云上高級應用篇:亞馬遜云科技 云上人工智能創新實戰
云計算是新的服務形式,它有萬億級別的市場空間。人工智能迎來了高速發展階段,正在引爆智能時代。云計算與人工智能看似是兩個獨立的技術生態,其實有千絲萬縷的關系,兩者的結合將會相得益彰,釋放出更多價值。那么云上人工智能有什么樣的價值呢?我們將在本文進行一些介紹。
一、 云計算與人工智能
現如今,無論是城市還是農村,自來水取水是絕對的主流,只需輕輕擰開水龍頭,源源不斷的水立刻就流出來了,這些水是經過處理和檢測才送到了老百姓的家里的,無須擔心水質問題,無需自己打井,更無需管理汲水設備。
云計算與此類似,只需連上云,計算應用就“自然來“了。這種集約式的轉變正在IT世界如火如荼地進行當中,企業從自建機房/數據中心轉而采用專業的云計算服務商的云服務,無需自己運維管理軟硬件基礎設施,只要按需求采購按用量付費,再也不用人人都要懂點運維知識,企業可以減少投入,將更多精力放在業務本身。
云計算雖然已經發展了十幾年,但云計算本身并沒有為IT技術發展帶來質變,它本身更多是技術交付模式的變化,是一種按需多快好省地交付所需服務,以更集約的方式滿足原有需求的方法。隨著云計算發展變化的深入,這種集約的云服務模式逐漸從量變發展出了質變,特別是當云計算遇上人工智能和機器學習的時候。
從1956年達特茅斯的一場會議開始,人類開啟了對于人工智能的探索,但受限于算力,人工智能經過了幾次熱潮,始終停留在實驗室和影視作品的幻想里,與大多數人的生活相距甚遠。但在摩爾定律的作用下,算力不斷增強,而且算力的單位能源消耗成本越來越低,人工智能(具體而言是機器學習)終于迎來了屬于它的時代。
這個時代里,云計算正在快速發展,云計算彈性的資源,靈活可用的部署方式,讓人工智能更好更快地進行部署和落地。反過來說,人工智能的創新與發展的成果通過龐大的云計算平臺來放大。兩者相互促進、相互成就。云計算與人工智能的結合是必然的,會有越來越多的機器學習在云上進行。
亞馬遜云科技是全球領先的云計算供應商,在云計算方面有非常豐富的云產品布局。在人工智能及機器學習方面也有完善的產品和服務集合,使得用戶一方面有許多可直接調用API的服務,另一方面,還能在云上完成機器學習構建、訓練、部署的全流程,例如,通過亞馬遜云科技著名的機器學習開發服務Amazon SageMaker,即可達成這項目標。
Amazon SageMaker可以說是幫助企業踏入機器學習旅程的一張通票。Amazon SageMaker作為云上機器學習平臺的典型代表,利用云的優勢降低機器學習成本,成為了亞馬遜云科技目前非常具有特色、非常實用的云上機器學習服務。
二、 為什么需要用云上機器學習平臺
技術的發展史就是技術方案成本降低史,舊時王謝堂前燕,飛入尋常百姓家,說的是技術迭代造就的市場成就。
