













Adam又要“退休”了?耶魯大學團隊提出AdaBelief
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
要挑戰Adam地位的優化器又多了一個。
近日NeurIPS 2020收錄論文提出的一個優化器,在深度學習社區成為焦點,引起廣泛討論。
這就是由耶魯大學團隊提出的AdaBelief。團隊在論文中表示,該優化器兼具Adam的快速收斂特性和SGD的良好泛化性。
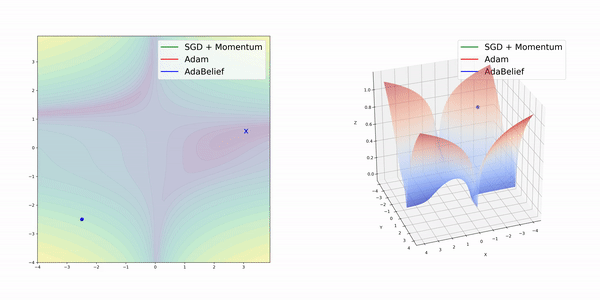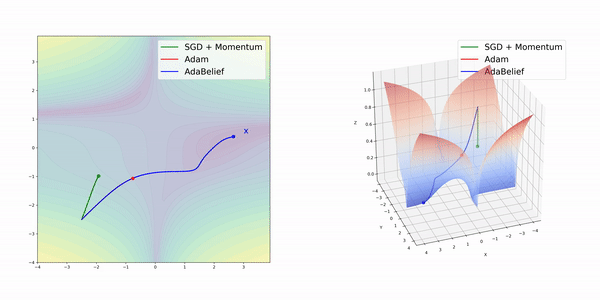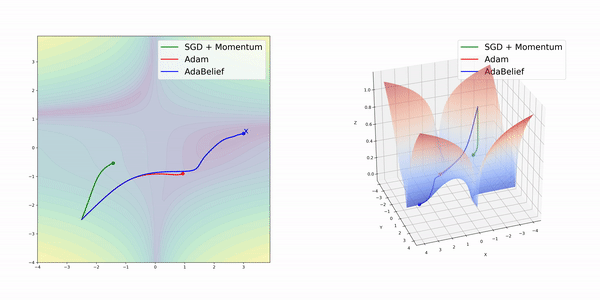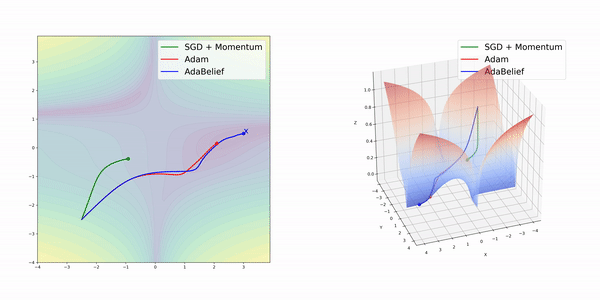
所謂AdaBelief,是指根據梯度方向上的“信念”(Belief)來調整訓練的步長。它和Adam在算法上的差別并不大。
