面試必問:hashmap為什么會出現死循環?
jdk1.7 hashmap的循環依賴問題是面試經常被問到的問題,如何回答不好,可能會被扣分。今天我就帶大家一下梳理一下,這個問題是如何產生的,以及如何解決這個問題。
一、hashmap的數據結構
先一起看看jdk1.7 hashmap的數據結構
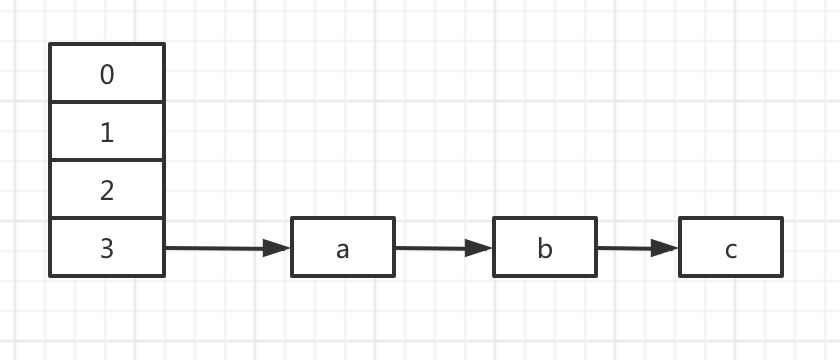
數組 + 鏈表
hashmap會給每個元素的key生成一個hash值,然后根據這個hash值計算一個在數組中的位置i。i不同的元素放在數組的不同位置,i相同的元素放在鏈表上,最新的數據放在鏈表的頭部。
往hashmap中保存元素會調用put方法,獲取元素會調用get方法。接下來,我們重點看看put方法。
二、put方法
重點看看put方法
- public V put(K key, V value) {
- if (table == EMPTY_TABLE) {
- inflateTable(threshold); } if (key == null)
- return putForNullKey(value);
- //根據key獲取hash
- int hash = hash(key); //計算在數組中的下表
- int i = indexFor(hash, table.length); //變量集合查詢相同key的數據,如果已經存在則更新數據
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value; e.value = value; e.recordAccess(this); //返回已有數據
- return oldValue;
- } } modCount++; //如果不存在相同key的元素,則添加新元素
- addEntry(hash, key, value, i); return null;
- }
再看看addEntry方法
- void addEntry(int hash, K key, V value, int bucketIndex) {
- // 當數組的size >= 擴容閾值,觸發擴容,size大小會在createEnty和removeEntry的時候改變 if ((size >= threshold) && (null != table[bucketIndex])) {
- // 擴容到2倍大小,后邊會跟進這個方法 resize(2 * table.length); // 擴容后重新計算hash和index
- hash = (null != key) ? hash(key) : 0;
