李飛飛、謝賽寧等探索MLLM「視覺空間智能」,網(wǎng)友:2025有盼頭了
在購(gòu)買家具時(shí),我們會(huì)嘗試回憶起我們的客廳,以想象一個(gè)心儀的櫥柜是否合適。雖然估計(jì)距離是困難的,但即使只是看過一次,人類也能在腦海里重建空間,回憶起房間里的物體、它們的位置和大小。
我們生活在一個(gè)感官豐富的 3D 世界中,視覺信號(hào)圍繞著我們,讓我們能夠感知、理解和與之互動(dòng)。
這是因?yàn)槿祟悡碛幸曈X空間智能(visual-spatial intelligence),能夠通過連續(xù)的視覺觀察記住空間。然而,在百萬級(jí)視頻數(shù)據(jù)集上訓(xùn)練的多模態(tài)大語言模型 (MLLM) 是否也能通過視頻在空間中思考,即空間思維(Thinking in Space)?
為了在視覺空間領(lǐng)域推進(jìn)這種智能,來自紐約大學(xué)、耶魯大學(xué)、斯坦福大學(xué)的研究者引入了 VSI-Bench,這是一個(gè)基于視頻的基準(zhǔn)測(cè)試,涵蓋了近 290 個(gè)真實(shí)室內(nèi)場(chǎng)景視頻,包含超過 5000 個(gè)問答對(duì)。
其中,視頻數(shù)據(jù)是通過捕捉連續(xù)的、時(shí)間性的輸入來完成的,不僅與我們觀察世界的方式相似,而且比靜態(tài)圖像更能豐富空間理解和推理。在 VSI-Bench 上評(píng)估開源和閉源模型顯示,盡管模型與人類之間存在較大的性能差距,盡管 MLLM 面臨視頻理解、文本理解和空間推理的挑戰(zhàn),但其仍展現(xiàn)出了新興的視覺空間智能。
為了對(duì)模型行為展開研究,本文受到雙重編碼理論的啟發(fā)(該理論認(rèn)為語言處理和視覺處理既有區(qū)別又相互補(bǔ)充),他們提出了用于自我解釋(語言)和認(rèn)知圖(視覺)的選擇模型(selected models)。

- 論文地址:https://arxiv.org/pdf/2412.14171v1
- 論文主頁(yè):https://vision-x-nyu.github.io/thinking-in-space.github.io/
- 論文標(biāo)題:Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
這篇論文作者有我們熟悉的斯坦福大學(xué)教授李飛飛,她提倡的「空間智能」最近正在引領(lǐng) AI 發(fā)展方向,還有紐約大學(xué)計(jì)算機(jī)科學(xué)助理教授謝賽寧等。
謝賽寧表示,「視頻理解是下一個(gè)研究前沿,但并非所有視頻都是一樣的。模型現(xiàn)在可以通過 youtube 片段和故事片進(jìn)行推理,但是我們未來的 AI 助手在日常空間中導(dǎo)航和經(jīng)驗(yàn)如何呢?空間思維正是為這一問題誕生的,我們的最新研究 VSI-Bench,可以探索多模態(tài) LLM 如何看待、記憶和回憶空間。」

「在視覺處理方面,我們通常處理空間問題,但很少進(jìn)行推理;而多模態(tài)大語言模型(LLM)雖然能夠思考,但通常忽略了邏輯空間。然而,作為人類 —— 無論是做心理旋轉(zhuǎn)測(cè)試還是為新家定制家具 —— 我們依賴于空間和視覺思維 。而這些思維并不總能很好地轉(zhuǎn)化為語言。」

「我們通過研究涵蓋各種視覺空間智能任務(wù)(關(guān)系和度量)的新基準(zhǔn)來探索這一點(diǎn)。」

李飛飛也對(duì)這項(xiàng)研究進(jìn)行了宣傳,她表示這項(xiàng)名為「Thinking in Space」的研究,是對(duì) LLM(大部分都失敗了)在空間推理方面表現(xiàn)的評(píng)估,而空間推理對(duì)人類智能至關(guān)重要。2025 年還有更多值得期待的事情,以突破空間智能的界限!

