計算機架構的機器學習
最近機器學習 (ML) 進步的關鍵貢獻者之一是定制加速器的開發,例如Google TPU和Edge TPU,它們顯著提高了可用計算能力,從而解鎖了各種功能,例如AlphaGo、RankBrain、WaveNets和對話代理。這種增加可以提高神經網絡訓練和推理的性能,為視覺、語言、理解和自動駕駛汽車等廣泛的應用提供新的可能性。
為了保持這些進步,硬件加速器生態系統必須繼續在架構設計方面進行創新,并適應快速發展的 ML 模型和應用程序。這需要對許多不同的加速器設計點進行評估,每個點不僅可以提高計算能力,還可以揭示新的能力。這些設計點通常由各種硬件和軟件因素(例如,內存容量、不同級別的計算單元數量、并行性、互連網絡、流水線、軟件映射等)參數化。這是一項艱巨的優化任務,因為搜索空間呈指數級大1 而目標函數(例如,更低的延遲和/或更高的能源效率)通過模擬或綜合進行評估在計算上是昂貴的,這使得確定可行的加速器配置具有挑戰性。
在“ Apollo: Transferable Architecture Exploration ”中,我們介紹了我們在定制加速器的 ML 驅動設計方面的研究進展。雖然最近的 工作已經證明了利用 ML 來改進低級布局規劃過程(其中硬件組件在空間上布局并在硅中連接)方面的有希望的結果,但在這項工作中,我們專注于將 ML 混合到高級系統規范和架構設計階段,這是影響芯片整體性能的關鍵因素,其中建立了控制高級功能的設計元素。我們的研究展示了 ML 算法如何促進架構探索并建議跨一系列深度神經網絡的高性能架構,其領域涵蓋圖像分類、對象檢測、OCR和語義分割。
架構搜索空間和工作負載
架構探索的目標是為一組工作負載發現一組可行的加速器參數,以便在一組可選的用戶定義下最小化所需的目標函數(例如,運行時的加權平均值)約束。然而,體系結構搜索的流形通常包含許多點,從軟件到硬件沒有可行的映射。其中一些設計點是先驗已知的,可以通過用戶將它們制定為優化約束來繞過(例如,在面積預算2約束,總內存大小不得超過預定義的限制)。然而,由于體系結構和編譯器的相互作用以及搜索空間的復雜性,一些約束可能無法正確地表述到優化中,因此編譯器可能無法為目標硬件找到可行的軟件映射。這些不可行點在優化問題中不容易表述,并且在整個編譯器通過之前通常是未知的。因此,架構探索的主要挑戰之一是有效地避開不可行的點,以最少數量的周期精確架構模擬來有效探索搜索空間。
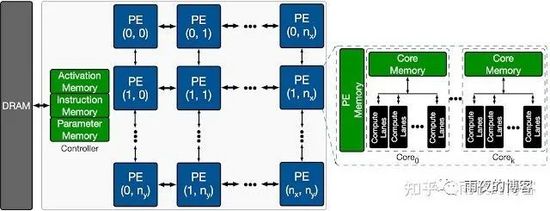
下圖顯示了目標 ML 加速器的整體架構搜索空間。加速器包含處理元件 (PE) 的二維陣列,每個處理元件以單指令多數據(SIMD) 方式執行一組算術計算。每個 PE 的主要架構組件是處理核心,包括用于 SIMD 操作的多個計算通道。每個 PE在其所有計算核心之間具有共享內存 ( PE Memory ),主要用于存儲模型激活、部分結果和輸出,而單個核心具有主要用于存儲模型參數的內存。每個內核有多個計算通道,具有多路乘法累加(MAC) 單位。每個周期的模型計算結果要么存儲在 PE 內存中以供進一步計算,要么卸載回 DRAM。
優化策略
在本研究中,我們在架構探索的背景下探索了四種優化策略:
1.隨機:隨機均勻地對架構搜索空間進行采樣。
2.Vizier:使用貝葉斯優化在搜索空間中進行探索,其中目標函數的評估成本很高(例如硬件模擬,可能需要數小時才能完成)。使用來自搜索空間的一組采樣點,貝葉斯優化形成一個代理函數,通常用高斯過程表示,它近似于搜索空間的流形。在代理函數值的指導下,貝葉斯優化算法在探索和開發的權衡中決定是從流形中的有希望的區域中采樣更多(開發),還是從搜索空間中不可見的區域中采樣更多(勘探)。然后,優化算法使用這些新采樣點并進一步更新代理函數以更好地對目標搜索空間進行建模。Vizier 將預期改進作為其核心獲取功能。在這里,我們使用Vizier (safe),這是一種約束優化的變體,它指導優化過程避免建議不滿足給定約束的試驗。
