













七個關鍵因素:如何選擇出優秀機器學習算法?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
任意的機器學習問題都可以應用多種算法,生成多種模型。例如,垃圾郵件檢測分類問題可以使用多種模型來解決,包括樸素貝葉斯模型、邏輯回歸模型和像BiLSTMs這樣的深度學習技術。
擁有豐富的選擇是好的,但難點在于,如何決定在生產中實現哪個模型。雖然我們有許多性能指標來評估一個模型,但為每個問題實現每個算法是不明智的。這需要大量的時間和大量的工作,因此,知道如何為特定的任務選擇正確的算法至關重要。
在本文中,我們將研究可以幫助選擇最適合你的項目和特定業務需求的算法的因素,理解這些因素將使你理解模型將要執行的任務和問題的復雜性。
可解釋性
當我們討論算法的可解釋性時,討論的是它解釋其預測的能力,缺乏這種解釋的算法被稱為黑箱算法。
像k-最近鄰算法(k-nearest neighbor,KNN)這樣的算法通過特征重要性具有較高的可解釋性,而線性模型這樣的算法通過賦予特征的權重具有可解釋性。當考慮你的機器學習模型最終會做什么時,了解算法的可解釋性變得非常重要。
對于諸如檢測癌細胞或判斷房屋貸款的信用風險等分類問題,必須了解系統結果背后的原因。僅僅預測是不夠的,我們需要能夠評估它。即使預測是準確的,我們也必須了解導致這些預測的過程。如果理解結果背后的原因是問題的要求,那么需要相應地選擇合適的算法。
數據點的數量和特征
在選擇合適的機器學習算法時,數據點的特征和數量起著至關重要的作用。根據用例的不同,機器學習模型將與各種不同的數據集一起工作,這些數據集的數據點和特征也會有所不同。在某些情況下,選擇模型需要理解模型如何處理不同大小的數據集。
像神經網絡這樣的算法可以很好地處理大量數據和大量特征。但有些算法,如支持向量機,只能處理有限數量的特征。在選擇算法時,一定要考慮到數據的大小和特征的數量。
數據格式
數據通常來自于開源和自定義數據資源的混合,因此它也可以以各種不同的格式出現。最常見的數據格式是分類的和數值的。任何給定的數據集可能只包含分類數據、數字數據或兩者的組合。
算法只能處理數值數據,因此如果你的數據在格式上是分類的或非數值的,那么你將需要考慮將其轉換為數值數據的過程。
線性數據
在選擇模型之前,了解數據的線性是必要的一步。確定數據的線性有助于確定決策邊界或回歸線的形狀,這反過來指導我們使用的模型。一些諸如身高-體重的關系可以用線性函數表示,這意味著當一個增加時,另一個通常以相同的值增加,這種關系可以用線性模型表示。
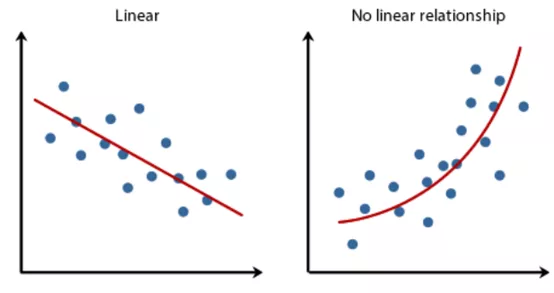
通過散點圖理解數據的線性度
了解這一點將幫助你選擇合適的機器學習算法。如果數據幾乎是線性可分的,或者可以使用線性模型表示,那么支持向量機、線性回歸或邏輯回歸等算法是一個不錯的選擇。此外,還可以采用深度神經網絡或集成模型。
訓練時間
訓練時間是算法學習和創建模型所花費的時間。對于像針對特定用戶的電影推薦這樣的用例,每次用戶登錄時都需要對數據進行培訓。但是對于像庫存預測這樣的用例,需要每秒鐘都對模型進行訓練。因此,考慮訓練模型所花費的時間是至關重要的。
眾所周知,神經網絡需要大量的時間來訓練一個模型。傳統的機器算法,如k近鄰算法和邏輯回歸算法,花費的時間要少得多。一些算法,如隨機森林,需要根據所使用的CPU內核不同的訓練時間。
預測時間
預測時間是模型進行預測所需要的時間。對于產品通常是搜索引擎或在線零售商店的互聯網公司來說,快速預測時間是用戶體驗順暢的關鍵。在這些情況下,速度非常重要,如果預測速度太慢,即使有良好結果的算法也沒有用。
然而,在一些業務需求中,準確性比預測時間更重要。比如在我們前面提到的癌細胞的例子中,或者在檢測欺詐交易時。支持向量機、線性回歸、邏輯回歸和幾種類型的神經網絡等算法可以進行快速預測。然而,像KNN和ensemble模型這樣的算法通常需要更多的時間來進行預測。
存儲需求
如果可以將整個數據集加載到服務器或計算機的RAM中,則可以應用大量算法。然而,當這是不可能的,你可能需要采用增量學習算法。
增量學習是一種機器學習方法,通過輸入數據不斷地擴展已有模型的知識,即進一步訓練模型。增量學習算法的目的是適應新的數據而不忘記已有的知識,因此不需要對模型進行再訓練。
在為機器學習任務選擇算法時,性能似乎是最明顯的指標。但僅憑性能還不足以選擇出最佳算法,你的模型需要滿足其他標準,如內存需求、訓練和預測時間、可解釋性和數據格式。通過綜合更廣泛的因素,你可以做出更自信的決定。如果很難在幾個選定的模型中選擇最佳算法,你也可以在驗證數據集上測試它們。
當決定實現一個機器學習模型時,選擇正確的模型意味著分析你的需求和預期結果。雖然這可能需要一些額外的時間和努力,但回報是更高的準確性和改進的性能。