- bucketIndex = indexFor(hash, table.length);
- } // 創建一個新的鏈表節點,點進去可以了解到是將新節點添加到了鏈表的頭部 createEntry(hash, key, value, bucketIndex);
- }
看看resize是如何擴容的
- void resize(int newCapacity) {
- Entry[] oldTable = table; int oldCapacity = oldTable.length;
- if (oldCapacity == MAXIMUM_CAPACITY) {
- threshold = Integer.MAX_VALUE; return;
- } // 創建2倍大小的新數組
- Entry[] newTable = new Entry[newCapacity];
- // 將舊數組的鏈表轉移到新數組,就是這個方法導致的hashMap不安全,等下我們進去看一眼
- transfer(newTable, initHashSeedAsNeeded(newCapacity));
- table = newTable;
- // 重新計算擴容閾值(容量*加載因子)
- threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
- }
出問題的就是這個transfer方法
- void transfer(Entry[] newTable, boolean rehash) {
- int newCapacity = newTable.length; // 遍歷舊數組
- for (Entry<K,V> e : table) {
- // 遍歷鏈表
- while(null != e) {
- //獲取下一個元素,記錄到一個臨時變量,以便后面使用
- Entry<K,V> next = e.next;
- if (rehash) {
- e.hash = null == e.key ? 0 : hash(e.key);
- } // 計算節點在新數組中的下標
- int i = indexFor(e.hash, newCapacity);
- // 將舊節點插入到新節點的頭部
- e.next = newTable[i];
- //這行才是真正把數據插入新數組中,前面那行代碼只是設置當前節點的next
- //這兩行代碼決定了倒序插入
- //比如:以前同一個位置上是:3,7,后面可能變成了:7、3
- newTable[i] = e;
- //將下一個元素賦值給當前元素,以便遍歷下一個元素
- e = next;
