JDK bug?? HashMap中的死循環問題!
本文轉載自微信公眾號「石杉的架構筆記」,作者雨后晴天 。轉載本文請聯系石杉的架構筆記公眾號。
1、前言
HashMap 是 java工程師最常用的數據結構之一,但是能對其原理掌握的比較深的同學很少。尤其是本文的主題,據一些常年負責招 聘的朋友介紹。
HashMap 的死循環是面試中的常見問題,但是能講清楚的面試者很少,即使這些應聘者工作時間都比較長。
原因是,目前講解這個問題的文章雖多,但好文章卻不多。
也有些文章講解的很完善,但內容太過燒腦,所以看下來基本上都云里霧 里。鑒于目前的情況,本文基于我個人對源碼熟練掌握的基礎上,跳出源碼,因為那太燒腦,提煉出核心環節。盡量一步一圖,以大白話 形式將底層原理呈現出來。本文的理論基礎是基于 jdk1.8 以下版本。死循環問題也主要存在 于 jdk1.8 以下的版本中。
2、HashMap 的數據結構
jdk1.7 版本的HashMap,底層結構是一個數組,數組中的每項都可以是個鏈表,開始時我們用數組保存元素,當添加元素遇到沖突,即相同位置處有多個元素時,就將這些元素添加到對應的鏈表 中,所以 HashMap 的底層結構可以認為是由數組和鏈表構成。
如果,你在構建一個 HashMap 時不指定數組大小,那么默認情況下,數組大小為 16,但限于篇幅。
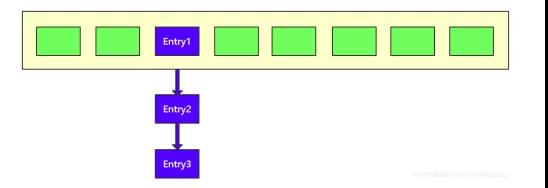
下面我們只畫了一個大小為 8 的 數組數組,在索引為 2 處有個鏈表,存放著 3 個元素,分別為 Entry1、Entry2、Entry3。這三個元素的 hash 運算結果是一樣的而 且都為 2,所以在數組的 index=2 構成了一條鏈表。
3、插入數據
在往 HashMap 中添加元素時,比如需要在上面的HashMap 中 添加一個節點 Entry4(k4,v4)。
首先會根據它的 key 值 k4 計算 hashcode 值,然后再對這個 hashcode 值做些復雜運算,得到在數組中的目標 index,比如為 4, 這時因為數組索引為 4 的位置為空,可直接將該元素插入到其底層數 組中。
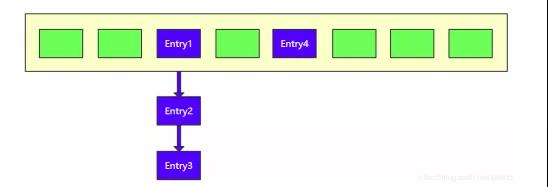
因為不同的 key 完全可能有相同的 hashcode 值,當然也完全可能在數組中有相同的目標 index。比如,要新添加一個元素 Entry5(k5,v5),對 k5 進行運算得到的目標 index 為4。
但是因為數組中對應位置已有一個元素 Entry4, 我們清楚一個數組的同一個索引處不可能連續存儲兩個元素而不被覆 蓋,所以這時會怎么處理呢?
這時鏈表就派上用場了,將這兩個元素在 index 為 4 處構成一個 鏈表即可以完美的解決沖突問題。
但是要注意,jdk1.7 采用的是頭插 法。就是將新節點 Entry5 放在數組中作為鏈表的頭節點,將原來的 Entry4 移出作為其 next 節點。如下圖所示:
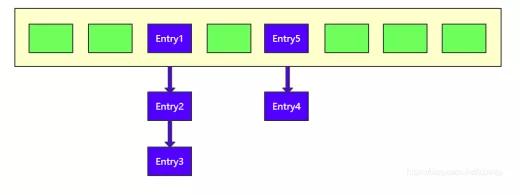
為何要一直強調是 jdk1.7 版本,因為在 jdk1.8 的時候 HashMap 結構發生了較大的變化,1.8 版本的 HashMap 采用的是尾插法而且底 層結構也發生了變化。
4、擴容
java 工程師都清楚 jdk1.7 版本的 HashMap初始默認長度為 16,你也可以自己定義,但不管你是自定義還是選擇默認長度,
隨著 元素的增加并達到了一定的閾值,總是要擴容的。擴容時是按 2 倍來進行的,就是創建一個 2 倍大小的數組,將原 來的元素重新 Hash,計算新的 index 放入到新的數組+鏈表結構中。
5、高并發下的擴容問題
HashMap 的這一結構和擴容機制可以保證,在大數據量情況 下,讀寫性能依然能保持優良。
插入時采用頭插法會非常快速,讀取 時,也不會因為鏈表過長而影響讀取性能。看到這,會不會覺得 Hash 是個完美的設計,其實不是,因為 HashMap 并不是線程安全的數據結構。
尤其是在擴容時,如果并發量不大通常不會有什么問題,但在高 并發情況下,擴容可能導致很嚴重的問題。我們下面來模擬一個高并發情況下擴容的例子。