智能時代下,各種算法方面已有數十年的充足積累,數據存儲成本也足夠低,算力也是易于獲得的資源,特別是在云計算基礎設施的幫助下,將人工智能(機器學習)所需的三大要素進行了緊密集成,綜合使用成本大大降低。當年,Wintel聯盟打造的PC生態讓電腦變成個人消費品;而今,云計算的發展對于人工智能的普及落地也將有同等重要的作用。
機器學習從數據準備、到模型訓練,再到模型調優…… 整個流程對于基礎設施的需求相對明確。數據準備階段和模型部署階段在滿足需求的前提下盡可能要控制成本;而在訓練階段,則要求算力能在規定時間里完成訓練任務。考慮到對算力的需求存在峰值和低谷,云計算彈性能力讓資源召之即來,揮之即去,按需付費的特點對于降低成本非常合適。
企業在現有架構上部署一套機器學習的方案不是不行,只是除了要克服上述資源成本方面的問題,還要考慮到管理一整套方案的隱性成本,設立一套關于機器學習業務的流程,還要規避自行處理數據合規方面的問題,應對可能出現的數據泄露問題,等等。與其自行解決這些問題,不如選用一套成熟、經過眾多企業驗證的云上解決方案。
Amazon SageMaker是一個構建、訓練與部署機器學習模型的全托管服務,作為典型的云上機器學習平臺,能完美解決上述問題,同時避免了企業采購和部署軟硬件平臺的前期投入。機器學習環境配置需要安裝配置許多軟件, Amazon SageMaker可以節省后期運維升級維護上的投入,節省大量成本,利用云按需付費的特點讓投入物盡其用。
Amazon SageMaker能將繁瑣的訓練過程變得簡單高效,減少訓練過程耗費的時間和精力,讓企業以很少的投入就能使用機器學習帶來的諸多便利和優勢。接下來,我們通過具體的操作來介紹Amazon SageMaker云上機器學習開發平臺的優勢。
三、云上機器學習開發平臺實戰
2020年4月底,亞馬遜云科技在中國區的光環新網和西云數據都上線了Amazon SageMaker。為便于通俗講解,這里選用亞馬遜云科技全球區域的個人賬戶來進行實操。中國區域的Amazon SageMaker服務和全球區域的絕大部分服務是一樣的,除了暫不提供數據標注(Labelling)以外,大部分與全球版的一致。
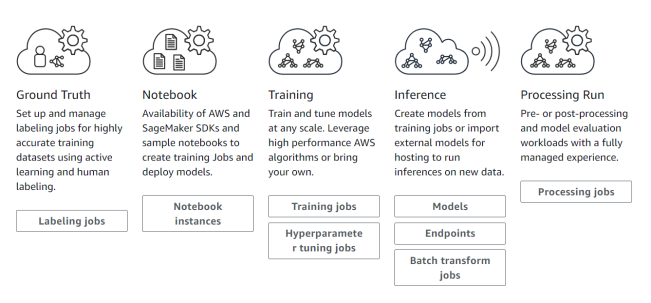
亞馬遜云科技于2017年首次發布了Amazon SageMaker,自此就不斷“迭代”更新。它提供從數據準備、模型構建、模型訓練/調優、到模型部署推理等全流程支持。
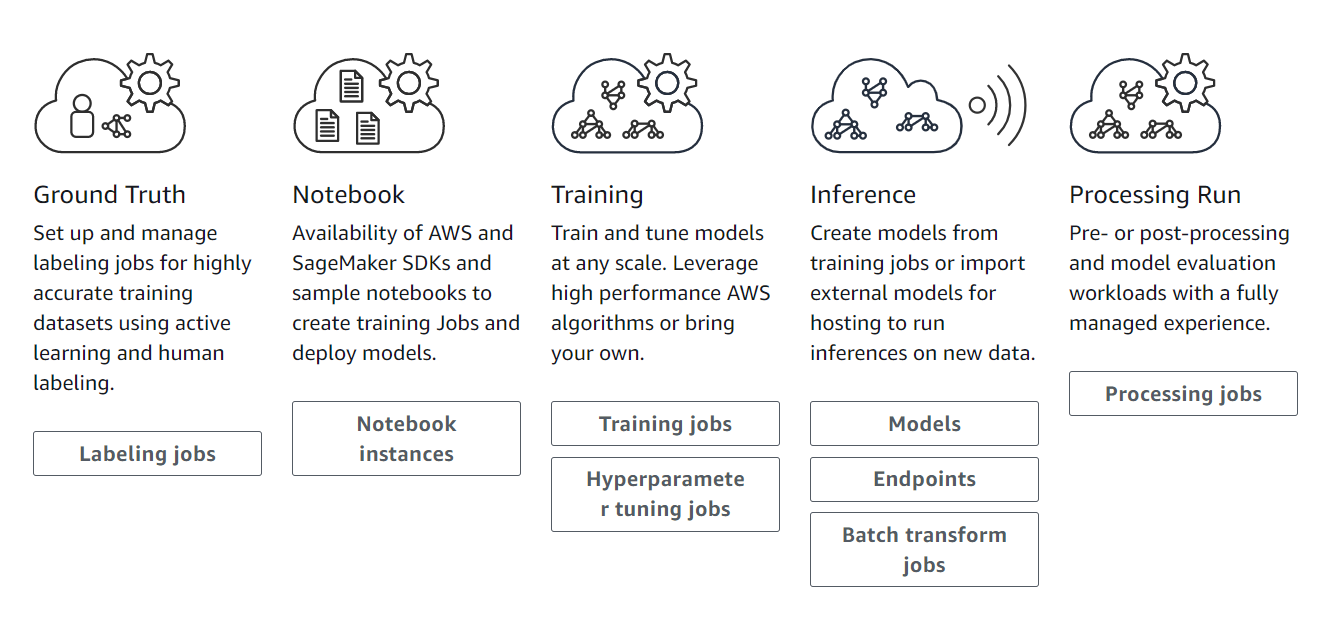
圖片來源于亞馬遜云科技全球網站截圖
其中,數據準備能提供的服務就是數據標注,畢竟現在的機器學習還是以監督式學習為主,這一服務與Amazon Mechanical Turk的數據標注外包服務有關聯,同時還提供了自動數據標注的能力。