- }
- }
- }
我來給大家分析一下,為什么這幾個代碼是頭插法,網上很多技術文章都沒有說清楚。
三、頭插法
我們把目光聚焦到這幾行代碼:
- //獲取下一個元素,記錄到一個臨時變量,以便后面使用
- Entry<K,V> next = e.next;
- // 計算節點在新數組中的下標 int i = indexFor(e.hash, newCapacity); // 將舊節點插入到新節點的頭部 e.next = newTable[i];
- //這行才是真正把數據插入新數組中,前面那行代碼只是設置當前節點的next
- newTable[i] = e; //將下一個元素賦值給當前元素,以便遍歷下一個元素 e = next;
假設剛開始hashMap有這些數據
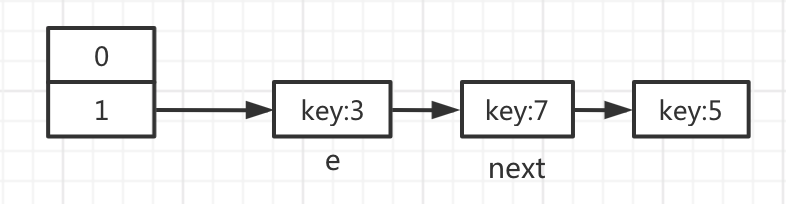
調用put方法需要進行一次擴容,剛開始會創建一個空的數組,大小是以前的2倍,如圖所示:
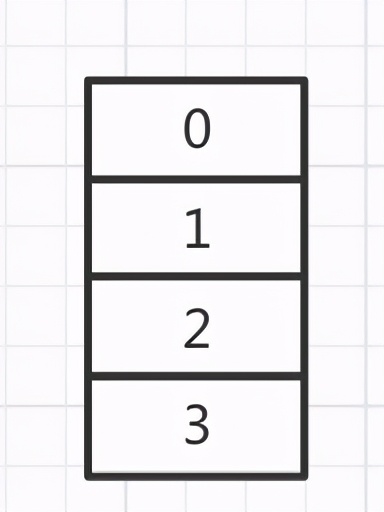
開始第一輪循環:
- //next= 7 e = 3 e.next = 7
- Entry<K,V> next = e.next;
- // i=3
- int i = indexFor(e.hash, newCapacity);//e.next = null ,剛初始化時新數組的元素為null
- e.next = newTable[i];
- //給新數組i位置 賦值 3
- newTable[i] = e;// e = 7
- e = next;
執行完之后,第一輪循環之后數據變成這樣的
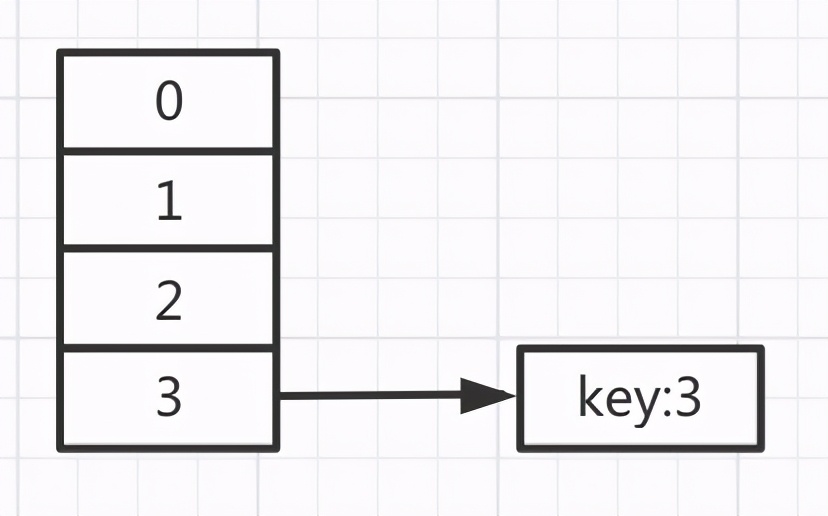
再接著開始第二輪循環:
- //next= 5 e = 7 e.next = 5
- Entry<K,V> next = e.next;
- // i=3
- int i = indexFor(e.hash, newCapacity);//e.next = 3 ,此時相同位置上已經有key=3的值了,將該值賦值給當前元素的next
- e.next = newTable[i];
- //給新數組i位置 賦值 7
- newTable[i] = e;// e = 5
- e = next;
上面會構成一個新鏈表,連接的順序正好反過來了。
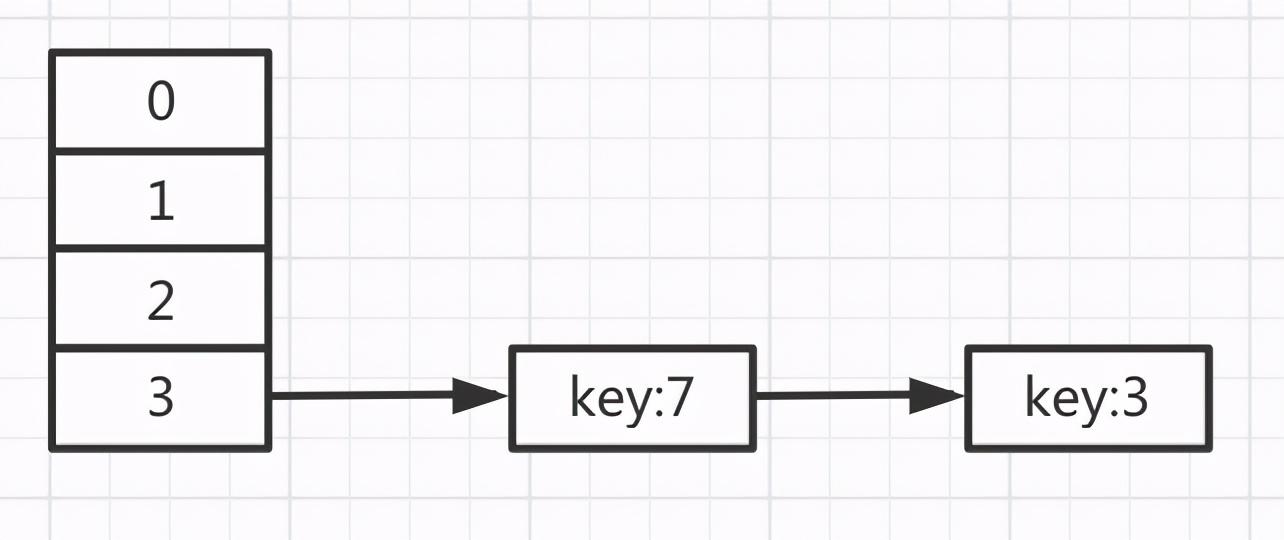
由于第二次循環時,節點key=7的元素插到相同位置上已有元素key=3的前面,所以說是采用的頭插法。
四、死循環的產生
接下來重點看看死循環是如何產生的?