二者差別在下面的算法實現上可以輕易看出。

相比Adam,AdaBelief沒有引入任何其他新參數,只是在最后一步更新時有差異,已在上圖中用藍色標出。
Adam的更新方向是
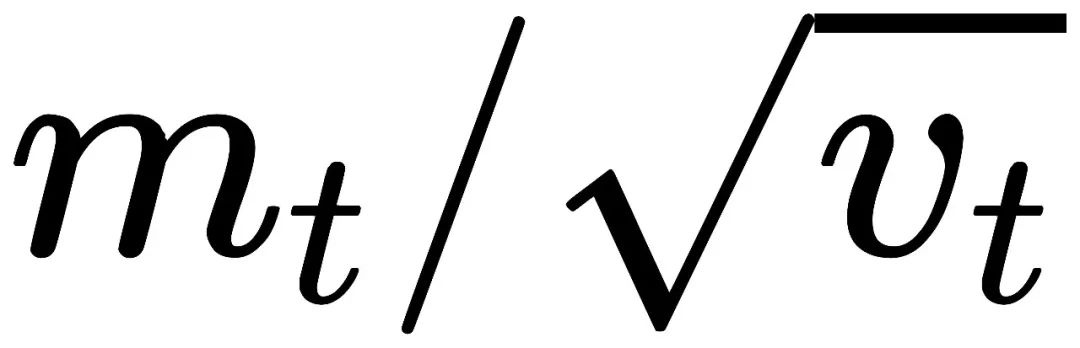
而AdaBelief的更新方向是
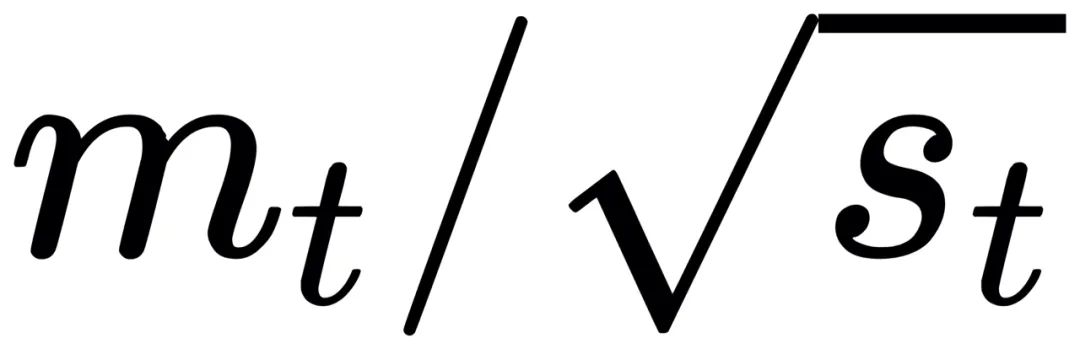
vt和st的差別在于,后者是
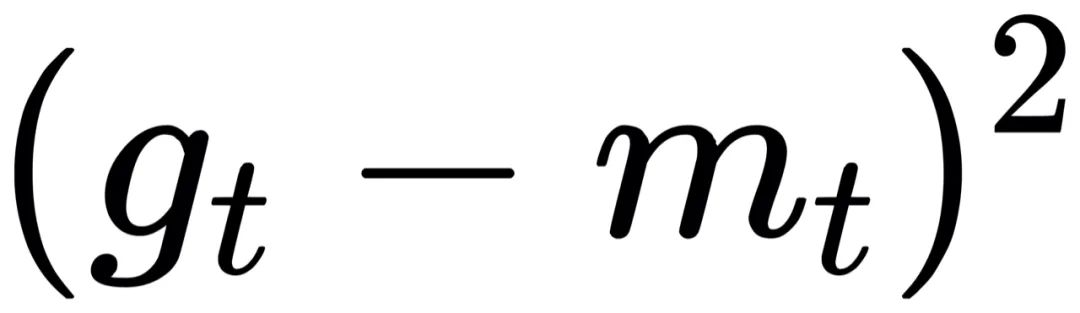
的指數移動平均(EMA)。
mt可以看做是gt的預測值,當實際值與預測值相差不大時,分母
較小,步長較大,權重放心大膽邁開步子更新。
而實際值與預測值相差很大時,AdaBelief傾向于“不相信”當前梯度,此時分母較大,更新步長較短。
為什么AdaBelief更好
只做在最后一步做了了一個小小的改變,未審核會產生如此之大的影響呢?
這主要是因為AdaBelief考慮了兩點。