模型構建和訓練到部署,大部分都是在托管的Jupyter Notebook里完成的,以致于有人誤以為Amazon SageMaker就只是亞馬遜云科技托管的Jupyter Notebook。
1,Amazon SageMaker初步利用了云的優勢
接下來,我們創建Notebook instances實例來實戰體驗一下,看看Amazon SageMaker是怎么利用云的優勢打造AI方案的。
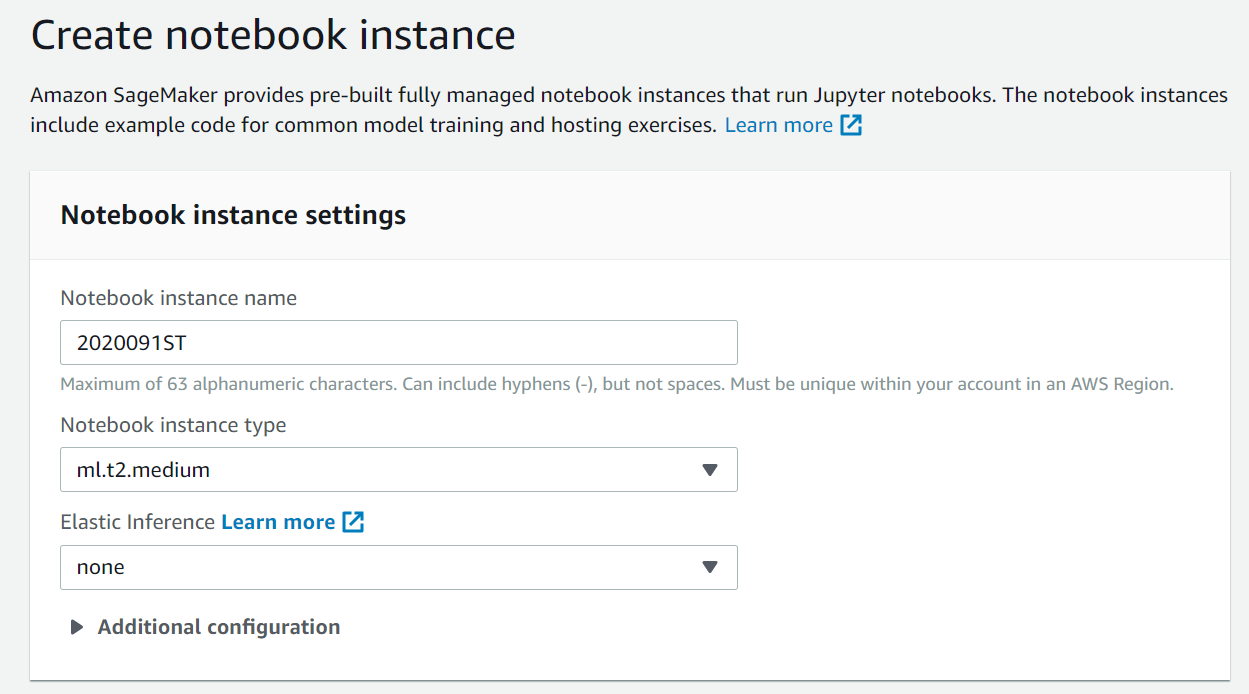
開啟Amazon SageMaker ,創建一個實例。系統默認的實例類型是ml.t2.medium,Inference推理的實例可以暫不設置,權限和網絡設置部分也可以不作修改。
Amazon SageMaker的控制臺可以控制實例,停止或者啟動,也可以控制各種相關資源。
啟動完成后打開Jupyter,可以看到上圖。
點擊打開JupyterLab,如上圖所示。
Amazon SageMaker托管的Jupyter和JupyterLab與本地版本在外觀上沒太多區別,最大的不同在于,Amazon SageMaker托管的版本多了許多示例代碼。
出于演示的目的,我們找一個操作簡單,步驟清晰的示例代碼,用K-means聚類算法和經典的MNIST數據集訓練一個分類模型,識別手寫體圖片里的數字。
以下是訓練過程:
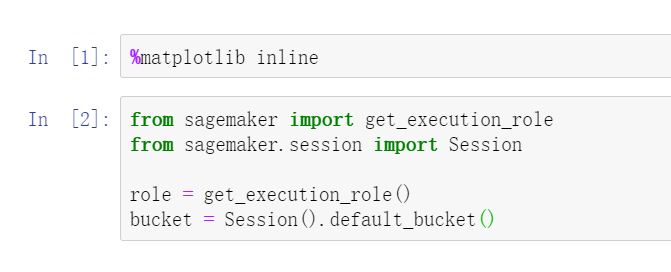
第一步,設置運行環境,賦予必要的權限。值得注意的是,這里引入Amazon SageMaker自己的SDK,簡單理解為賦予了notebook使用亞馬遜云科技資源的能力,包括各種硬件資源,還有亞馬遜云科技內置的一些算法,需要了解這一套SDK才能用的更方便。
第二步驟是導入各種工具包,對用來訓練的數據進行初步的探索,這部分與亞馬遜云科技資源無關。
圖片來源于亞馬遜云科技全球網站截圖
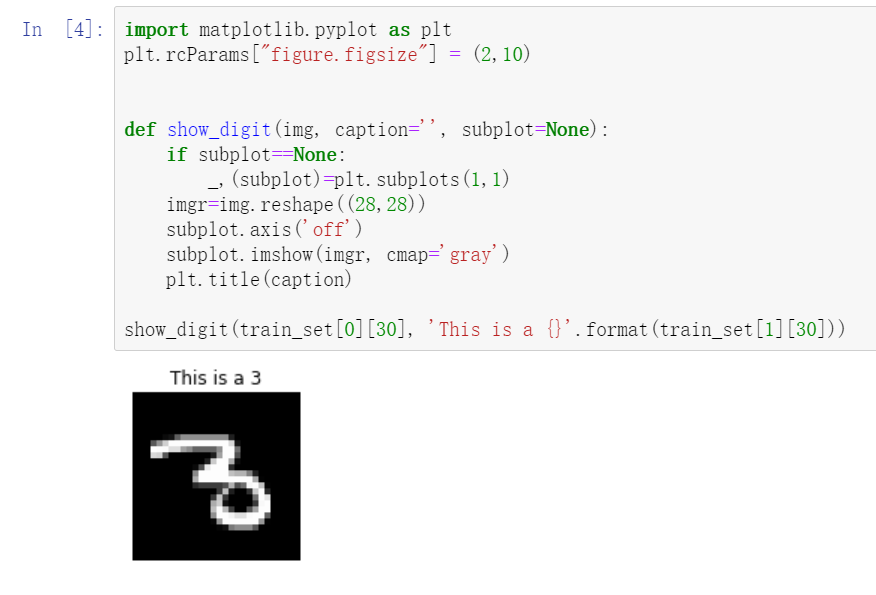
第三步可以查看數據的樣子,如上圖的MNIST數據集的一張圖片,MINIST數據集本身包含70萬張28 x 28 像素的手寫體圖片。
圖片來源于亞馬遜云科技全球網站截圖
第四步,主要是設置訓練的參數,包括設置輸入數據和輸出模型的位置,設置訓練所需實例的數量和實例的類型“ml.c4.xlarge”,已知0-9是十個數字,k值就是10,至此,模型構建完畢。
圖片來源于亞馬遜云科技全球網站截圖
第五步,調用.fit函數完成訓練,耗時大約4分鐘。
圖片來源于亞馬遜云科技全球網站截圖
第六步,將訓練好的模型部署在實例上供后續調用模型推理。
第七部分,從驗證集數據里選出100個數據,用模型將其分到0-9,一共10個類別里去,分類效果如下圖所示。