假設數據跟元素數據一致,有兩個線程:線程1 和 線程2,同時執行put方法,最后同時調用transfer方法。
線程1 先執行,到 Entry next = e.next; 這一行,被掛起了。
- //next= 7 e = 3 e.next = 7
- Entry<K,V> next = e.next;
- int i = indexFor(e.hash, newCapacity);e.next = newTable[i];
- newTable[i] = e;e = next;
此時線程1 創建的數組會創建一個空數組
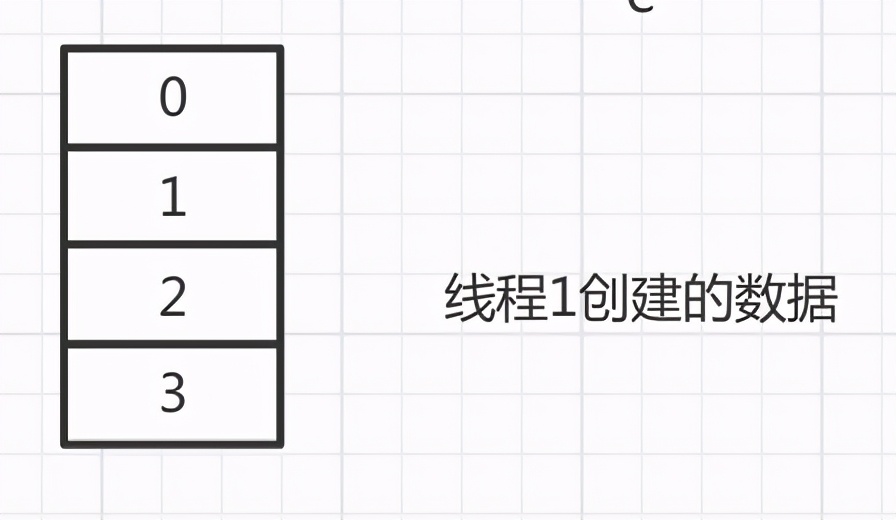
接下來,線程2開始執行,由于線程2運氣比較好,沒有被中斷過,執行完畢了。
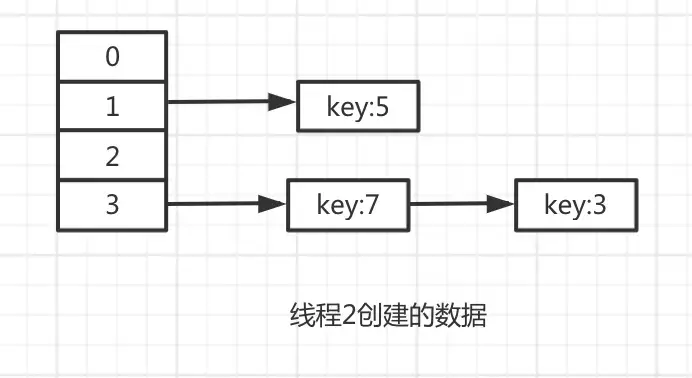
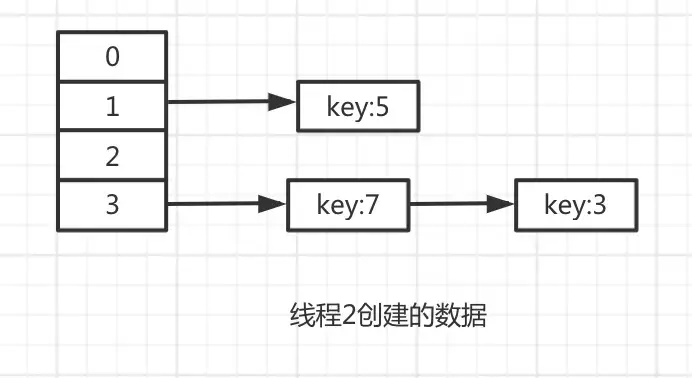
過一會兒,線程1被恢復了,重新執行代碼。
- //next= 7 e = 3 e.next = 7
- Entry<K,V> next = e.next;