1、損失函數的曲率問題
理想的優化器應該考慮損失函數的曲線,而不是簡單地在梯度較大的地方下采取較大的步長。
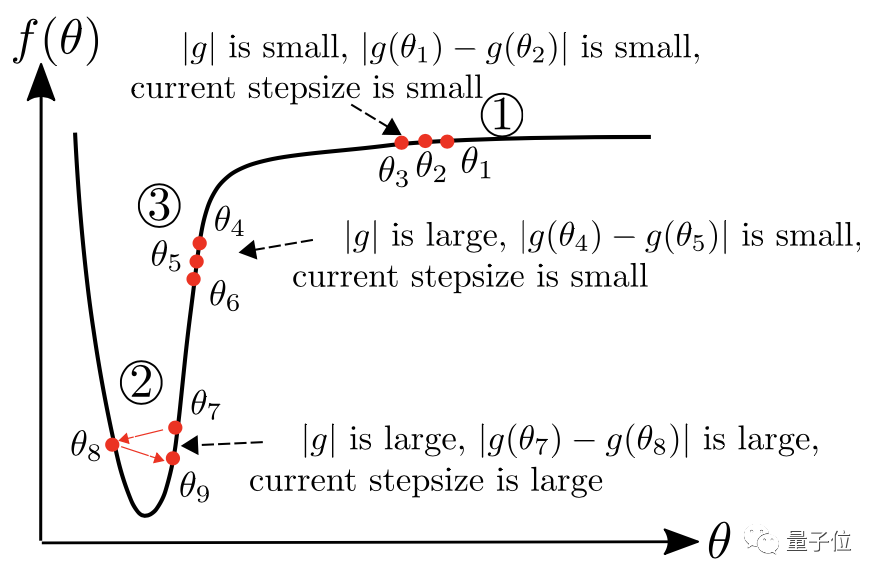
在“大梯度、小曲率”(圖中區域3)情況下|gt-gt-1|和|st|很小,優化器應增加其步長。
2、分母中的梯度符號
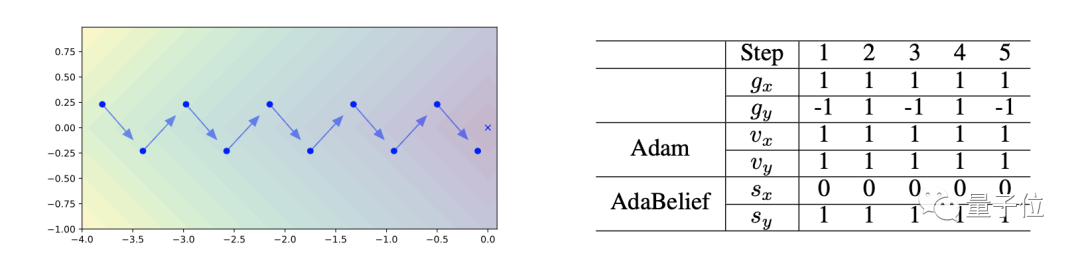
在上圖損失函數為
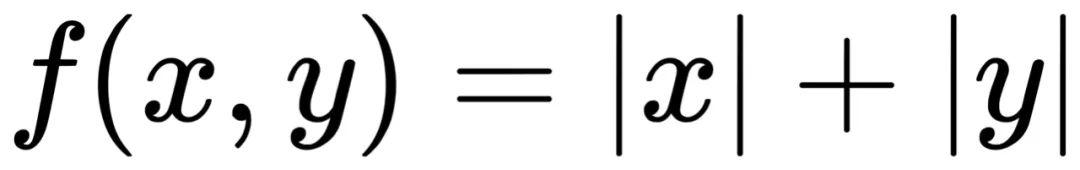
的情況下,藍色矢量代表梯度,十字叉代表最優解。
Adam優化器在y方向上振蕩,并在x方向上保持前進。這是由于
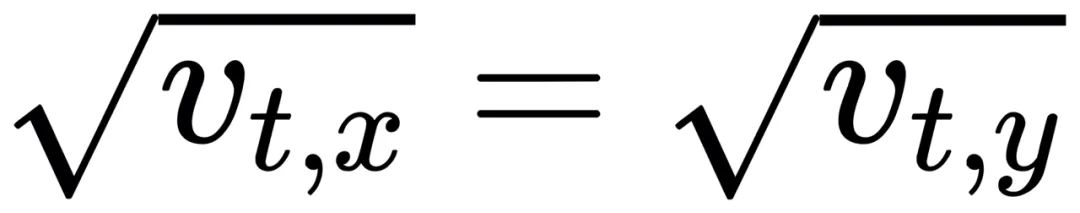
在低方差情況下,Adam中的更新方向接近“符號下降”。
而在AdaBelief中,

因此AdaBelief在x方向上走了一大步,在y方向上只會走一小步,防止振蕩產生。
實驗結果