圖片來源于亞馬遜云科技全球網站截圖
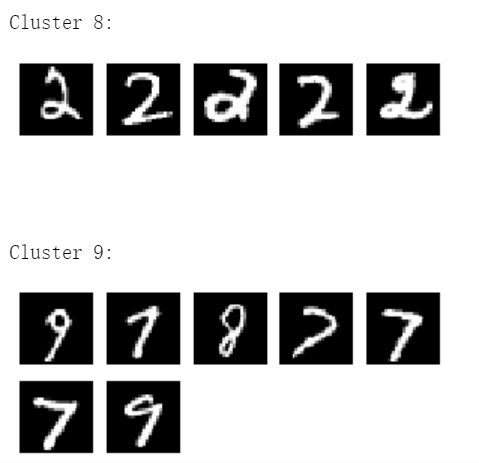
圖片來源于亞馬遜云科技全球網站截圖
可以看到,彼此相似的圖片被分到一個類別里。肉眼可見其中是有一定規律的,但許多數字不一樣,誤差還挺大的。
實際機器學習的訓練過程中,需要機器學習專家來不斷減小誤差,而且,K-means算法在這里其實不是特別合適,作為數據科學家你需要找到合適算法,然后,還需要不斷調整超參數,以獲取表現最佳的模型。
這個過程其實非常繁瑣且復雜,耗時耗力,對于這部分需求,亞馬遜云科技的Amazon SageMaker在超參數優化階段提供了自動化操作,可以以貝葉斯和隨機搜索的方式自己調優超參數,這部分內容我們會在下面內容中提到。
其實Amazon SageMaker托管的Jupyter Notebook在本地機器上也完全可以部署,兩者的區別在于,亞馬遜云科技包裝了操作云資源的類庫,可以直接調用亞馬遜云科技的各種資源。本次實驗中,我們直接調用了2個ml.c4.xlarge實例來做訓練,訓練耗時僅需四分鐘,模型部署階段使用的是ml.m4.xlarge,也完全可以指定規格的實例。
如果是只在本地訓練的話,就只能調用本地的資源,無論是多大規模的訓練量,都只有有限的資源可以使用,為了應對偶爾的計算量峰值,不得不購買更多資源,于是,在大多數時候忍受較低的資源使用率。浪費就意味著產生了額外成本。

訓練完成后的最后一步,記得清理掉部署模型的Endpoint。
這里Amazon SageMaker主要發揮出了云計算本身的優勢,計算資源召之即來揮之即去,按照使用量來付費。但這只是簡單初步利用了云的特點,云上服務并沒有帶來太多額外的功能,因為在實際使用中,還有許多麻煩的問題沒有解決,比如訓練過程反復優化超參數的過程非常費時費力,非常的不人性化,Amazon SageMaker Studio的出現真正就是為了解決此類問題。
2,Amazon SageMaker Studio才真正發揮了云的優勢
Amazon SageMaker Studio是一個Web端的IDE工具,跟所有開發工具一樣,集成了開發環境,能寫代碼,能做Debug,能看運行效果。
(1) 便捷的開發環境
圖片來源于亞馬遜云科技全球網站截圖
創建并運行Amazon SageMaker Studio,上圖是Amazon SageMaker Studio的起始界面,與JupyterLab界面相似度很高,不過,亞馬遜云科技在這里做了許多改動,加入了亞馬遜云科技自有的許多高級操作。
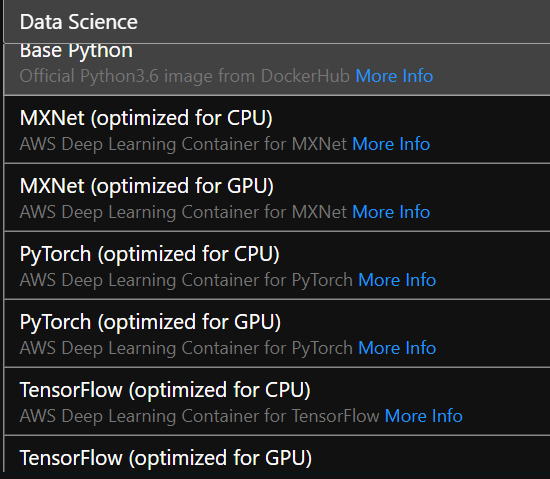
圖片來源于亞馬遜云科技全球網站截圖
