













「機器學習架構」一個真實世界機器學習系統的架構
在「機器學習」機器學習(ML)開發平臺概述 ,我概述了ML開發平臺,它們的工作是幫助創建和打包ML模型。模型構建只是ML系統所需的眾多功能中的一項。在這篇文章的最后,我提到了其他類型的ML平臺以及構建現實世界ML系統時的限制。在我們能夠討論這些之前,我們需要回顧這些系統的所有組件,以及它們是如何相互連接的。
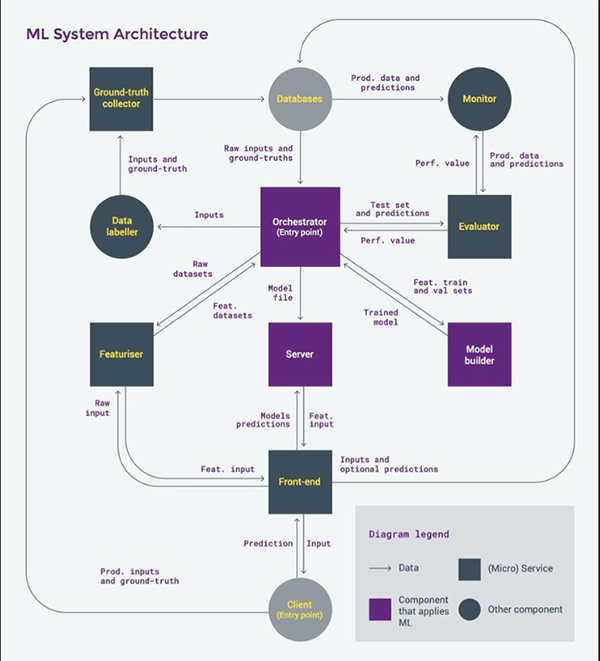
上面的圖表關注的是“監督學習”系統(例如分類和回歸)的客戶機-服務器架構,其中預測由客戶機請求,在服務器上進行。(旁注:在某些系統中,最好有客戶端預測;其他的甚至可能鼓勵客戶端模型培訓,但是在工業ML應用程序中使其高效的工具還不存在。)
ML系統組件的概述
在進一步研究之前,我建議下載上面的圖表,并分割屏幕,以便在閱讀本文其余部分的同時可以看到圖表。
讓我們假設“數據庫”在創建ML系統之前就已經存在了。深灰色和紫色的組件將是新的組件被建立。那些應用ML模型進行預測的用紫色表示。矩形用于表示有望提供微服務的組件,這些組件通常通過具象狀態傳輸(representational state transfer, REST) api訪問并在無服務器平臺上運行。
ML系統有兩個“入口點”:請求預測的客戶端和創建/更新模型的協調器。客戶端代表將從ML系統獲益的最終用戶使用的應用程序。這可以是你用來訂晚餐的智能手機應用程序,例如UberEats請求預定的交貨時間——這在COVID-19封鎖期間是一個大用例!
封鎖前的照片,維基百科提供。有一個復雜的ML系統可以預測這個家伙什么時候到達他的目的地,每天成千上萬次,在世界上數以百計的城市!希望這個系統使用的模型在過去幾周內得到了更新……
協調器通常是由調度程序調用的程序(以便模型可以定期更新,例如每周更新),或者通過API調用(以便它可以成為持續集成/持續交付管道的一部分)。它負責在一個保密的測試數據集上評估模型構建器創建的模型。為此,它將測試預測發送給求值器。如果一個模型被認為足夠好,那么它將被傳遞到模型服務器,通過API使其可用。這個API可以直接公開給客戶端軟件,但是通常需要在前端中實現特定于領域的邏輯。
假設有一個或多個(基線)模型可以作為api使用,但還沒有集成到最終的應用程序中,您將通過跟蹤生產數據的性能并通過監視器可視化來決定要集成哪個模型(以及它是否安全)。在我們的晚餐遞送示例中,它將讓您比較一個模型的ETD與剛剛交付的訂單的實際交貨時間。當新的模型版本可用時,客戶端對預測的請求將通過前端逐步定向到新模型的API。這將為越來越多的終端用戶完成,同時監視性能并檢查新模型是否“破壞”了任何東西。ML系統的所有者和客戶機應用程序的所有者將定期訪問監視器的儀表板。
讓我們以列表的形式重述一下上圖中的所有組件:
- 事實(Ground-truth)收集器
- 數據貼標機
- 評估者
- 性能監視器
- Featurizer(特征化器)
- 協調器
- 模型構建器
- 模型服務器
- 前端
我們已經簡單地提到了第3、4、6、7、8和9條。現在讓我們提供更多的信息,復習一下#1、# 2和# 5!