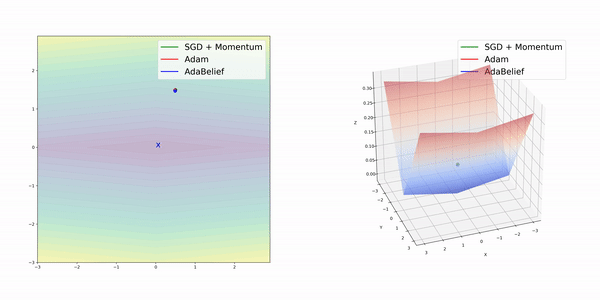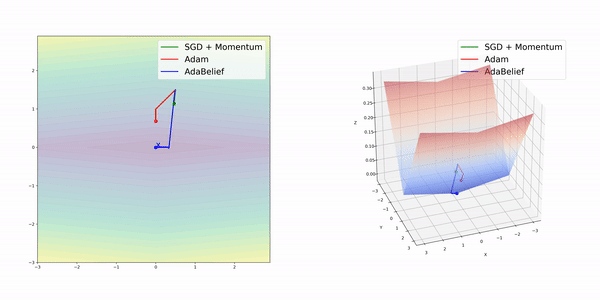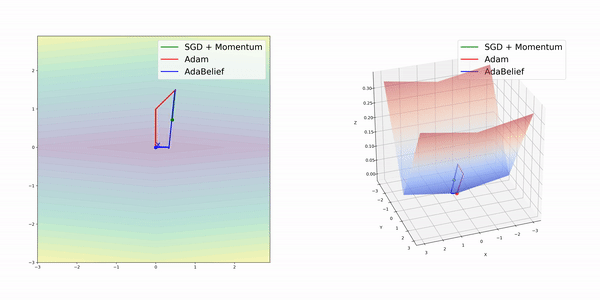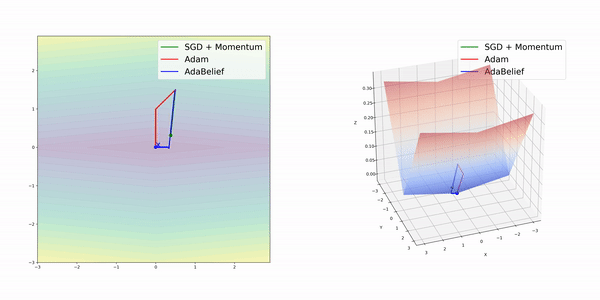
在簡單的幾種3維損失函數曲面上,AdamBelief展現出了優秀的性能。
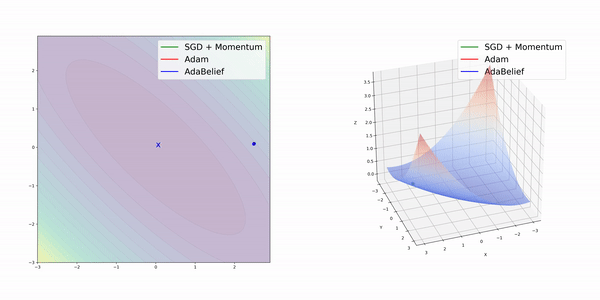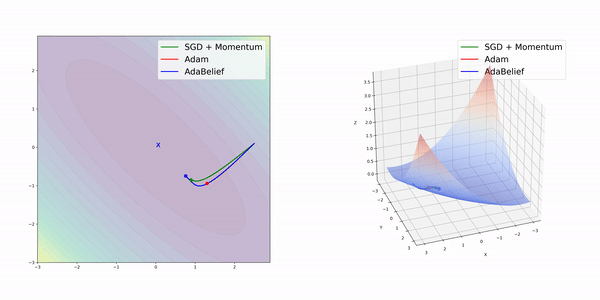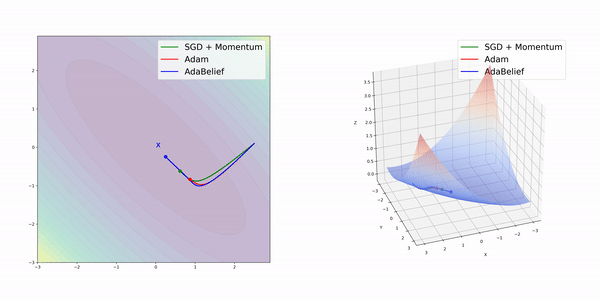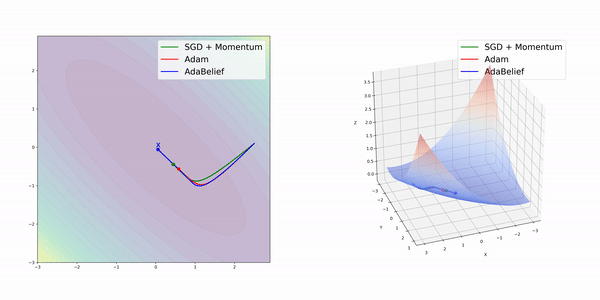
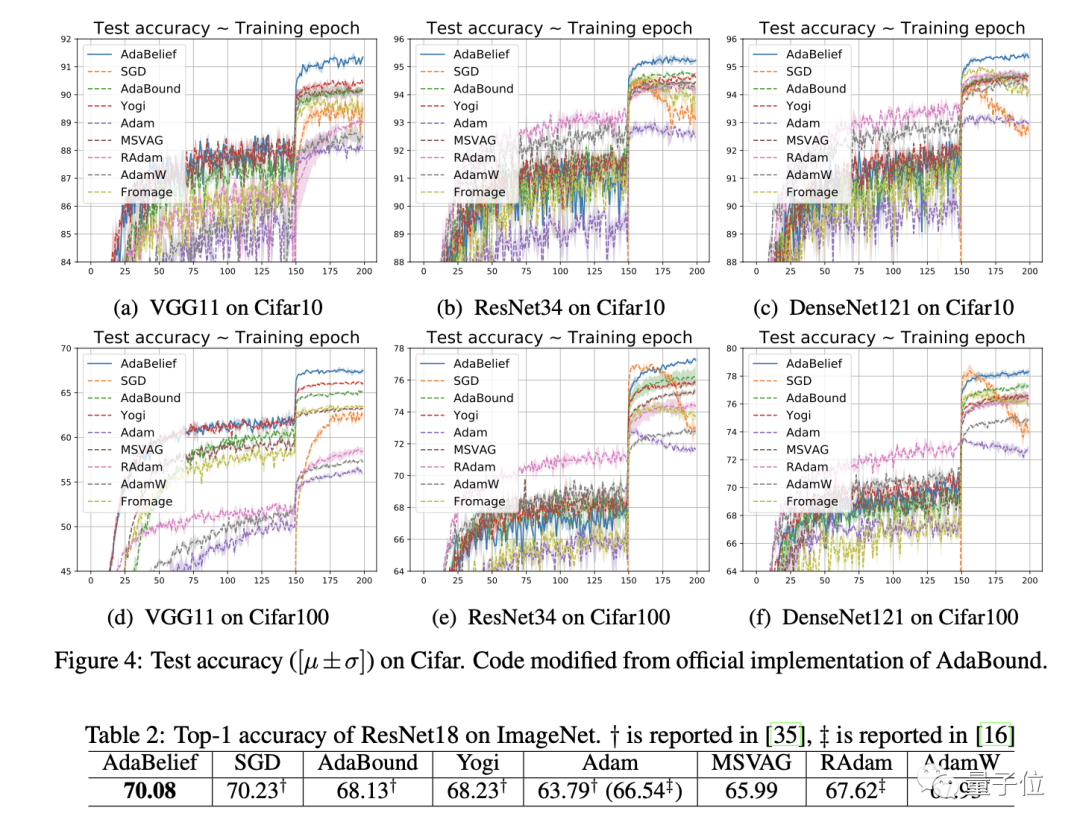
圖像分類
在CIFAR-10和CIFAR-100數據集上,用VGG11、ResNet34和DenseNet121三種網絡進行訓練,AdaBelief都顯示出更好的收斂結果。