- // i = 3
- int i = indexFor(e.hash, newCapacity);// e.next = null,剛初始化時新數組的元素為null
- e.next = newTable[i];
- // 給新數組i位置 賦值 3
- newTable[i] = e;// e = 7
- e = next;
這時候線程1的數組會變成這樣的
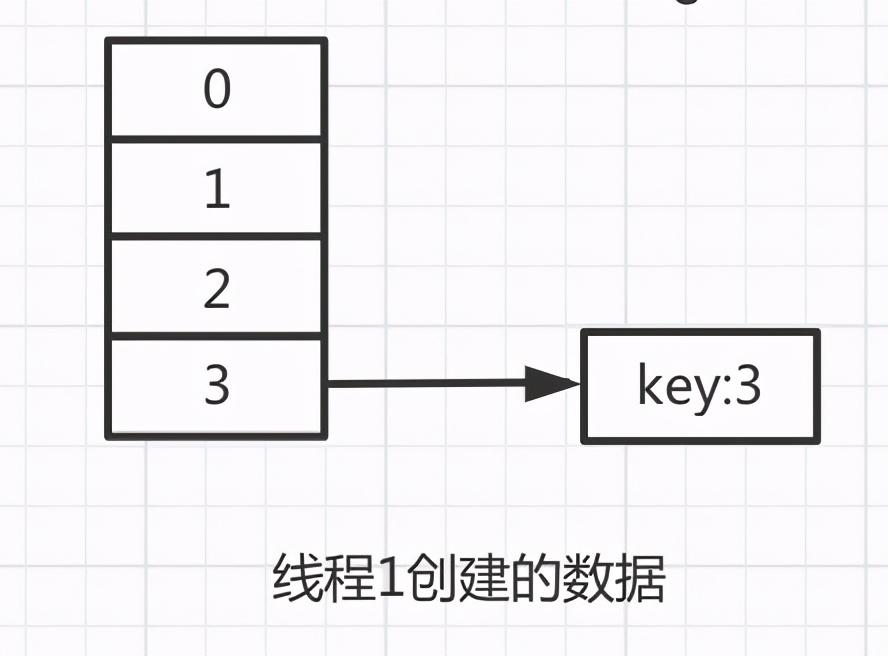
再執行第二輪循環,此時的e=7
- //next= 3 e = 7 e.next = 3
- Entry<K,V> next = e.next;
- // i = 3
- int i = indexFor(e.hash, newCapacity);// e.next = 3,此時相同位置上已經有key=3的值了,將該值賦值給當前元素的next
- e.next = newTable[i];
- // 給新數組i位置 賦值 7
- newTable[i] = e;// e = 3
- e = next;
這里特別要說明的是 此時e=7,而e.next為什么是3呢?
