













回歸根基:5篇必讀的數據科學論文,幫你保持領先地位
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
這篇文章涵蓋了幾個最重要的新近發展和最具影響力的觀點,涵蓋的話題從數據科學工作流的編制到更快神經網絡的突破,再到用統計學基本方法解決問題的再思考,同時也提供了將這些想法運用到工作中去的方法。
1. 機器學習系統中隱藏的技術債(Hidden Technical Debt in Machine LearningSystems)
鏈接:
https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
谷歌研究團隊提供了在創建數據科學工作流時要避免的反模式的明確說明。這篇論文把技術債的隱喻從軟件工程借鑒過來,將其應用于數據科學。

圖源:DataBricks
下一篇論文更加詳細地探討了構建一個機器學習產品是軟件工程下面一個專門的分支,這個學科中的許多經驗也會運用到數據科學中。
如何使用:遵照專家提出的實用技巧簡化開發和生產。
2. 軟件2.0( Software 2.0)
鏈接:https://medium.com/@karpathy/software-2-0-a64152b37c35
安德烈·卡帕斯(Andrej Karpathy)的經典文章明確表達了一個范式,即機器學習模型是代碼基于數據的軟件運用。如果數據科學就是軟件,我們所構建的會是什么呢?Ben Bengafort在一篇極有影響力的博文“數據產品的時代”中探討了這個問題。
(https://districtdatalabs.silvrback.com/the-age-of-the-data-product)
數據產品代表了ML項目的運作化階段。
如何使用:學習更多有關數據產品如何融入模型選擇過程的內容。
3. BERT:語言理解深度雙向轉換的預訓練(BERT: Pre-training of DeepBidirectional Transformers for Language Understanding)
鏈接:https://arxiv.org/abs/1810.04805
這篇論文里,谷歌研究團隊提出了自然語言處理模型,代表了文本分析方面能力的大幅提升。雖然關于BERT為什么如此有效存在一些爭議,但這也提示了我們機器學習領域會發現一些沒有完全了解其工作方式的成功方法。像大自然一樣,人工神經網絡還浸沒在神秘之中。
如何使用:
- BERT論文可讀性很強,包括了一些建議在初始階段使用的默認超參數設置。
- 不管你是否為NLP新手,請去看看Jay Alammar闡釋BERT性能的“BERT的初次使用視圖指南”。
- 也請看看ktrain——一個運用于Keras的組件(同時也運用于TensorFlow),能夠幫助你在工作中毫不費力地執行BERT。Arun Maiya開發了這個強大的庫來提升NLP、圖像識別和圖論方法的認知速度。
4. 彩票假說:找到稀疏且可訓練的神經網絡(The Lottery Ticket Hypothesis:Finding Sparse, Trainable Neural Networks)
鏈接:https://arxiv.org/abs/1803.03635
當NLP模型變得越來越大(看GTP-3的1750億個參數),人們努力用正交的方式構建一個更小、更快、更有效的神經網絡。這樣的網絡花費更短的運營時間、更低的訓練成本和對計算資源更少的需求。
在這篇開創性的論文里,機器學習天才Jonathan Frankle和Michael Carbin概述了顯示稀疏子網絡的裁剪方法,可以在最初明顯增大的神經網絡中實現類似的性能。
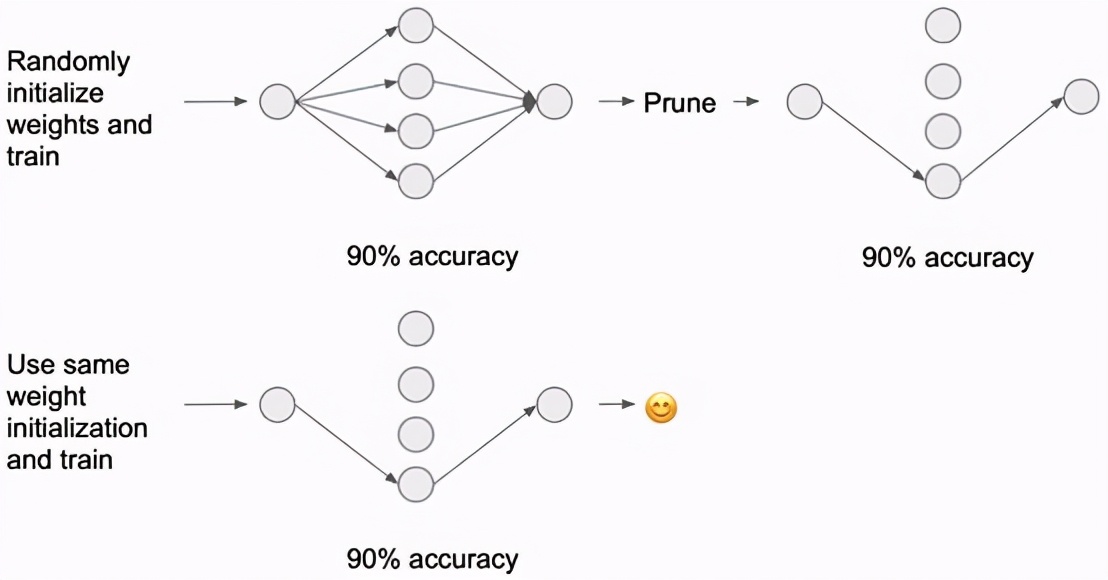
Nolan Day的“彩票分解假說”
彩票指的是與效能十分強大的聯系。這個發現提供了許多在儲存、運行時間和計算性能方面的優勢,并獲得了ICLR 2019的最佳論文獎。更深入的研究都建立在這項技術之上,證實了它的適用性并應用于原始稀疏網絡。
如何使用:
- 在生產前先考慮刪減神經網絡。刪減網絡權重可以減少90%以上的參數,卻仍能達到與初始網絡相同的性能。
- 同時查看Ben Lorica向Neural Magic講述的數據交換播客片段,這是一個尋求在靈活的用戶界面上利用類似修剪和量化的技術簡化稀疏性獲取的開端。(https://neuralmagic.com/about/)
5. 松開零假設統計檢驗的死亡之手(p < .05)(Releasing the death-grip of nullhypothesis statistical testing (p < .05) )
鏈接:
https://www.researchgate.net/publication/312395254_Releasing_the_death-grip_of_null_hypothesis_statistical_testing_p_05_Applying_complexity_theory_and_somewhat_precise_outcome_testing_SPOT
假設檢驗的提出早于計算機的使用。考慮到與這個方法相關聯的挑戰(例如甚至是統計員都覺得解釋p值近乎不可能),也許需要時間來想出類似稍精確結果檢驗(SPOT)的替代方法

xkcd的顯著性
如何使用:查看這篇“假設統計檢驗之死”的博文,一位沮喪的統計員概述了一些與傳統方法相關的挑戰,并解釋了利用置信區間的替代方式。
(https://www.datasciencecentral.com/profiles/blogs/the-death-of-the-statistical-test-of-hypothesis)
這5篇論文能幫助你更深入地認識數據科學!











