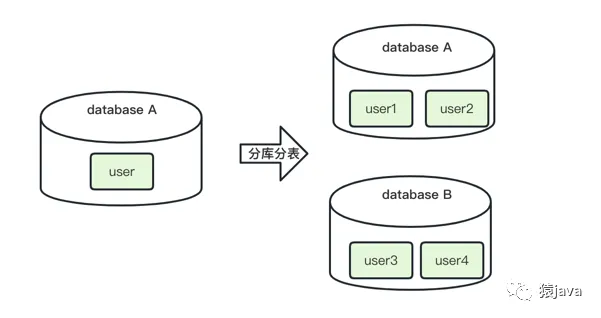
分庫分表是指庫和表都切分,數量都發生變化。
舉例:如下圖,數據庫 A 中存放了 user 表,將 user 表切分成 user1、user2、user3、user4 四張表,user1 和 user2 放到 database A 中,user3 和 user4 放到 database B 中。
二、如何切分庫和表?
主流的切分方式有 3 種:水平切分、垂直切分和混合切分。
1. 水平切分
水平切分包含水平分庫和水平分表。
(1) 水平分表
水平分表指的表結構不變,將單表數據切分成多表。切分后的結果:
- 每個表的結構一樣;
- 每個表的數據不一樣;
- 所有表的數據并集為全量數據;
切分抽象圖如下:

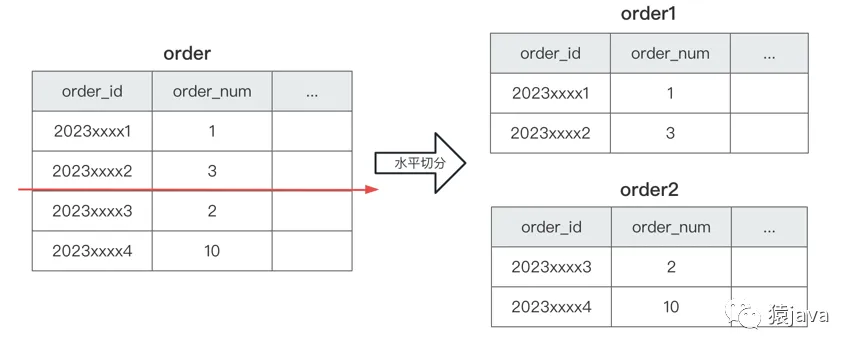
舉例:如下圖,order 表,按照 oder_id 的數據范圍水平切分后變成了 order1 和 order2 表,兩個表的結構一樣,數據不同。
(2) 水平分庫
水平分庫是指,將表水平切分后分到不同的數據庫,使得每個庫具有相同的表,表中的數據不相同,水平分庫一般是伴隨水平分表。
舉例:如下圖,order 表,水平切分后,分到 database A 和 database B 中,這樣原來一個庫就被拆分成 2 個庫。

2. 垂直切分
垂直切分包含垂直分庫和垂直分表。
(1) 垂直分表
垂直分表指將存在一張表中的字段切分到多張表。切分后的結果:
- 每個表的結構不一樣;
- 每個表的數據不一樣;
- 所有表的字段并集是原表的字段;
切分抽象圖如下:

舉例:如下圖,order 表,根據字段垂直切分,切分后 order_base 表包含一部分字段的數據 和 order_info 表包含另一部分字段的數據。

(2) 垂直分庫
垂直分庫指的是,將單個庫中的表分到多個庫,每個庫包含的表不一樣。
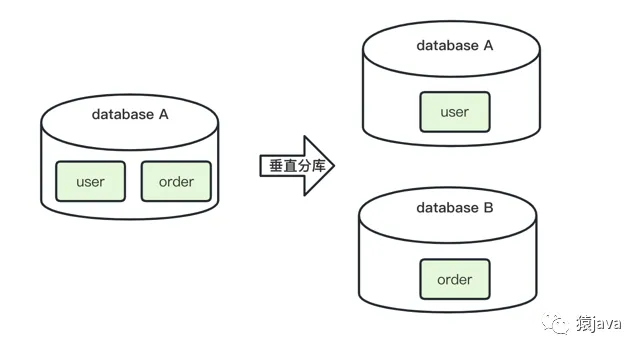
舉例:如下圖,database A 中的 order 表 和 user 表,垂直分庫為 database A 包含 order 表,database B 包含 user 表。
3. 混合切分
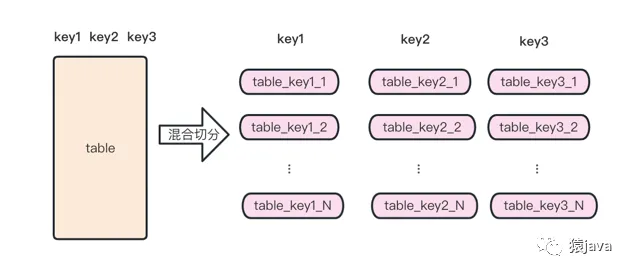
混合切分其實就是水平切分和垂直切分的組合,切分抽象圖如下:
舉例:如下圖,order 表,按照 oder_id 數據范圍做了水平切分,并且按照表字段做了垂直切分。