# 1:事實收集器
在現實世界中,關鍵是能夠不斷獲取新的數據供機器學習。有一種數據特別重要:地面真實數據。這與您希望ML模型預測的內容相對應,例如房地產的銷售價格、與客戶相關的事件(例如客戶流失)或分配給輸入對象的標簽(例如傳入消息中的“spam”)。有時候,你觀察一個輸入對象,你只需要等待一段時間來觀察你想預測的對象;例如,您等待房產被出售,等待客戶續訂或取消訂閱,等待用戶與收件箱中的電子郵件交互。您可能希望用戶在ML系統預測錯誤時讓您知道(參見下面的插圖)。如果您想讓您的用戶能夠提供這種反饋,您將需要一個微服務來將其發送到其中。

# 2:數據貼標機
有時,您可以訪問大量的輸入數據,但是您需要手動創建相關的ground-truth數據。構建垃圾郵件檢測器或從圖像構建對象檢測器時就是這樣。有現成的和開源的web應用來簡化數據標注(如Label Studio),也有專門的外包手工標注數據的服務(如圖8和谷歌的數據標注服務)。
飛機分類:標簽工作室在行動
# 3:評估者
當您有了供機器學習的初始數據集時,在開始構建任何ML模型之前,定義如何評估計劃的ML系統是很重要的。除了測量預測精度,還需要通過特定于應用程序的性能指標和系統指標(如延遲和吞吐量)來評估短期和長期的影響。
模型評估有兩個重要的目標:比較模型,以及決定將模型集成到應用程序中是否安全。評估可以在一組預先確定的測試用例上執行,因為它是已知的預測應該是什么(即基本事實)。可以檢查錯誤分布,并將錯誤聚合到性能指標中。為此,評估者需要訪問測試集的ground truth,這樣當它在輸入中得到預測時,它就可以計算預測錯誤并返回性能指標。
我建議在構建ML模型之前優先實現這個求值器。評估基線模型所作的預測,以提供參考。基線通常是基于輸入特征(也就是特性)的啟發式方法。它們可以是超級簡單的、手工制作的規則……
- 對于流失預測,你的基線可以說,如果一個客戶在過去30天內登錄少于3次,他們很可能會流失;
- 對于食物送餐時間的預測,你的基線可以是上周所點餐餐廳和乘客的平均送餐時間。
在明天開發復雜的ML模型之前,看看你的基線今天是否能創造價值!
# 4: 性能監視器
決定是否可以將(基線)模型集成到應用程序中的下一步是在生產中遇到的輸入(稱為“生產數據”)上使用它,在類似于生產的設置中,并通過時間監控它的性能。
計算和監控生產數據的性能指標需要在數據庫中獲取和存儲生產輸入、基本事實和預測。性能監視器將由一個從數據庫讀取數據、調用評估器的程序和一個顯示性能指標如何隨時間發展的儀表板組成。一般來說,我們希望檢查模型是否隨時間運行良好,以及它們是否持續對集成它們的應用程序產生積極影響。還可以使用顯示生產數據分布的數據可視化小部件對監視器進行增強,這樣我們就可以確保它們符合預期,或者我們可以監視漂移和異常情況。
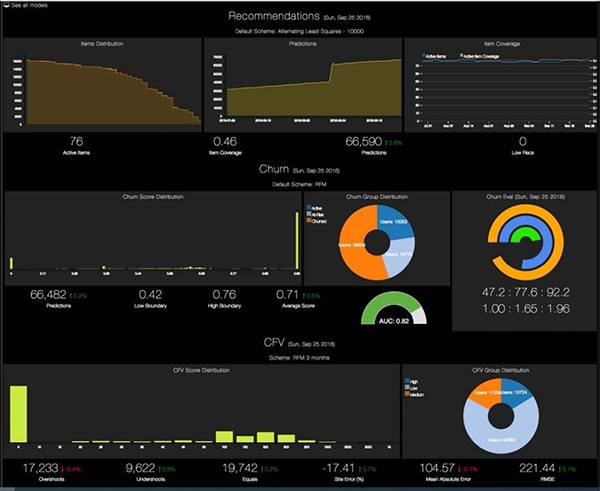
攪和模型的監視儀表板(源)
# 5: FEATURIZER(特征化機器)
在設計預測API時,需要決定API應該采用什么作為輸入。例如,在對客戶進行預測時,輸入應該是客戶的全部特性表示,還是僅僅是客戶id?