比如,在Launcher窗口提供了各種容器鏡像可選,有TensorFlow、PyTorch以及MXNet各種常見的機器學習框架可用,這些環境都是配置好的,省去了自己配置的麻煩,除了默認的CPU版本,還有GPU的版本可選。
要知道,在本地自己配置的時候,無論是Windows上還是Linux上,如果想支持GPU的話,都需要一番繁瑣的操作,有過親身經歷的人都會有比較深入的印象的,現在TensorFlow GPU版本可以以容器方式部署了,但也只支持在Linux上操作。
圖片來源于亞馬遜云科技全球網站截圖
本地Jupyter Notebook切換Kernel的操作
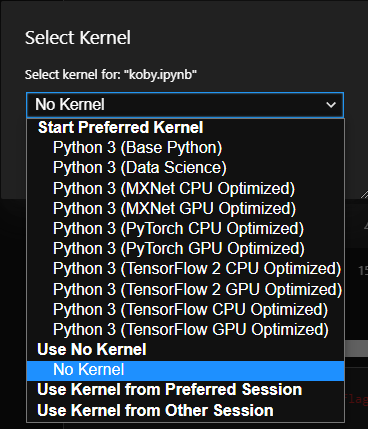
圖片來源于亞馬遜云科技全球網站截圖
這里鏡像的概念在Jupyter Notebook的上下文里,其實是一個個單獨的Jupyter Kernel,可以隨時進行切換,這里的鏡像也都是隨時可以切換的。跟標準版本Jupyter Notebook里切換Kernel是一個概念。
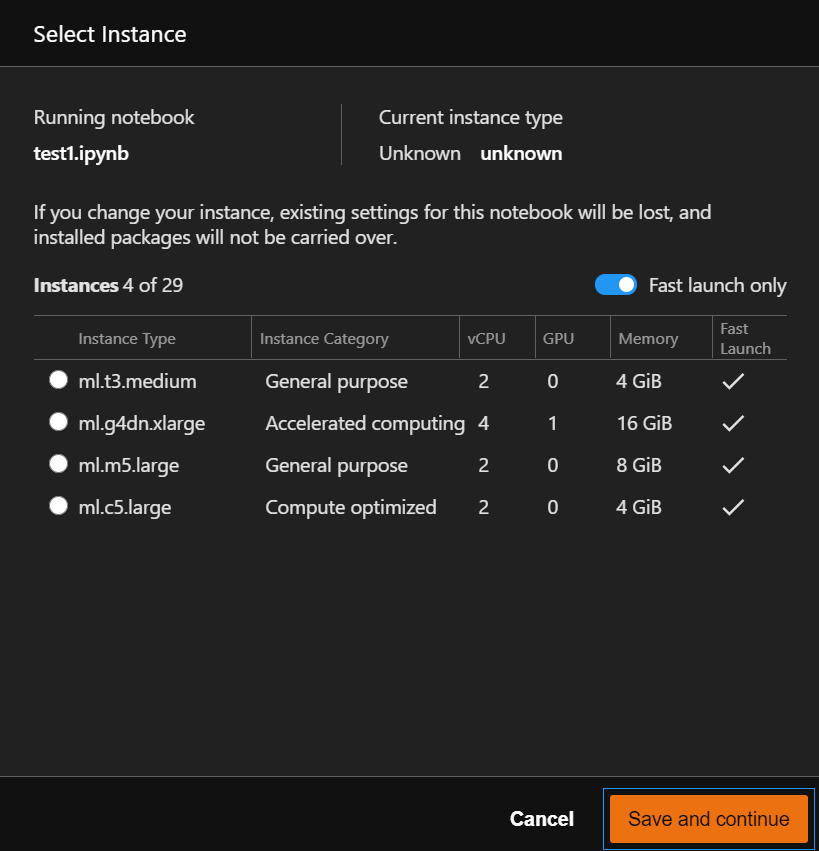
Amazon SageMaker Studio不僅可以隨時切換Kernel,還可以隨時修改主機配置,如上圖所示,列出的四個是支持快速切換的主機,另外還有25個主機配置的啟動速度稍慢。本地原生的Jupyter不支持這一操作,這是Amazon SageMaker Studio獨有的優勢。
每次新打開一個Notebook的時候,都需要單獨配置Kernel和主機,當不需要的時候,可以隨時shut down,也就不再計費了,也就是我們所說的召之即來揮之即去。
至此,我們的開發環境就準備好了。
(2)訓練過程的記錄和回溯——Experiments
Amazon SageMaker Studio最突出的能力是能解決機器學習過程中許多繁瑣的問題,我們接下來通過一系列操作介紹這些新的功能。
我們通過創建一個AutoML實驗來看:
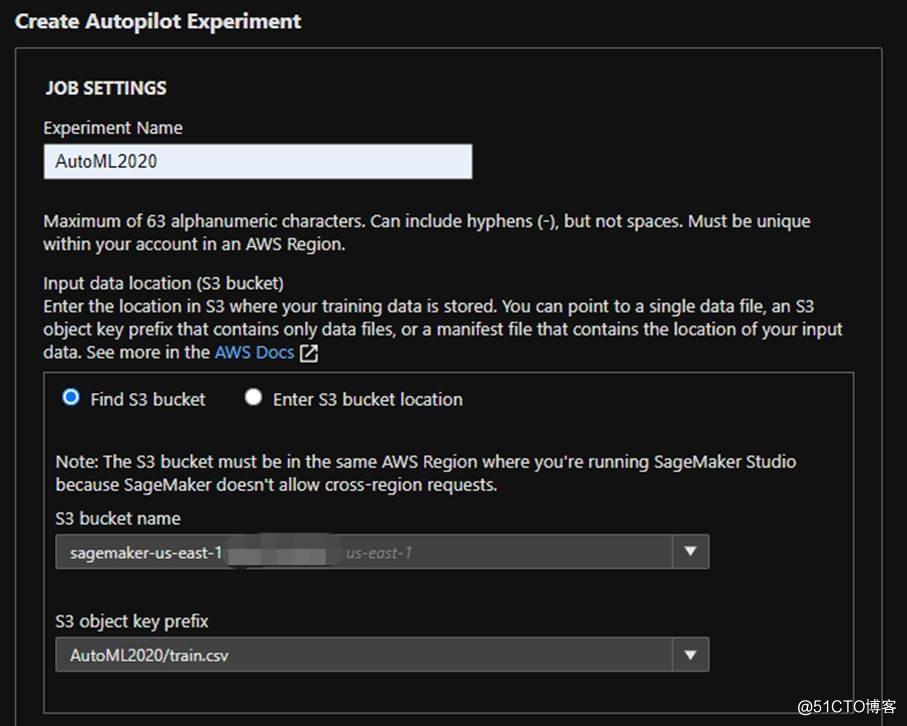
圖片來源于亞馬遜云科技全球網站截圖
將準備好的訓練數據傳到s3上,選擇Bucket的名字,還有文件train.csv。這里使用的訓練數據從Kaggle上下載來的,是泰坦尼克乘客救援情況數據。
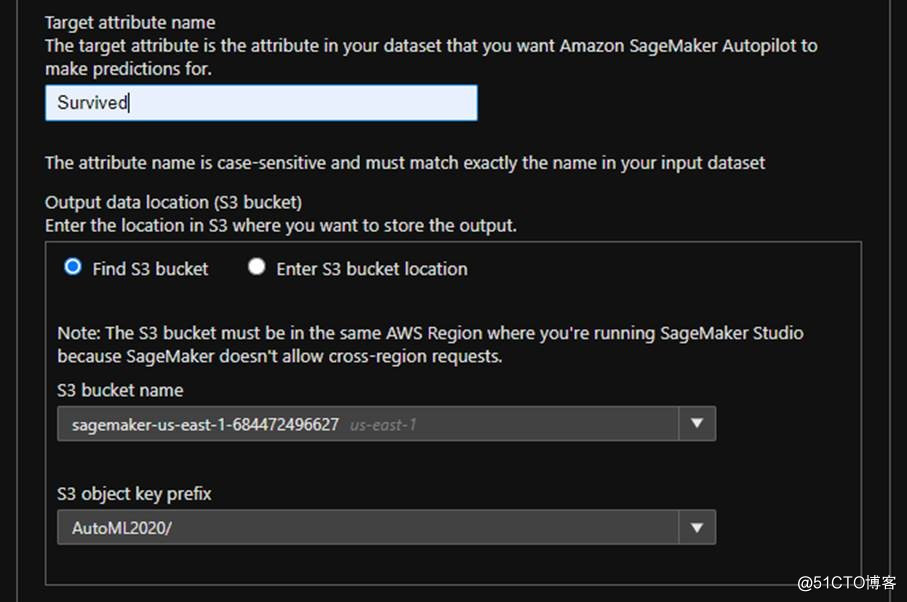
圖片來源于亞馬遜云科技全球網站截圖
然后,選擇要預測的參數是哪一列,這里選擇的是Survived,就是看一個人是否獲救了。
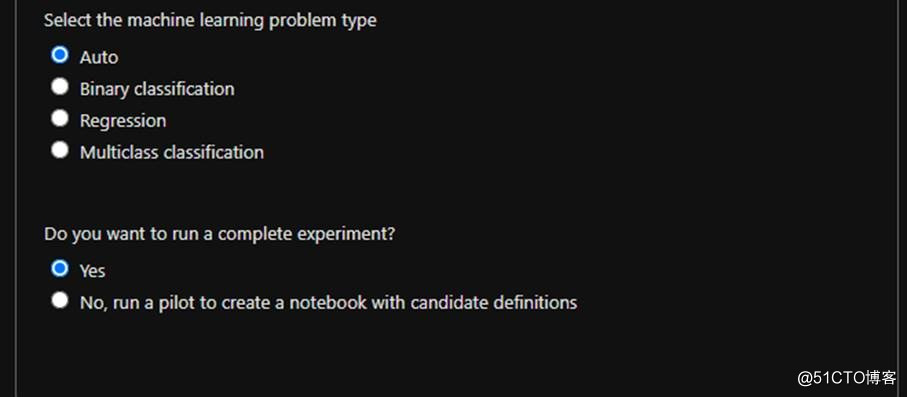
圖片來源于亞馬遜云科技全球網站截圖
然后選擇我們要處理的是什么問題,而不用選擇具體的算法,可以指出是分類還是回歸,是二分類還是多分類任務,是否需要一個完整的實驗,默認選項即可,最后點擊創建,自動化的機器學習就開始了。