說明:上面的舉例只是為了更好地展示如何切分,并不包含真實業務內容。
三、為什么要分庫分表?
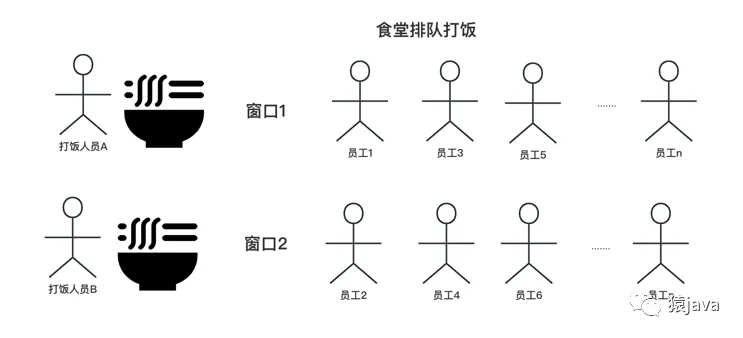
先看個"公司食堂打飯"生活實例,新公司剛開始員工人數比較少,一個窗口能夠應付員工的打飯需求,如下圖:

隨著公司業務的快速發展,公司員工快速增多,一個窗口難以應付員工的打飯需求,因此擴展成 2 個窗口,如下圖:
同理,對于數據庫來說,存在下面 4 種情況就需要考慮分庫分表:
1. 單庫出現性能瓶頸
單庫出現性能瓶頸,通常有以下幾種情況:
- 數據庫服務器磁盤空間不足,但是無法擴容,導致寫數據異常;
- 數據庫服務器 CPU 壓力過大,無法升配,導致讀寫性能較慢;
- 數據庫服務器內存不足,無法擴容,導致讀寫性能瓶頸;
- 數據庫服務器網絡帶寬不足,無法升配,導致讀寫性能瓶頸;
- 數據庫服務器連接數過多,無法升配,導致客戶端連接等待/超時;
如下圖,單庫已經達到了性能瓶頸,因此需要擴容成 2 個數據庫:
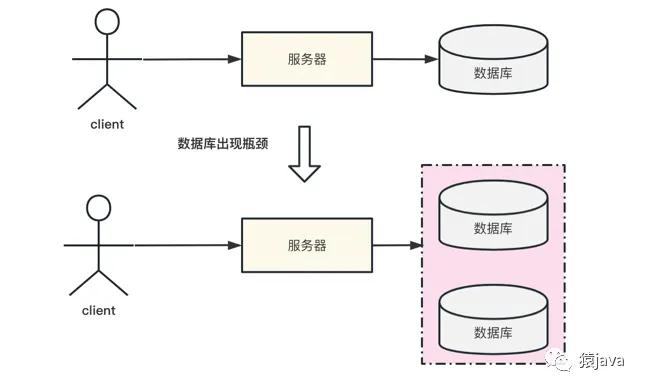
2. 單表出現性能瓶頸
單表出現性能瓶頸,通常是因為單表數據量過大,導致讀寫性能較慢。
如下圖,order 表已經達到了性能瓶頸,因此需要切分成 2 張表:

3. 微服務化
因公司架構發展,技術團隊需要對服務器進行微服務化,從而分庫分表。如下圖展示:

4. 技術調研
技術部門內部作為一項技術調研,通常會選一些重要性相對較低的業務去摸索和實踐,方便后期出現上面 3 種情況能夠有技術積累去快速支撐。
四、切分策略
主流的切分策略有 3 種:Range 范圍、hash 切分、映射表。
1. Range 范圍
Range 范圍是指按某個字段的數據區間來進行切分。
比如:user 表按照 user_id 的數據范圍切分成多張表,每 1000 萬條數據存放一張表,切分后的表可以放到同一個數據庫,也可以放到不同的數據庫,示例圖如下:
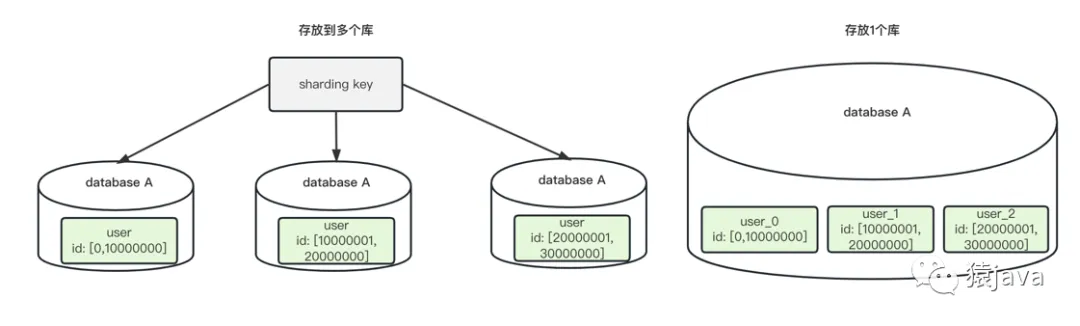
優點:方便擴容,每次數據量達到 range 值就新加一張表,可以通過代碼實現自動化擴容;
缺點:存在寫偏移,可能有熱點問題;
舉例:
比如用戶注冊場景:user 表,因為新注冊的用戶數據都是寫新表,通常來說新用戶的活躍度高,所以讀寫流量全部集中在最新的 user 表,因此,新表可能存在熱點問題。
2. hash 切分
通過對分表鍵 key 進行一定的運算(通常有取余、取模運算,比如:key % m,key / m,hash(key)/m 等等),通過運算結果來決定路由的庫和表。目前大多數互聯網公司主要采用該方法。
優點:數據分片比較均勻,大大降低熱點問題;
缺點:
- hash 算法選擇不合理,后期擴容可能需要遷移數據;
- 數據被切分到不同的庫和表中,可能存在跨節點查詢和分頁等問題;
舉例:
比如:user 表信息,根據 user_id 對 10 取余,這樣就可以通過 user_id 尾號 hash 到 user_0 到 user_9 10 張表中:
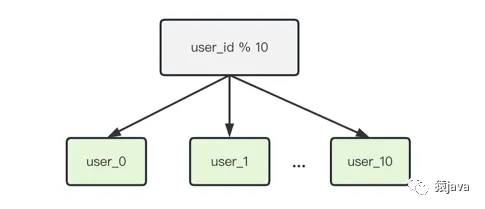
3. 映射表
映射表其實是 Range 范圍 和 hash 切分的混合模式,將分表鍵和數據庫的映射關系記錄在一個單獨的表(表的形式可以是 數據庫表,文件或者配置中心)。
優點:可以靈活設置路由規則;
缺點:
- 方案比較復雜;
- 映射表可能也會隨著業務量的增大,同樣需要分庫分表,帶來更多的問題;
舉例:
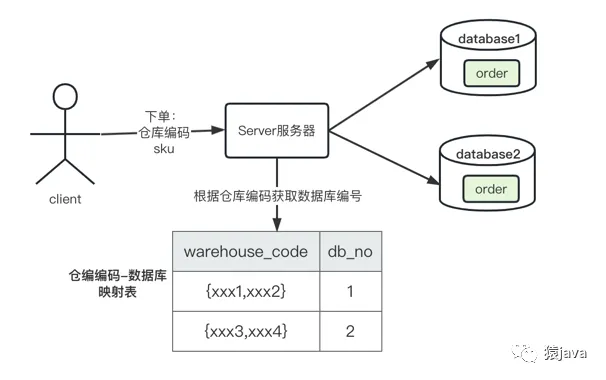
某社區電商下單場景,因為全國倉庫的數量有限,所以分庫直接使用了倉編編碼-數據庫映射表(后期新增加倉庫,只要在表中增加映射關系),為了保證履約的時效性,用戶下單時,商城端會選擇最近的倉庫,服務器在映射表中根據倉庫編碼查詢并路由到對應的數據庫,最后在庫中進行 order 表的操作,交互如下圖:
五、分庫分表產生的問題
分庫分表能夠解決性能瓶頸問題,但是分庫分表不是銀彈,它同樣也會帶來一些問題:
- 調試和維護難度
- 分布式事務
- 分布式事務
- 跨庫關聯/分頁/排序
1. 定位和維護難度
單庫單表,可以很直觀在表中查看數據,分庫分表后,需要先根據 key 找到庫和表,這樣在一定意義上增加了開發人員定位問題的難度,再因為庫和表的增多,維護難度自然也上去了(公司有 DBA 可以交給他們)。