在李飛飛的這條推文下,網(wǎng)友已經(jīng)開始期待即將到來的 2025 年。

在論文主頁(yè)給出的 Demo 中,作者提供了谷歌 Gemini 模型在視覺空間智能上的一些表現(xiàn)。(以下視頻均以 2 倍速播放。)
1:估計(jì)相對(duì)距離

問:如果我站在冰箱旁邊,面對(duì)著洗衣機(jī),爐子是在我的左邊、右邊還是后面……

2:讓大模型數(shù)物體

問:房間里有幾把椅子?Gemini-1.5 Pro 給出了 2。

3:根據(jù)視頻猜測(cè)物體出現(xiàn)的順序

問:以下類別在視頻中第一次出現(xiàn)的順序是:毯子、垃圾桶、微波爐、植物?Gemini 給出 B 選項(xiàng),正確答案是 C。

4:估計(jì)房間大小

問:這個(gè)房間有多大(平方米)?如果展示了多個(gè)房間,估計(jì)一下組合空間的大小。

VSI-Bench 介紹
VSI-Bench 是一個(gè)用于定量評(píng)估從第一視角視頻出發(fā)的 MLLM 視覺空間智能的工具。VSI-Bench 包含了超過 5000 個(gè)問答對(duì),這些問答對(duì)來源于 288 個(gè)真實(shí)視頻。這些視頻包括居住空間、專業(yè)場(chǎng)所(例如,辦公室、實(shí)驗(yàn)室)和工業(yè)場(chǎng)所(例如,工廠)—— 以及多個(gè)地理區(qū)域。VSI-Bench 的質(zhì)量很高,經(jīng)過迭代審查以最小化問題的歧義,并移除了從源數(shù)據(jù)集中傳播的錯(cuò)誤注釋。
VSI-Bench 包括八項(xiàng)任務(wù),如圖 3 所示,包括:物體計(jì)數(shù)、相對(duì)距離、出現(xiàn)的順序、相對(duì)方向、物體大小、絕對(duì)距離、房間面積、路徑規(guī)劃。

VSI-Bench 的任務(wù)演示。注意:為清晰簡(jiǎn)潔起見,上述問題略作簡(jiǎn)化。
數(shù)據(jù)集統(tǒng)計(jì)見圖 5。

此外,本文還開發(fā)了一個(gè)復(fù)雜的基準(zhǔn)構(gòu)建流程,以有效地大規(guī)模生成高質(zhì)量問答(QA)對(duì),如圖 4 所示。

評(píng)估
評(píng)估設(shè)置:本文對(duì) 15 個(gè)支持視頻的 MLLM 進(jìn)行了基準(zhǔn)測(cè)試。專有模型包括 Gemini-1.5 和 GPT-4o。開源模型包括 InternVL2、ViLA、LongViLA、LongVA、LLaVA-OneVision 和 LLaVA-NeXT-Video 。
主要結(jié)果:通過 5000 多個(gè)問答對(duì),作者發(fā)現(xiàn) MLLM 表現(xiàn)出了有競(jìng)爭(zhēng)性的視覺空間智能(盡管仍然低于人類)。Gemini Pro 表現(xiàn)最佳,但與人類的表現(xiàn)仍有差距。
具體而言,人類評(píng)估者的平均準(zhǔn)確率達(dá)到 79%,比最佳模型高出 33%,在配置和時(shí)空任務(wù)上的表現(xiàn)接近完美(94%-100%)。
然而,在需要精確估計(jì)的測(cè)量任務(wù)上,差距縮小了,MLLM 在定量任務(wù)中表現(xiàn)出相對(duì)優(yōu)勢(shì)。
在專有模型中,Gemini-1.5 Pro 脫穎而出,盡管只在 2D 數(shù)字?jǐn)?shù)據(jù)上進(jìn)行訓(xùn)練,但它大大超過了機(jī)會(huì)基線,并在絕對(duì)距離和房間大小估計(jì)等任務(wù)中接近人類表現(xiàn)。
表現(xiàn)最佳的開源模型,如 LLaVA-NeXT-Video-72B 和 LLaVA-OneVision-72B,取得了有競(jìng)爭(zhēng)力的結(jié)果,僅落后 Gemini-1.5 Pro 4%-5%。然而,大多數(shù)開源模型(7/12)都低于機(jī)會(huì)基線,暴露出視覺空間智能的明顯缺陷。