而且在ImageNet數據上,AdaBelief在Top-1準確率上僅次于SGD。
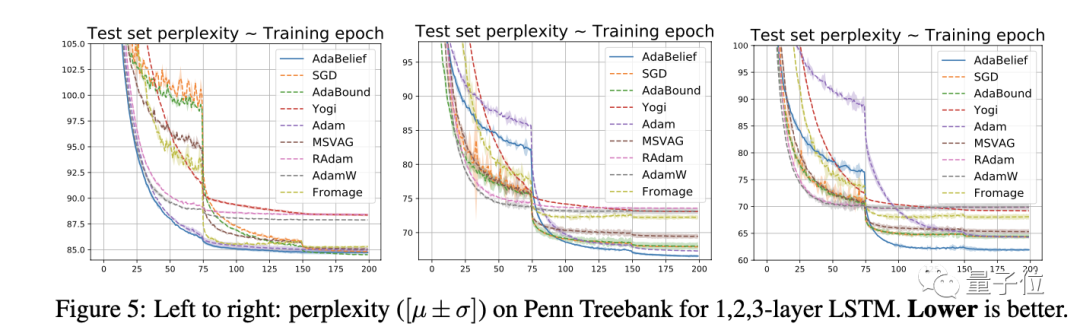
時間序列建模
在Penn TreeBank數據集上,用LSTM進行實驗,AdaBelief都實現了最低的困惑度。
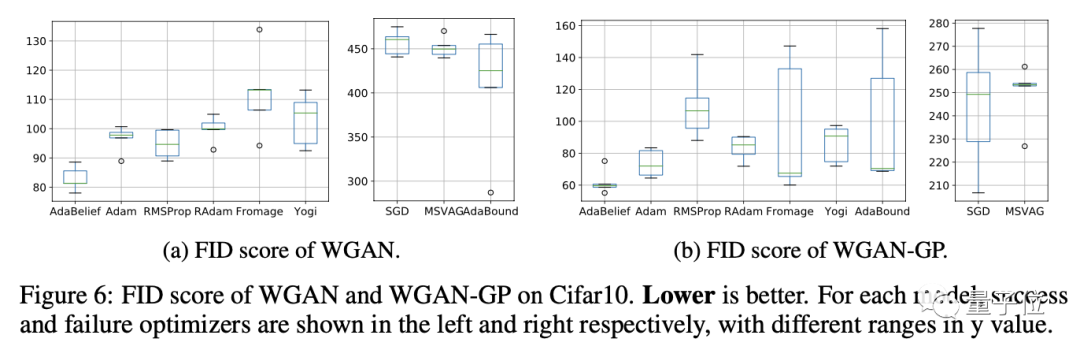
GAN
在WGAN和WGAN-GP上的實驗表明,經AdaBelief訓練的結果都得到了最低的FID。
網友質疑
雖然AdaBelief在多個任務上取得了不錯的效果,但該方法還是遭到不少網友質疑。
因為這些年來號稱取代Adam的優化器不計其數,但最終獲得時間檢驗的卻寥寥無幾。
網友首先質疑的是實驗baseline的選取問題。
有人認為,在CIFAR上,很難相信2020年SOTA模型的準確率低于96%,因此AdaBelief論文最終在選取baseline時有可能是選擇了與不太好的結果進行比較。