圖片來源于亞馬遜云科技全球網站截圖
從分析數據開始,然后進入特征提取工程階段,模型調優階段,最后就完成了,過程耗時較長,需要亞馬遜云科技自己的機器學習平臺來完成的所有操作,比如,訓練數據集、驗證數據集、還有測試數據及的劃分,算法的選擇,超參數的優化等等,所有操作交給亞馬遜云科技來完成。
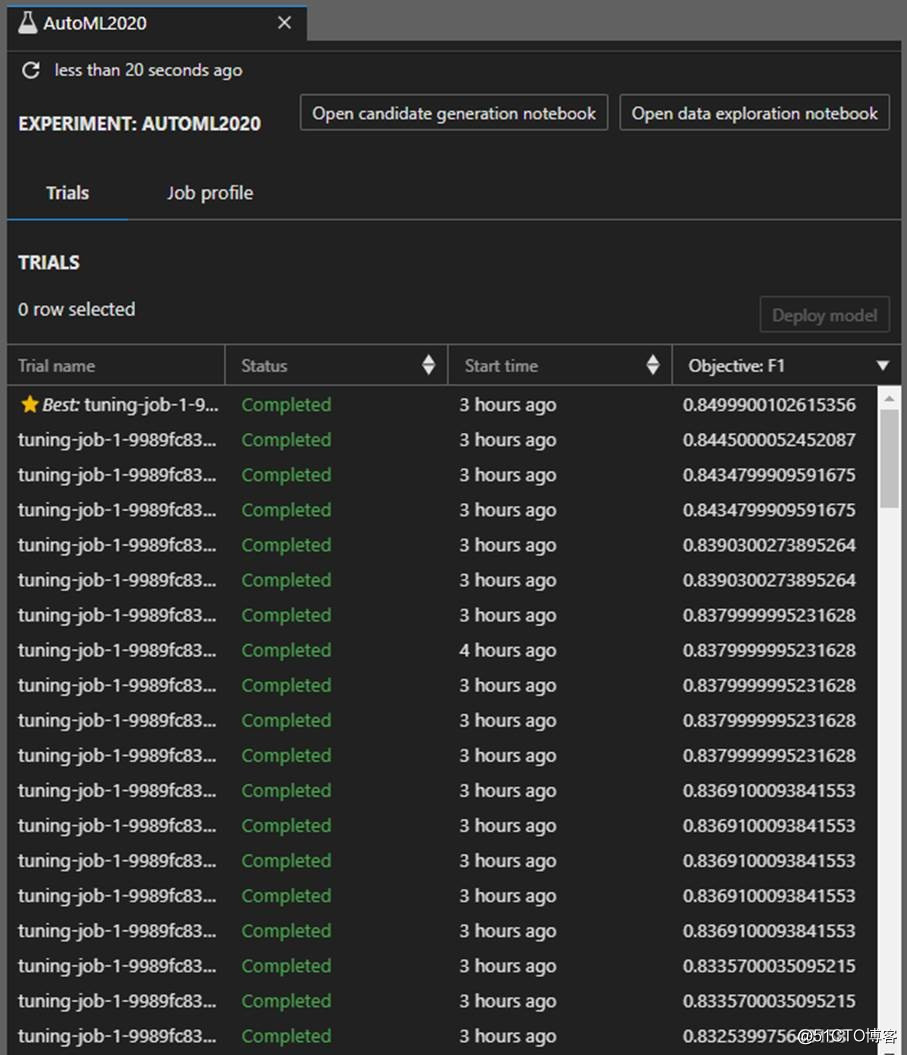
圖片來源于亞馬遜云科技全球網站截圖
經過一個小時,經過數不清多少次的嘗試后,系統能找到表現最好的那次嘗試(如上圖星標所示),上圖只展示了二十來個Tuning job(可譯作調優負載),每個Tuning job對應一個訓練出來的模型。
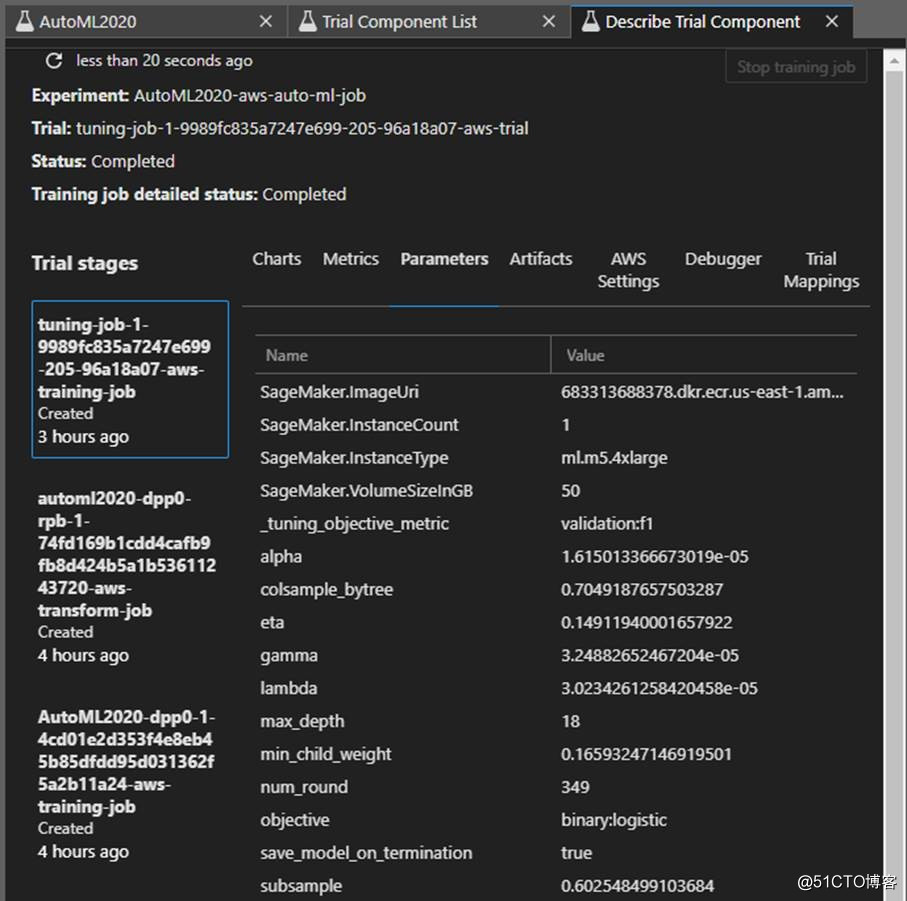
圖片來源于亞馬遜云科技全球網站截圖
整個訓練過程都有記錄,如上圖所示,可以查看某次實驗嘗試使用的一些參數,看到更多關于訓練過程,訓練模型相關的更多細節。
這些嘗試都是自動進行的,而在實際訓練當中,可能會有數不清次數的嘗試,手動記錄不太現實,而且容易錯亂,SageMaker Experiments可以隨時記錄和查看這些過程。
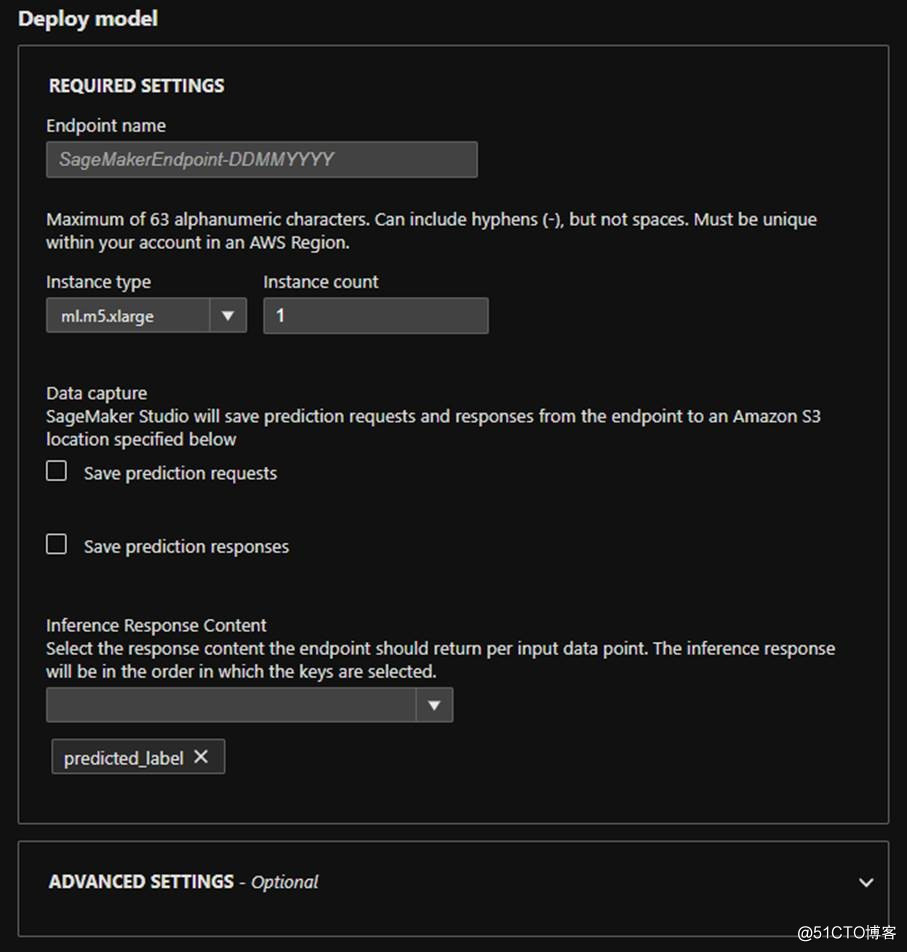
圖片來源于亞馬遜云科技全球網站截圖
找到最滿意的那次嘗試后,可以通過一些簡單的設置完成最后的部署。
(3)自動化的超參數調優Hyperparameter Tuning與自動化的機器學習 Autopilot
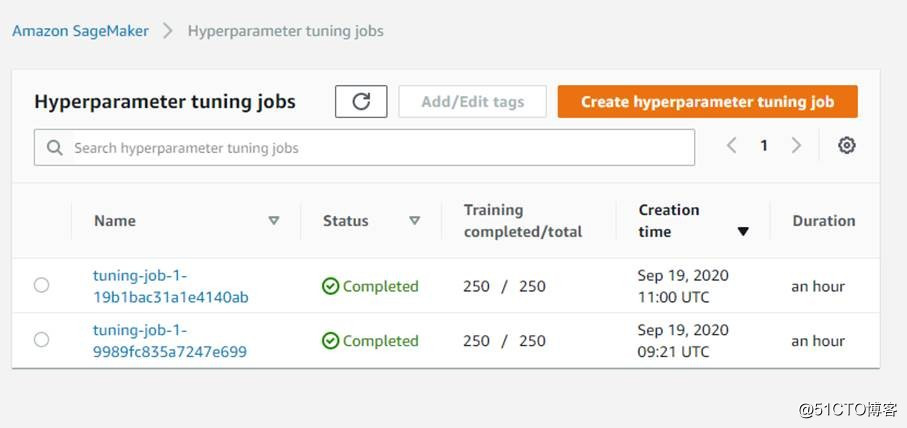
圖片來源于亞馬遜云科技全球網站截圖
上文提到了超參數優化(hyperparameter tuning job)的操作,其實在Amazon SageMaker的控制臺窗口也可以自己創建自動化的超參數優化負載,如上圖,我們剛才自動化的機器學習過程中也會創建這樣的任務。
可見,自動化機器學習的部分工作任務也是靠自動化的超參數優化。不過,自動化機器學習更高級一些,還會自動挑選算法,會自行設定超參數優化的一些參數。當手動創建超參數優化負載的時候,這些都需要機器學習專家自己手動設置。
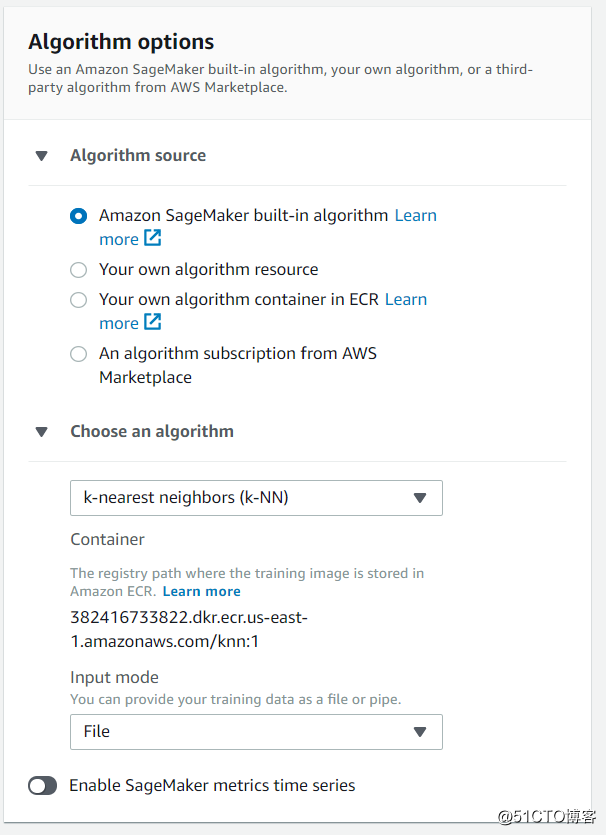
圖片來源于亞馬遜云科技全球網站截圖
創建超參數優化負載的關鍵是選擇算法,可以用Amazon SageMaker自帶的算法,也可以用自己創建的算法。
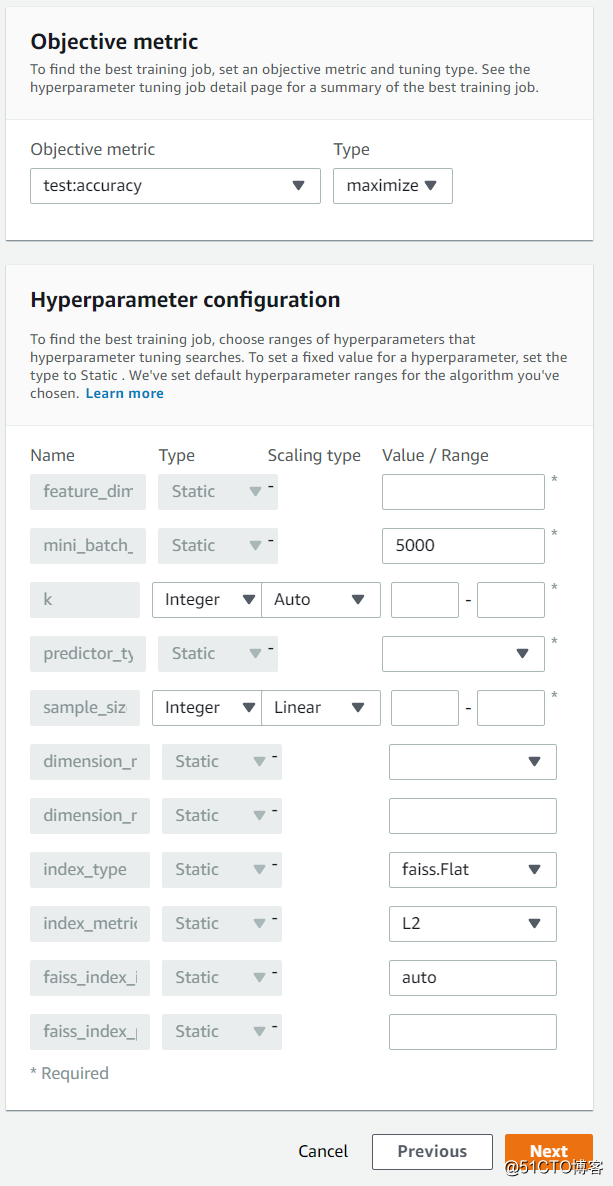
圖片來源于亞馬遜云科技全球網站截圖
配置算法對應的超參數,設定待優化的目標值,這里設置的是準確度。