在任何情況下,完整的數字表示都是很常見的(就像文本或圖像輸入一樣),但是在傳遞給模型之前必須對其進行計算。對于客戶輸入,有些特性已經存儲在數據庫中(例如,出生日期),而其他特性則需要進行計算。這可能是描述客戶在某段時間內如何與產品交互的行為特性的情況:它們將通過查詢和聚合記錄客戶與產品交互的數據來計算。
如果特性本質上不經常變化,則可以批量計算它們。但在ML用例中,比如UberEats的預期交付時間,我們可能會有快速變化的“熱點”特性,需要實時計算;例如,某家餐廳在過去X分鐘內的平均送餐時間。
這需要創建至少一個特性化微服務,它將根據輸入的id為一批輸入提取特性。您可能還需要一個實時的特性化微服務,但是這會增加ML系統的復雜性。
功能分析器可以查詢各種數據庫,并對查詢的數據執行各種聚合和處理。它們可能具有參數(如上面示例中的分鐘數X),這些參數可能會對模型的性能產生影響。
# 6 協調器
工作流
協調器位于ML系統的核心,并與許多其他組件交互。下面是它的工作流/管道中的步驟:
- 提取-轉換-加載和分割(原始)數據到訓練,驗證,測試集
- 發送功能飽和化的培訓/驗證/測試集(如果有的話)
- 準備專用的訓練/驗證/測試集
- 將準備好的訓練/驗證集的uri以及要優化的指標發送到模型構建器
- 得到最優模型,應用于測試集,并將預測發送給評估者
- 獲取性能值并決定是否可以將模型推到服務器(例如,用于對生產數據的卡納塔測試)。
關于步驟3(“準備專用培訓/驗證/測試集”)的更多細節:
- 增強訓練數據(例如,過采樣/過采樣,或旋轉/翻轉/裁剪圖像)
- 預處理訓練/驗證/測試集,包括數據消毒(以便可以安全地用于建模或預測)和針對特定問題的準備(例如,圖像去飽和和調整大小)。
運行工作流的方法
整個工作流可以手動執行,但是要頻繁地更新模型,或者聯合調優建模器和建模器的超參數,就必須實現自動化。這個工作流可以實現為一個簡單的腳本并在單個線程上運行,但是通過并行運行可以提高計算效率。端到端ML平臺允許這樣做,并且可以提供一個環境來定義和運行完整的ML管道。與谷歌AI平臺,例如,你可以使用谷歌云數據產品,如Dataprep (Trifacta爭吵工具提供的數據),數據流(一個簡化的流和批量數據處理工具),BigQuery (serverless云數據倉庫),您可以定義一個培訓應用程序基于TensorFlow或內置算法(例如XGBoost)。在處理重要的數據量時,Spark是一個流行的選擇。Spark背后的Databricks公司也提供端到端平臺。
或者,工作流的每一步都可以在不同的平臺或不同的計算環境中運行。一種選擇是在不同的Docker容器中執行這些步驟。Kubernetes是ML從業者中最流行的開源容器編排系統之一。Kubeflow和Seldon Core是開源工具,允許用戶描述ML管道并將其轉換為Kubernetes集群應用程序。這可以在本地環境中完成,并且應用程序可以運行在Kubernetes集群上,該集群可以安裝在本地,也可以在云平臺中提供——例如谷歌Kubernetes引擎,它被谷歌AI平臺或Azure Kubernetes服務或Amazon EKS使用。Amazon還提供了一種與Kubernetes相對應的Fargate和ECS。Apache氣流是另一個開源工作流管理工具,最初由Airbnb開發。氣流已經成為協調一般IT任務(包括ML任務)執行的流行方式,它還與Kubernetes集成。
為更高級的工作流程的主動學習
正如前面所暗示的,可能需要領域專家訪問一個數據標簽器,在那里他們將被顯示輸入并被要求標記它們。這些標簽將存儲在數據庫中,然后編配人員可以在培訓/驗證/測試數據中使用這些標簽。提供標記的輸入可以手動選擇,也可以在協調器中進行編程。這可以通過觀察模型正確但不確定的生產投入,或非常確定但不確定的生產投入——這是“主動學習”的基礎。