因為hashMap的數據是公共的,還記得線程2中的生成的數據嗎?
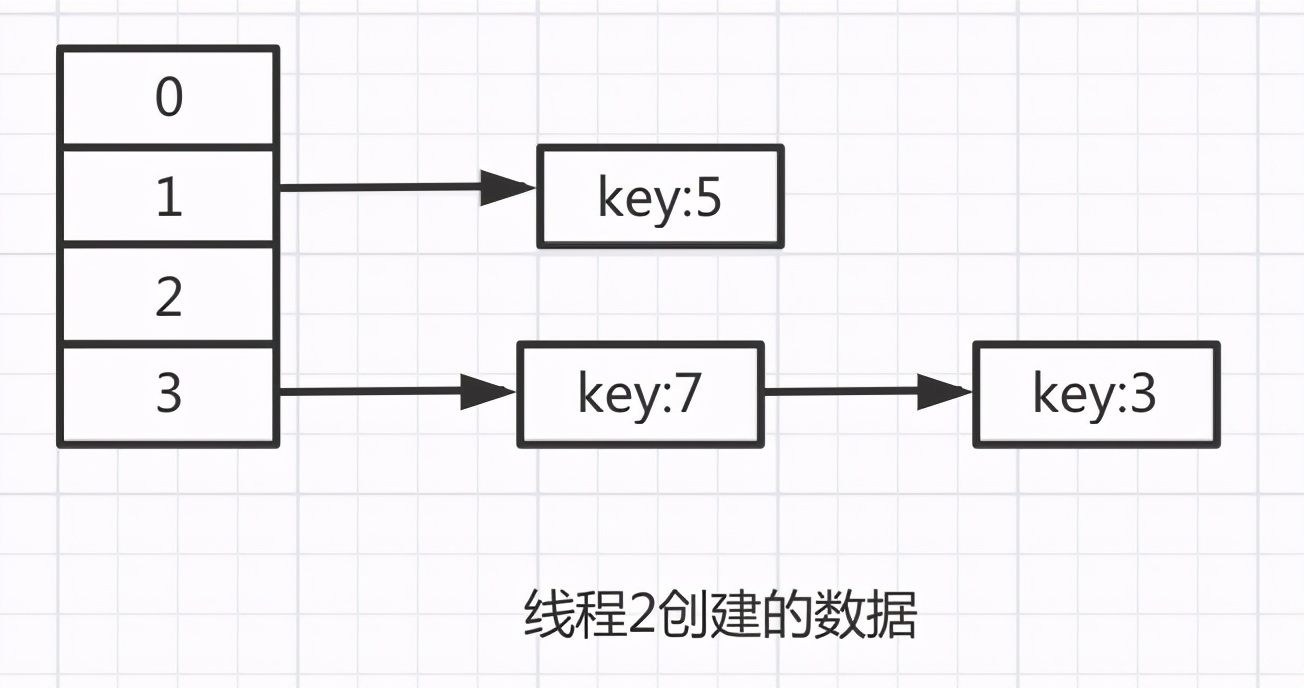
此時e=7,那么e.next肯定是3。
經過上面第二輪循環之后,線程1得到的數據如下:
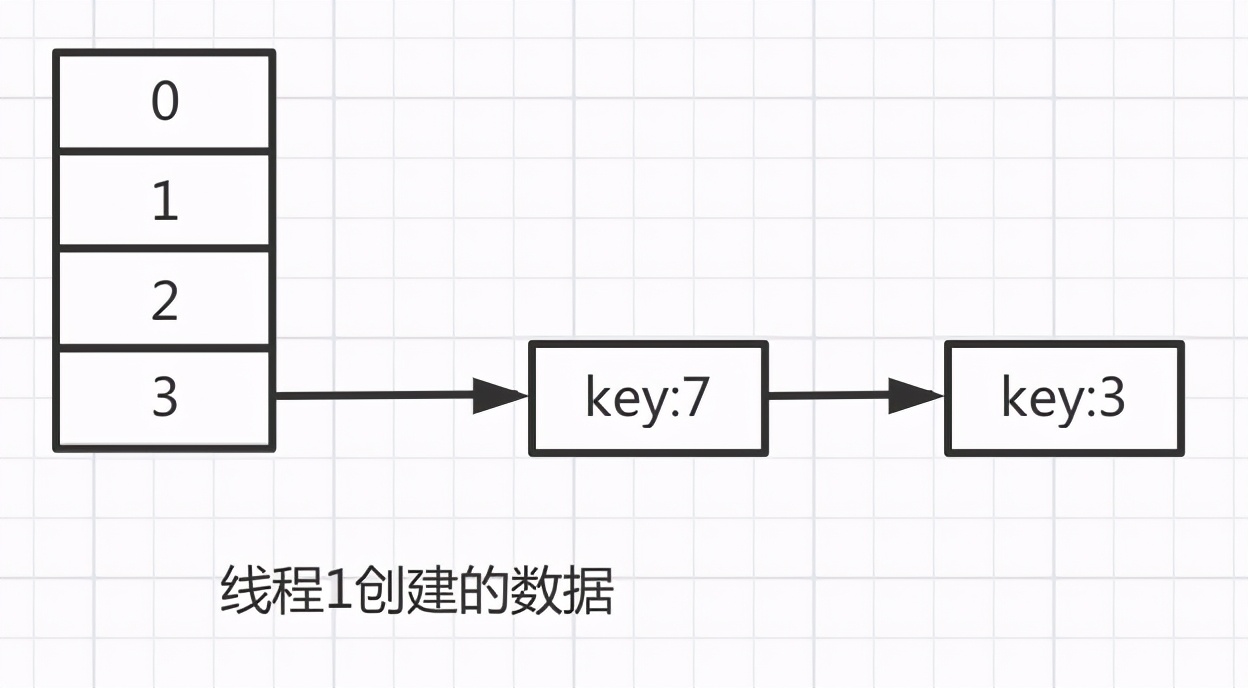
此時由于循環判斷還沒有退出,判斷條件是: while(null != e),所以要開始第三輪循環:
- //next= null e = 3 e.next = null
- Entry<K,V> next = e.next;
- // i = 3
- int i = indexFor(e.hash, newCapacity);// e.next = 7,關鍵的一步,由于第二次循環是 key:7 .next = key:3,現在key:3.next = key:7
- e.next = newTable[i];
- // 給新數組i位置 賦值 3
- newTable[i] = e;// e = nulle = next;
由于e=null,此時會退出循環,最終線程1的數據會是這種結構:
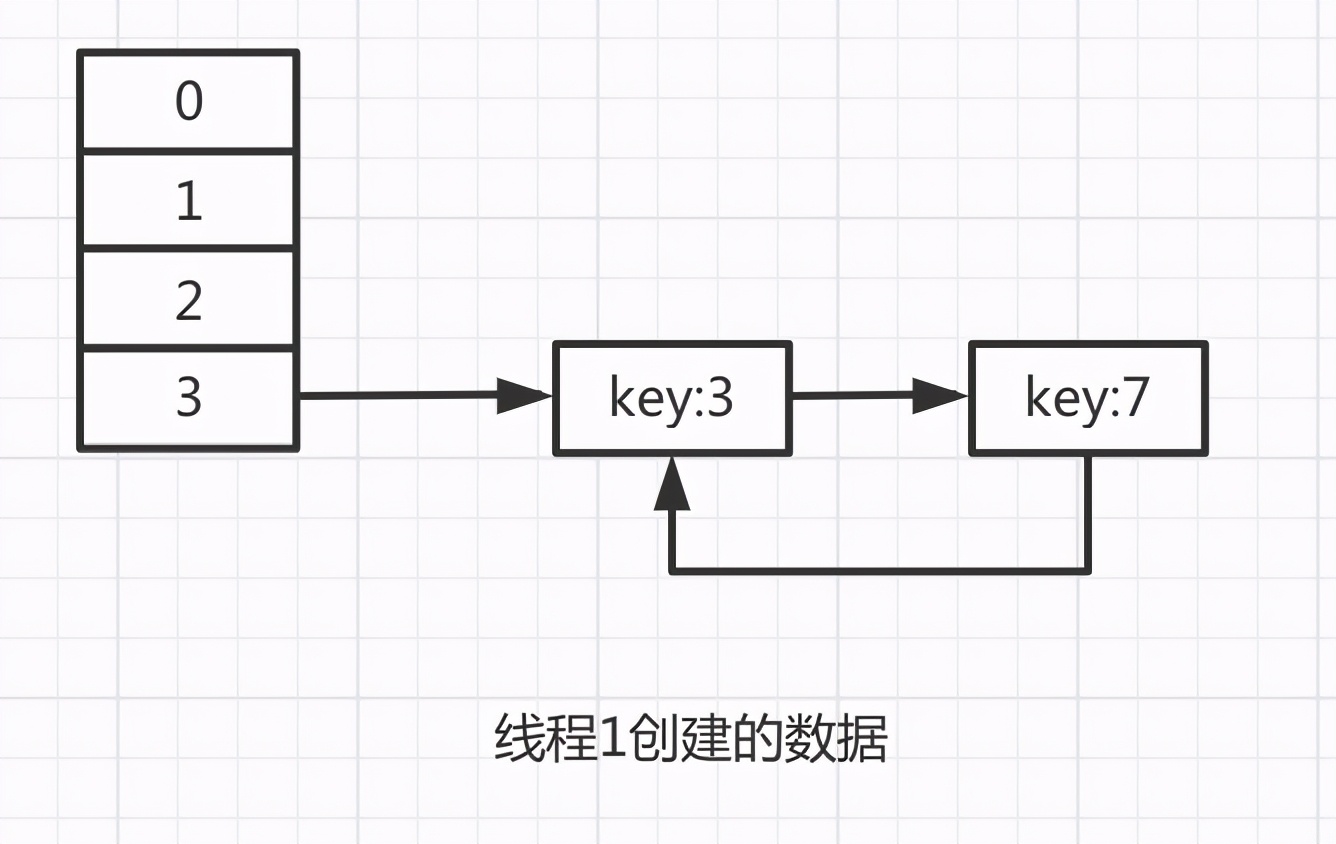
key:3 和 key:7又恢復了剛開始的順序,但是他們的next會相互引用,構成環形引用。
注意,此時調用hashmap的get方法獲取數據時,如果只是獲取循環鏈上key:3 和 key:7的數據,是不會有問題的,因為可以找到。就怕獲取循環鏈上沒有的數據,比如:key:11,key:15等,會進入無限循環中導致CPU使用率飆升。
五、如何避免死循環
為了解決這個問題,jdk1.8把擴容是復制元素到新數組由 頭插法 改成了 尾插法 。此外,引入了紅黑樹,提升遍歷節點的效率。在這里我就不過多介紹了,如果有興趣的朋友,可以關注我的公眾號,后面會給大家詳細分析jdk1.8的實現,以及 jdk1.7、jdk1.8 hashmap的區別。
此外,HashMap是非線程安全的,要避免在多線程的環境中使用HashMap,而應該改成使用ConcurrentHashMap。
所以總結一下要避免發生死循環的問題的方法:
- 改成ConcurrentHashMap
PS. 即使JDK升級到1.8任然有死循環的問題。