3.Evolutionary:使用k 個個體的種群 執行進化搜索,其中每個個體的基因組對應于一系列離散化的加速器配置。通過使用錦標賽選擇從種群中為每個個體選擇兩個父母,以某種交叉率重組他們的基因組,并以某種概率突變重組的基因組,從而產生新個體。
4.基于種群的黑盒優化(P3BO):使用一組優化方法,包括進化和基于模型,已被證明可以提高樣本效率和穩健性。采樣數據在集成中的優化方法之間交換,優化器根據其性能歷史進行加權以生成新的配置。在我們的研究中,我們使用 P3BO 的變體,其中優化器的超參數使用進化搜索動態更新。
加速器搜索空間嵌入
為了更好地可視化每個優化策略在加速器搜索空間導航中的有效性,我們使用t 分布隨機鄰居嵌入 (t-SNE) 將探索的配置映射到優化范圍內的二維空間。所有實驗的目標(獎勵)定義為每個加速器區域的吞吐量(推理/秒)。在下圖中,x軸和y軸表示嵌入空間的 t-SNE 組件(嵌入 1 和嵌入 2)。星形和圓形標記分別顯示不可行(零獎勵)和可行設計點,可行點的大小與其獎勵相對應。
正如預期的那樣,隨機策略以均勻分布的方式搜索空間,最終在設計空間中找到很少的可行點。
與隨機抽樣方法相比,Vizier默認優化策略在探索搜索空間和找到具有更高獎勵的設計點(1.14 對 0.96)之間取得了很好的平衡。然而,這種方法往往會陷入不可行的區域,雖然它確實找到了一些具有最大回報的點(由紅十字標記表示),但它在最后一次探索迭代中幾乎找不到可行的點。
另一方面,進化優化策略在優化的早期找到可行的解決方案,并在它們周圍組裝可行點的集群。因此,這種方法主要導航可行區域(綠色圓圈)并有效地避開不可行點。此外,進化搜索能夠找到更多具有最大獎勵(紅色十字)的設計選項。具有高回報的解決方案的這種多樣性為設計師探索具有不同設計權衡的各種架構提供了靈活性。
最后,基于群體的優化方法 (P3BO) 以更有針對性的方式(具有高獎勵點的區域)探索設計空間,以找到最佳解決方案。P3BO 策略在具有更嚴格約束(例如,大量不可行點)的搜索空間中找到具有最高獎勵的設計點,顯示其在具有大量不可行點的搜索空間中導航的有效性。
不同設計約束下的架構探索
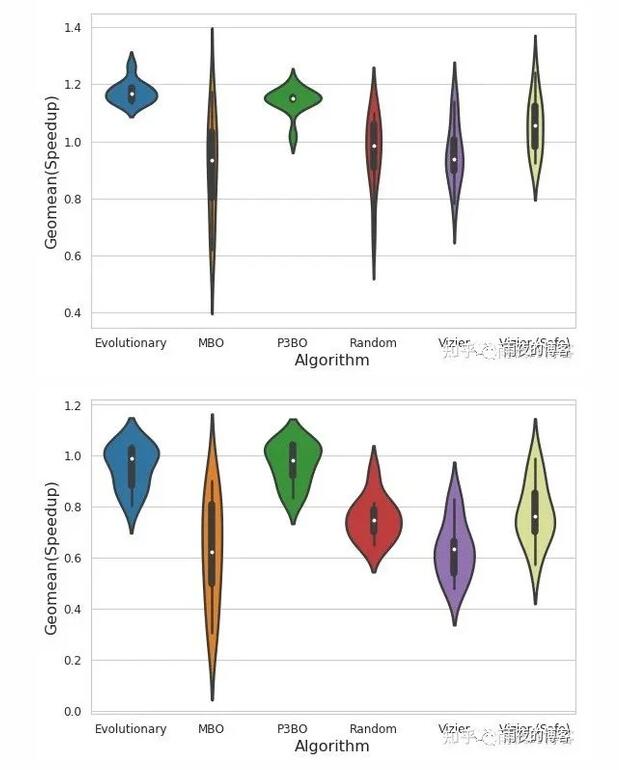
我們還研究了每種優化策略在不同面積預算約束(6.8 mm 2、5.8 mm 2和4.8 mm 2 )下的優勢。以下小提琴圖顯示了優化結束時(每次運行 4K 次運行 10 次后)在所研究的優化策略中最大可實現獎勵的完整分布。較寬的部分代表在特定給定獎勵下觀察可行架構配置的可能性更高。這意味著我們傾向于在具有更高獎勵(更高性能)的點上產生增加寬度的優化算法。
架構探索的兩個表現最佳的優化策略是進化和 P3BO,兩者都提供具有高回報和跨多次運行穩健性的解決方案。查看不同的設計約束,我們觀察到隨著面積預算約束的收緊,P3BO 優化策略會產生更高性能的解決方案。例如,當面積預算約束設置為 5.8 mm 2 時,P3BO 發現獎勵(吞吐量/加速器面積)為 1.25 的設計點優于所有其他優化策略。當面積預算約束設置為 4.8 mm 2 時,觀察到相同的趨勢,在多次運行中發現具有更高穩健性(更少可變性)的稍微更好的獎勵。
小提琴圖顯示了在 6.8 mm 2的面積預算下經過 4K 試驗評估后,在 10 個優化策略中運行的最大可實現獎勵的完整分布。P3BO 和 Evolutionary 算法產生了更多的高性能設計(更寬的部分)。x 軸和 y 軸分別表示研究的優化算法和基準加速器上加速(獎勵)的幾何平均值。
結論
雖然Apollo為更好地理解加速器設計空間和構建更高效的硬件邁出了第一步,但發明具有新功能的加速器仍然是一個未知領域和新領域。我們相信,這項研究是一條令人興奮的前進道路,可以進一步探索用于跨計算堆棧的架構設計和協同優化(例如編譯器、映射和調度)的 ML 驅動技術,從而為下一代開發具有新功能的高效加速器。應用程序。