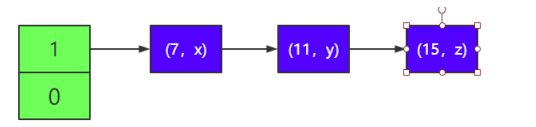
1)假設有一個 HashMap,它的負載因子為 1,有兩個元素(7,x)和 (11,y),它們 hash 運算的結果都為 1,所以都在 1 號鏈表(即 index 為 1 所指向的鏈表中,為便于描述,下面都簡稱)中,如下所 示。
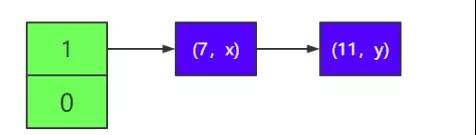
2)這時你需要往里面添加一個節點(15,z),這時有 3 個節點,因為 已達到擴容閾值,需要擴容。
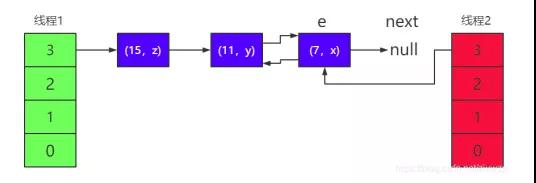
3)首先是線程 2 過來,按照擴容的底層源碼,需要將 e 指針指向鏈表 的頭節點(7,x),next 指針指向下一個節點(11,y),如下圖所 示:
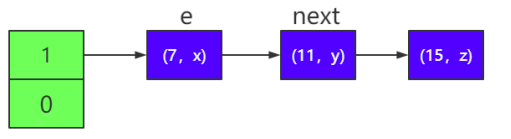
其中 e 表示當前線程正要遷移的節點,next 表示下一個需要遷移 的節點。如果 e 指向的節點遷移完成,則進入下一次循環,e 指針重新指 向節點(11,y),next 指針重新指向節點(15,z)。
4)但是當線程 2 剛開始標記好 e 和 next 兩個指針,正準備遷移第一 個節點時。線程 1 過來了,并完成了遷移。
5)前面我們說過,HashMap 進入鏈表是采用頭插法,所以對三個元 素 rehash 遷移后的鏈表順序為(15,z) —> (11,y) —> (7,x) 圖中的 e 和 next 指針屬于線程
2,它們還停留在原來的節點上, 這一階段的結構如下圖所示:
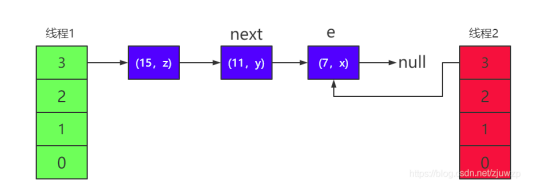
這時線程 2 中的 table 有(7,x)這個節點。
6)然后將 next 指向的節點(11, y)添加到線程 2 表示的 HashMap 中,因為采用頭插法,所以(11, y)成了鏈表的頭節點,原來的(7, x)則成了它的下一個節點
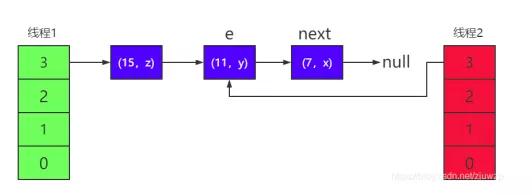
這時線程 2 中的 table 有(11,y)---->(7,x)這些節點,鏈 表的頭節點為(11,y)。
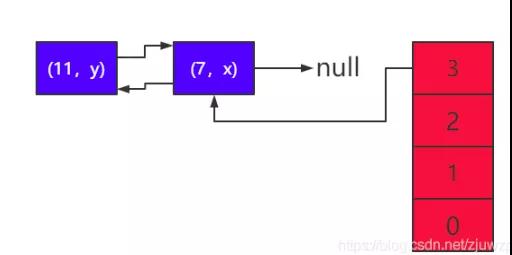
7)繼續循環遷移元素,將 e 指向(7,x),則 next 為 null。然后將 線程 2 的數組下標索引 3 指向 e 指向的節點,即將(7,x)又添加到 頭節點(頭插法),這時線程 2 中的 table 有(7,x)—>(11,y) ---->(7,x),構成了環,如圖所示:
6、問題很嚴重
如果上述的遷移過程最后以線程 2 的 table 作為新的 hashmap, 則最后的遷移結果如下圖所示:
7、環形鏈表會帶來什么后果呢?
假設我現在要查詢上述 HashMap 是否包含節點(7,x),首先根 據 hash 運算得到目標 index 為 3,所以查找目標轉到了 3 號鏈表,
然后根據 key 值為 11 判斷與鏈表的頭節點(7,x)的 key 恰好相等,再 判斷它們的 value 也相等。說明該 HashMap 中包含了我們所要查詢 的幾點,返回 true。
假設我現在要查詢節點(11,y),經過 hash 運算也將查找目標轉 到了 3 號鏈表,然后根據 key 值為 11 判斷與頭節點(7,x)的 key 不 相等,則轉向下一個節點。
通過對比,發現與下一個節點的 key 和 value 都相等,則直接返回 true。
這樣看來似乎沒什么問題,然后我們再查一個節點(15,m),經 過 hash 運算也將查找目標轉到了 3 號鏈表,首先與頭節點(7,x)判斷 不相等,然后與下一個節點(11,y)對比也不相等。再與下一個節點 判斷,這時鏈表中節點為(7,x)其實就是重新回到了頭節點,
它的下一 個節點又是(11,y),這種搜索會一直無限循環下去,CPU 很快飆 升到 100%,后果很嚴重。其實不管你搜索什么節點,只要路由到 3 號鏈表,并且待搜索的 key 不是 7 或 11,都將發生死循環。