2. 分布式 ID
單庫單表,可以直接使用表自增主鍵保證全局唯一性,分庫分表后,需要自己維護全局唯一的 ID,常用的算法有:UUID、號段模式(數據庫生成全局 ID)、雪花算法。
UUID 優點:性能非常高,本地生成,沒有網絡消耗;
UUID 缺點:
- 不易于存儲:UUID 太長,16 字節 128 位,通常以 36 長度的字符串表示,很多場景不適用;
- 信息不安全:基于 MAC 地址生成 UUID 的算法可能會造成 MAC 地址泄露,這個漏洞曾被用于尋找梅麗莎病毒的制作者位置;
- ID 作為主鍵時在特定的環境會存在一些問題,比如做 DB 主鍵的場景下,UUID 就非常不適用。
號段模式優點:
- 可以每次獲取一個 ID,也可以每次獲取一批 ID;
- 簡單,利用現有數據庫系統的功能實現;
- ID 單調自增,可以實現對 ID 要求特殊的業務;
號段模式缺點:
- 強依賴發號 DB 的性能,可能有單點問題;
雪花算法優點:
- 毫秒數在高位,自增序列在低位,整個 ID 都是趨勢遞增的。
- 不依賴數據庫等第三方系統,以服務的方式部署,穩定性更高,生成 ID 的性能也是非常高的。
- 可以根據自身業務特性分配 bit 位,非常靈活。
雪花算法缺點:
- 強依賴機器時鐘,如果機器時鐘回撥,會導致重復或者服務不可用,不過發生的概率比較小;
總結:
對于公司內部沒有分布式 ID 相關實現的,可以使用或借鑒 美團開源的 Leaf ( https://github.com/Meituan-Dianping/Leaf ) ,該框架提供了雪花算法和號段模式兩種方案。
3. 分布式事務
單庫單表可以直接使用本地事務來保障數據的正確性,分庫分表之后可能就需要引入分布式事務的問題,解決方案有兩種:
- 業務劃分的時候規避分布式事務;
- 使用專業的的分布式框架,比如阿里開源的 Seata ( https://seata.io/zh-cn/ );
4. 跨庫關聯/分頁/排序
單庫單表可以直接使用 MySQL limit 特性實現分頁,分庫分表后,可能會出現分頁問題,解決方案有三種:
- 選擇合適的分表字段,規避絕大部分高頻查詢場景出現跨庫;
- 使用專業的分布式框架,比如開源框架:ElasticSearch ( https://github.com/elastic/elasticsearch );
- 業務代碼中分別查詢,然后組裝數據;
六、分庫分表工具
分庫分表工具主要有 2 種模式:客戶端模式 和 代理模式
1. 客戶端模式
客戶端模式是指在客戶端實現直連數據庫,客戶端通常是通過一些封裝好的 jar 來實現,如下圖所示:
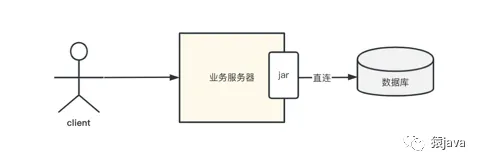
常見的開源中間件有:Apache 的 Sharding-JDBC、淘寶的 TDDL、美圖的 Zebra。
2. 代理模式
代理模式是指需要單獨部署服務,客戶端連接代理服務,由代理服務再和數據庫交互,如下圖所示:

常見的開源中間件有:Apache 的 Sharding-Proxy、阿里的 cobar、國產的 MyCat、360 的 Atlas。
另外還有 google 的 vitess,它是基于 zookeeper,通過 RPC 方式進行數據管理。
3. 總結
兩種方案的核心思想都是類似的,都是將分庫分表的邏輯進行抽象封裝,業務無需關注分庫分表的實現細節,只需按照規則進行簡單的配置和開發,就能正常的使用分庫分表。
兩者各有優劣,客戶端模式比較輕量,性能也會比較好;代理模式,客戶端無需維護服務,但是需要部署額外的代理服務器,代理服務器的穩定性和性能等都需要保障。
七、分庫分表如何落地?
敲黑板......重點,重點,重點,重要的事情說三遍!!!
互聯網業內有句經典名言"Talk is cheap.Show me your code",理論講再多,無法付諸實際生產都是空談。
這里以某大廠社區電商訂單業務的真實案例來分享如何落地分庫分表。
場景:社區電商下每日 3000 萬下單場景
評估庫和表的總數:
- 一般評估的標準是:當前日訂單峰值 M 支持最大的爆發增長速率 R 業務能支撐 Y 年發展 * 365 天/年,單表存儲 1000 萬數據按。
- 預估數據總數:日訂單 3000 萬,一年按 365 天計數,最大支持日訂單 10 倍的增長速度(即日訂單量 1 億),業務能支撐 10 年發展,因此,需要存儲的總訂單量 Total = 3000w 365 10 * 10 ≈ 10000 億,萬億級。
- 評估庫和表的總數:每張表按 1000 萬存儲(庫總數 表總數 = 10000 億 / 1000 萬),因此,庫總數 表總數 = 10 萬,組合方式有『1 個庫 10 萬張表、10 個庫 1 萬張表、100 個庫 1000 張表 等』,整體來看,"100 個庫 1000 張表"這種組合數據離散比較均勻,在計算機中,一般采用 2^n 來計數。所以,100 個庫 1000 張表可以比較接近 2^7 2^10 = 128 * 1024,所以最終 128 個庫,每個庫 1024 張表。
分庫分表字段的選擇:
在單庫單表中,可以直接進行 join 查詢和分頁操作,分庫分表后,數據會分到不同的數據庫和表上,可能會導致跨庫查詢等問題,因此,分表字段的選擇,決定了能否將原本需要進行分頁的數據劃分到同一張表上,從而避免跨庫查詢。
So,如何選擇分庫分表字段?
有用過社區電商產品(橙心優選,美團優選,多多買菜,盒馬鄰里)的小伙伴應該知道,社區電商的模式是:當日購買,次日履約。
為了保證履約的時效,用戶在下單時,商城端都是把訂單下到最近的倉庫,因此,可以根據倉庫編碼來分庫。
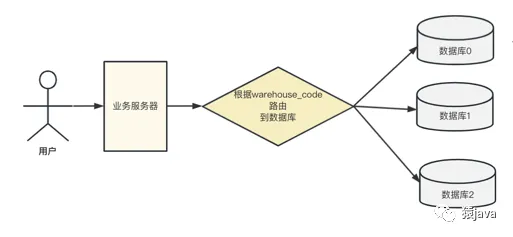
在整個銷售鏈路和履約鏈路中,有幾個高發的訂單查詢場景,因此分表字段的選擇必須滿足這些場景:
- 用戶視角:查詢自己所有的訂單,因此,可以通過 user_id 分表,把某用戶所有的訂單放到同一張表。
- 團長視角:查詢用戶下給自己的所有訂單,因此,可以通過 tuan_user_id 分表,把某團長的所有的訂單放到同一張表。
- 商家視角:查詢用戶下給自己的所有訂單,因此,可以通過 merchant_id 分表,把某商家的所有的訂單放到同一張表。
- 客服視角:通過訂單號查詢某個訂單,因此,通過 order_id 分表能夠快速查詢訂單信息。
上述 4 種場景都是訂單表高發查詢的場景,但是目前常用的分庫分表中間件都只能支持一個分表字段,該如何解決上面 4 種查詢問題呢?
通常的做法有:冗余數據和關系索引表。
其實在計算中的世界很多時候都是時間和空間的一個權衡問題,是拿時間換空間,還是拿空間換時間?冗余數據和關系索引表就很好的體現了時間和空間的權衡關系。
冗余數據:
相同的數據保存多份,每份數據使用不同的分表字段,從而滿足各種查詢需求。如下圖所示:通過 user_id、tuan_user_id、merchant_id、order_id 4 個字段來分表,因此需要冗余 4 份相同數據的 order 表。