Amazon SageMaker的超參數優化功能自動調參,省去人力手工操作的麻煩,而且能同時啟用多個訓練任務來節省時間,還能設置使用Spot實例來節省費用。
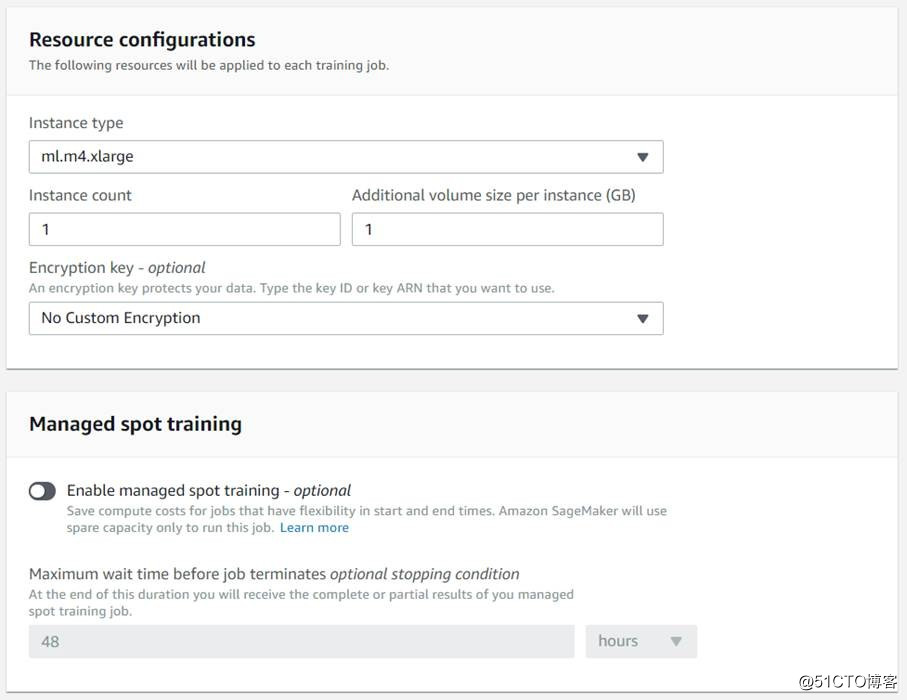
圖片來源于亞馬遜云科技全球網站截圖
任務完成后,可以得到配置好的一組超參數組合,用于后續的訓練。
(4)訓練階段的Debugger
自動化的機器學習雖然很方便,但由于支持場景相對有限,而且,訓練過程相對不那么透明,因此雖然SageMaker Experiments能記錄訓練的過程固然有幫助,但大多數時候還是需要手寫代碼來完成訓練過程的。
Amazon SageMaker Studio可以Debug模型訓練過程,一直以來,機器學習的訓練過程可見度都很低,基本處于黑盒狀態,常見的只能看見loss和accuracy值,其他部分的能見度比較低。
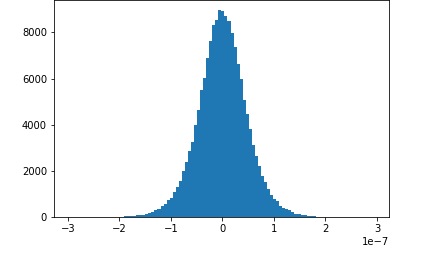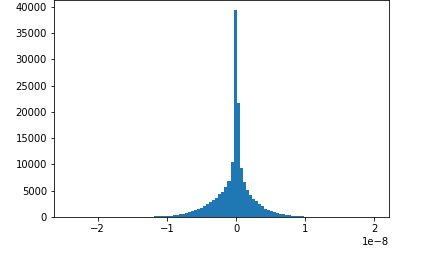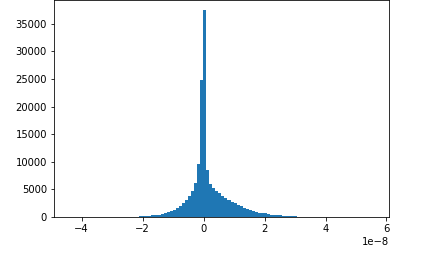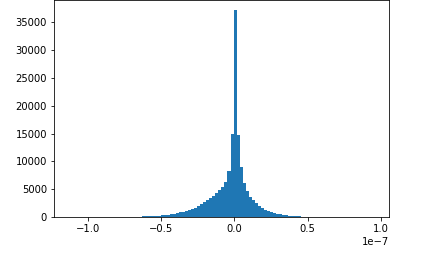
圖片來源于亞馬遜云科技全球網站截圖
在訓練階段,使用Amazon SageMaker SDK還可以監控模型的訓練過程,比如上圖中顯示的是在訓練過程中卷積層的梯度分布,開始是高斯分布,但后來梯度的范圍越來越小,這時候就需要修改超參數了,如果能在訓練的時候就發現這一問題,就不用等到訓練完成后再修改了。
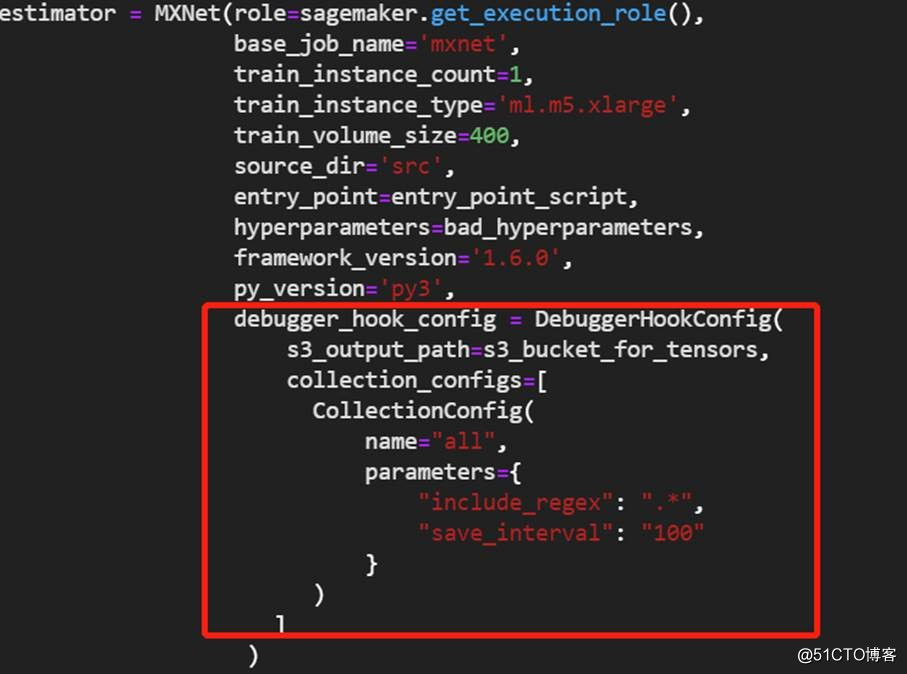
圖片來源于亞馬遜云科技全球網站截圖
SageMaker Debugger工具使用起來其實也比較簡單,如上圖所示,在實際代碼中,設置estimator的時候,需要多添加幾個配置參數即可獲取到訓練時候的一些Tensor數據,獲取數據后就可以進行一些展示。
(5)監控模型運行效果
圖片來源于亞馬遜云科技全球網站截圖
在實際生產過程中,部署并不是最后一個環節,而只是許多工作的開始,Amazon SageMaker可以提供線上模型監控能力,監控模型運行的狀況,如果數據發生變化,導致模型適用性有偏差,則需要重新訓練,這在亞馬遜云科技上可以通過構建Pipeline來實現。
(6)分享協作
圖片來源于亞馬遜云科技全球網站截圖
機器學習的過程難免會有些問題,把賬號分享給別人也不太現實,為了便于分享協作,Amazon SageMaker Studio在每個Notebook的右上角都添加了分享按鈕。
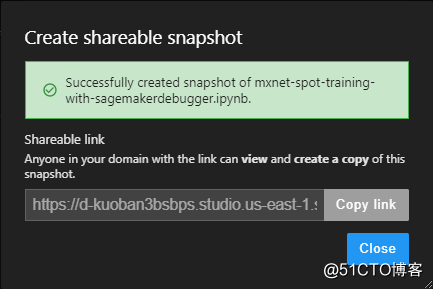
圖片來源于亞馬遜云科技全球網站截圖