# 7 模型構建器
模型構建器負責提供一個最佳的模型。為此,它在訓練集上訓練各種模型,并在驗證集上評估它們,使用給定的度量,以評估最優性。注意,這與上一篇文章中探討的OptiML示例相同:
$ curl https://bigml.io/optiml?$BIGML_AUTH -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'
BigML通過它的API自動使模型可用,但是對于其他ML開發平臺,您可能希望打包模型,將其保存為文件,并讓您的模型服務器加載該文件。
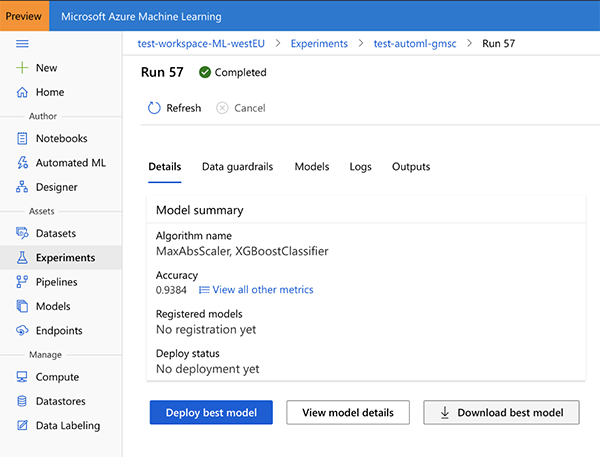
在Azure ML上進行的“自動化ML”實驗的結果。您可以下載找到的最佳模型,或者在Azure上部署它。
如果您使用不同的ML開發平臺,或者根本不使用平臺,那么以一種由專用服務自動創建模型的方式來構建您的系統是值得的,該服務需要對訓練集、驗證集和性能度量進行優化。
# 8 模型服務器
模型服務器的角色是處理針對給定模型的預測的API請求。為此,它加載保存在文件中的模型表示,并通過模型解釋器將其應用到API請求中的輸入;然后在API響應中返回預測。服務器應該允許并行處理多個API請求和模型更新。
下面是一個情緒分析模型的請求和響應示例,它只接受一個文本特性作為輸入:
$ curl https://mydomain.com/sentiment-H 'X-ApiKey: MY_API_KEY'-d '{"input": "I love this series of articles on ML platforms"}'{"prediction": 0.90827194878055087}
存在不同的模型表示,如ONNX和PMML。另一個標準實踐是將模型作為計算環境中的對象保存在文件中。這還需要保存計算環境的表示,特別是它的依賴關系,這樣就可以再次創建模型對象。在這種情況下,模型“解釋器”僅僅由像model.predict(new_input)這樣的東西組成。
# 9 前端
前端可以服務多種用途:
- 簡化模型的輸出,例如將一個類概率列表轉換為最可能的類;
- 添加到模型的輸出中,例如使用黑盒模型解釋器并提供預測解釋(與Indico的方法相同);
- 實現特定領域的邏輯,例如基于預測的決策,或接收到異常輸入時的回退;
- 發送生產輸入和模型預測,以便存儲在生產數據庫中;
- 測試新模型,通過查詢預測(除了“實時”模型之外)并存儲它們;這將允許監視器為這些新的候選模型繪制性能指標。
模型生命周期管理
如果一個新的候選模型在測試數據集中提供了比當前模型更好的性能,那么通過讓前端返回這個模型對一小部分應用程序的最終用戶的預測(金絲雀測試),就可以測試它對應用程序的實際影響。這要求評估者和監控器實現特定于應用程序的性能指標。測試用戶可以從列表中選取,也可以通過他們的某個屬性、地理位置選擇,或者完全隨機選擇。在監視性能并確信新模型不會破壞任何東西時,開發人員可以逐步增加測試用戶的比例,并執行A/B測試,進一步比較新模型和舊模型。如果新模型被證實更好,前端就會通過總是返回新模型的預測來“取代”舊模型。如果新模型最終破壞了系統,也可以通過前端實現回滾。
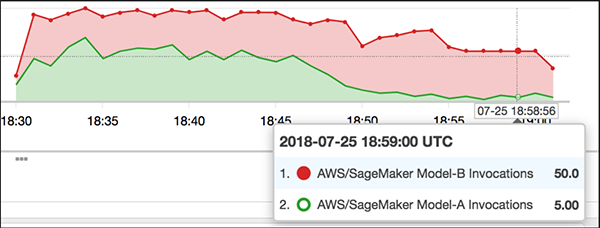
逐步將流量導向模型B,逐步淘汰模型A(來源)
結論
如果您對真實的ML感到好奇,那么我希望本文能夠幫助您說明為什么ML開發平臺和模型構建通常不足以創建對最終用戶有實際影響的系統。


