很顯然,冗余數據是通過空間換時間的做法,優點是只要一次查詢請求就能滿足業務需求,缺點就是相同數據保存多份,浪費了空間,增加了成本。
淘寶的訂單表采用的是數據冗余,拆分買家庫和賣家庫兩個庫,一個訂單,在買家和賣家庫里都存儲了一份。
關系索引表:
它是指建立查詢條件和基表分表鍵的索引關系。如下圖,訂單表是基表,通過建立 user_id 和 order_id,tuan_user_id 和 order_id,merchant_id 和 order_id 的關系索引表來滿足幾種查詢場景:

很顯然,關系索引表是通過時間換空間的做法,優點是相對數據冗余法節省了空間和成本,缺點是多了一次索引表的查詢,因此時間相對就增加了。該方式額外增加的時間在高并發特別大的場景就能顯現出來。
因此,最后分庫分表模型是根據倉庫編碼 warehouse_code 來分庫,根據分表字段路由到 order 表,如下圖:

疑問:
疑問 1:上述案例的數據庫只能支撐 10 年,10 年以后的數據怎么存儲?
有過網購經驗的小伙伴應該都很少去查詢 3 年前的數據,因此,我們可以設置一個冷熱數據,比如按 3 年劃分,3 年內數據可以放到數據庫做熱數據,3 年前的數據可以歸檔到 ElasticSearch/hive,做冷數據查詢。
疑問 2:如何查詢某一時間段的訂單?
可以同步到 ElasticSearch/hive,這樣就可以很方便的按時間段來查詢。
疑問 3:上述案例是基于新業務,如果已經有線上服務和數據,該如何分庫分表?
這個場景是很多公司面臨的問題,因此這里給出一個切分的常用處理流程:
立項討論:
這個步驟需要完成和相關部門以及人員確認分庫分表事項、實施日程、后期周知、風險以及應對方案等事宜。
技術方案:
技術方案需要給出詳細遷移方案,包括分庫分表方案,代碼改造,服務器過渡到新庫新表方案,數據遷移方案,風險處理方案等。
代碼改造:
代碼改造,主要會涉及到幾個部分:服務如何過渡到新庫新表,如何靈活支持灰度讀寫操作,如何進行數據全量遷移、一致性校驗等任務。
分庫分表方案:
分庫分表方案需要確認分庫分表的字段,庫和表的數量等問題,可以參考上文 社區電商分庫分表落地方案。
數據同步:
數據同步有全量數據遷移、增量數據同步以及數據校驗、優化和補償。
- 數據全量遷移常用方案:開發代碼將老庫數據遷移到新庫;使用中間件同步工具(比如:阿里的 canal)將老庫數據同步到新庫。
- 增量數據同步常用方案:同步雙寫,在寫數據庫的地方修改成寫兩份數據;異步雙寫,寫老庫,監聽 binlog 異步同步到新庫;中間件同步:通過中間件(比如:阿里的 canal)將數據同步到目標庫表。
- 數據校驗常用方案:增量數據校驗 和 全量數據校驗 和 人工抽檢。
- 數據校驗核心流程:分別讀取老庫數據和新庫數據,然后比較,數據一致則繼續比較下一條數據,數據不一致則進行補償。
- 數據補償核心流程:新庫存在老庫不存在,則新庫刪除數據;新庫不存在老庫存在,則新庫插入數據;新庫存在老庫存在,則比較所有字段,不一致則將新庫更新為老庫數據。
風險處理方案:
風險處理包含部門間配合,技術方案的處理(服務回滾,數據修復等)
八、總結
首先,本文從分庫分表的理論到分庫分表的實例落地分享,但是百種業務百種架構,百種架構百種方案,本文可以給分庫分表一個很好的參考意義。
其次,數據分庫分表技術難度比較大,特別是從現有業務改造,需要考慮數據的遷移以及服務器平穩過渡到新庫新表,因此整個遷移過程都是一個很大的考驗。
最后,我們分享了一個分庫分表的常用流程,因為涉及點太多,所以只能給出一個業內常用的方案,很多細節點還需要在實施前充分去補充和完善。