在創建Amazon SageMaker Studio的時候需要設置domain,在同一個domain下的用戶可以共享協作,比如在公司內部跟同事做分享,接受分享的用戶看到的所有內容與分享者看到的是完全一樣的,便于協作共享,無需額外配置,這點是本地機器學習環境中絕對做不到的。
(7)資源控制
Amazon SageMaker所有的資源都可以在控制臺看到并進行管理,如果只是實驗階段的話,建議在嘗試之后關掉相關資源來管理成本,在生產環境中,可以清楚看到各種資源的用量并進行管理,使得整體成本更容易控制。
四、總結評估
Amazon SageMaker上可以完成全流程的訓練,我們也可以將原有的模型部署到Amazon SageMaker的endpoint服務器上,如果也不想自己訓練模型,可以直接用亞馬遜云科技以SaaS方式提供的AI能力,還可以在Marketplace上拿別人模型來用。
Amazon SageMaker側重的是訓練、調優和部署階段的能力,可以降本增效。一方面,Amazon SageMaker可以使用Spot Instance來降低成本;另一方面,如果只想在云上部署模型,也可以直接使用Elastic Inference降低模型部署后的推理成本。而在效率提升方面,Amazon SageMaker Experiments、自動化的機器學習能力、還有各種規格的云上資源等,都能提升效率。
最后需要說明的是,亞馬遜云科技的云上人工智能/機器學習棧是一個完整的系列,上中下一共由三個層次構成。本次評估中談到的Amazon SageMaker只是中間一層的“機器學習服務層”。在其之下的底層,提供的是對各類框架的支持、對CPU/GPU的彈性支持等基礎算力方面的服務。

圖片來源于亞馬遜云科技全球網站截圖
比如用戶單純想將本地的訓練搬到云上,也可以不使用完全托管的Amazon SageMaker而可以用EC2以及一個支持TensorFlow、PyTorch,MXNET的Linux鏡像(雖然這可能給后續機器學習的開發帶來更多額外工作)。
在中間層SageMaker之上的,是“AI服務層”,提供了許多易用的AI服務,比如用于圖像及視頻分析的Amazon Rekognition, 用于文檔內容識別的OCR工具Amazon Traxtract, 用于翻譯的Amazon Translate, 用于文字轉語音的Amazon Polly, 用于金融反欺詐的Amazon Fraud Detection, 用于碼農優化代碼的Amazon CodeGuru……, 等等。
這些應用導向的AI服務的提供,極大方便了AI在各類企業應用中的推廣。(具體可參考https://amazonaws-china.com/cn/machine-learning/ai-services/ )