為了更好地理解模型成功或失敗的時(shí)間和原因,并闡明它們所擁有的視覺空間智能的各個(gè)方面,本文研究了 MLLM 如何在空間語言中思考。
當(dāng)被要求解釋自己時(shí),LLM 表示空間推理(而不是物體識(shí)別或語言能力)是主要瓶頸。
在成功示例中,該模型展示了高級(jí)視頻理解能力,具有準(zhǔn)確的時(shí)間戳描述和正確的逐步推理過程。全局坐標(biāo)系的使用表明 MLLM 可以通過整合空間背景和推理來構(gòu)建隱式世界模型。

錯(cuò)誤分析:對(duì) VSI-Bench(tiny)上表現(xiàn)最佳的 MLLM 的錯(cuò)誤進(jìn)行分析,發(fā)現(xiàn)主要有四種錯(cuò)誤類型:視覺感知、語言智能、關(guān)系推理和第一視角 - 他人視角轉(zhuǎn)換。圖 6 顯示,71% 的錯(cuò)誤源于空間推理,特別是在理解距離、大小和方向方面。這表明空間推理仍然是提高 VSI-Bench 上 MLLM 性能的關(guān)鍵瓶頸。

此外,本文還有一些其他發(fā)現(xiàn)。
- 發(fā)現(xiàn) 1:空間推理是影響 MLLM 在 VSI-Bench 上的主要瓶頸。
- 發(fā)現(xiàn) 2:語言提示技術(shù)雖然在語言推理和一般視覺任務(wù)中有效,但對(duì)空間推理有害。
- 發(fā)現(xiàn) 3:在記憶空間時(shí),MLLM 會(huì)根據(jù)給定的視頻在模型中形成一系列局部世界模型,而不是統(tǒng)一的全局模型。
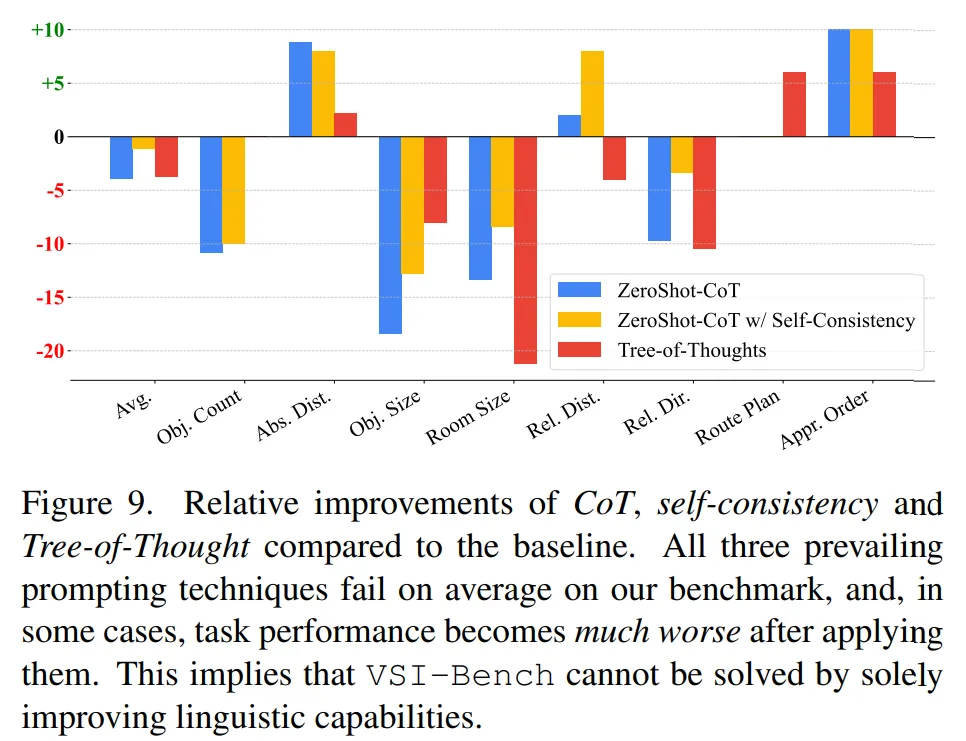
語言提示技術(shù)在這種情況下是無效的 —— 像 CoT 或多數(shù)投票這樣的方法實(shí)際上對(duì)本文任務(wù)是非常有害的。
了解更多內(nèi)容,請(qǐng)參考原論文。