在ImageNet測試的表2里,為什么要使用ResNet18代替更標準的ResNet50?而且AdaBelief不是最優結果,卻用加粗方式標出,容易讓人產生誤解。絕妙的技巧是將提出的方法的得分加粗。
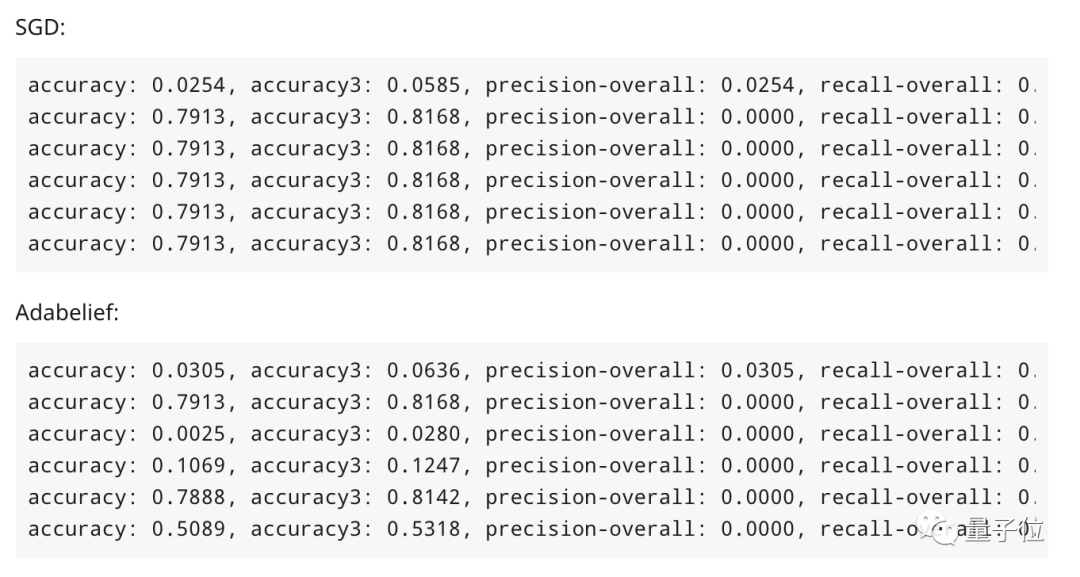
另外,還有人在作者未測試的NLP任務上進行實驗,很快AdaBelief就“崩潰”了,而SGD能夠很好地收斂。
AdaBelief不會是最后一個意圖取代Adam的優化器,它的泛化能力究竟如何,還有待更多研究者進一步地檢驗。
項目地址:
https://juntang-zhuang.github.io/adabelief/
論文地址:
https://arxiv.org/abs/2010.07468
代碼地址:
https://github.com/juntang-zhuang/Adabelief-Optimizer



















