搜代碼,再也不用上谷歌復制粘貼了
先問大家一個問題,如果你擼代碼的過程中遇到了一個問題不知道怎么解決,你一般會怎么辦?

那當然是搜了,去哪里搜呢?
比如這里我就想知道 Python 里面怎么使用 requests 怎么上傳文件,我可能就直接 Google 一下,結果有很多,比如官方文檔,Stack Overflow 等等,然后一個個去查。
比如我可能就會輸入關鍵詞 python requests upload file,查到的結果類似如下:
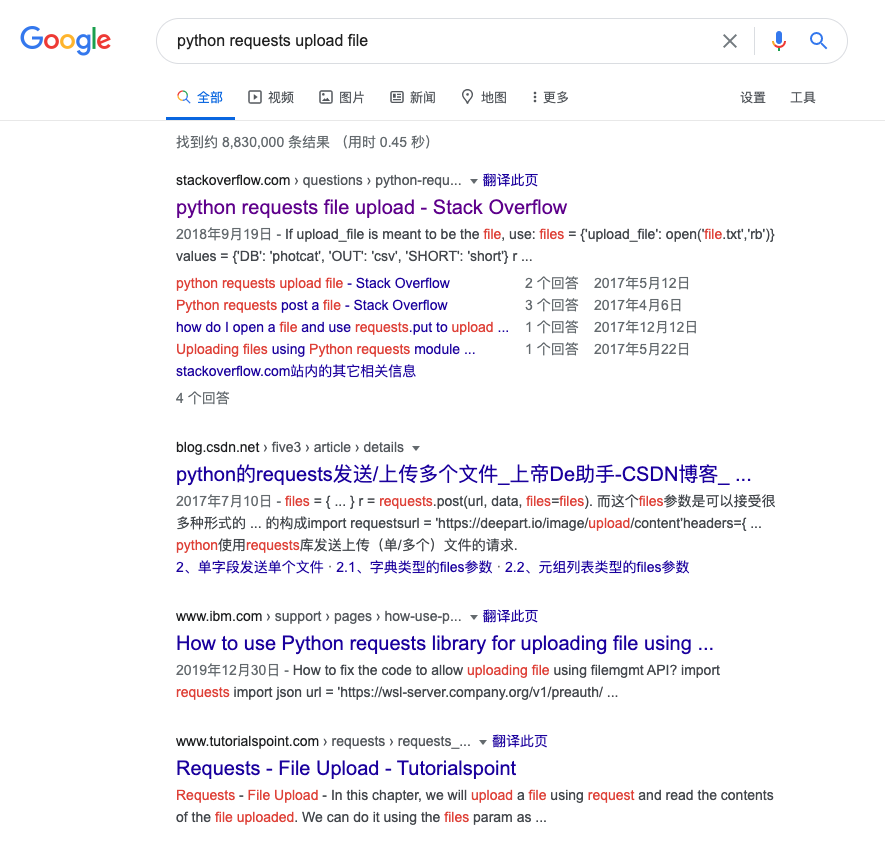
這里給我的第一個結果是 Stack Overflow,結果鏈接為 https://stackoverflow.com/questions/22567306/python-requests-file-upload,我把它點開,然后找到最高票的答案。
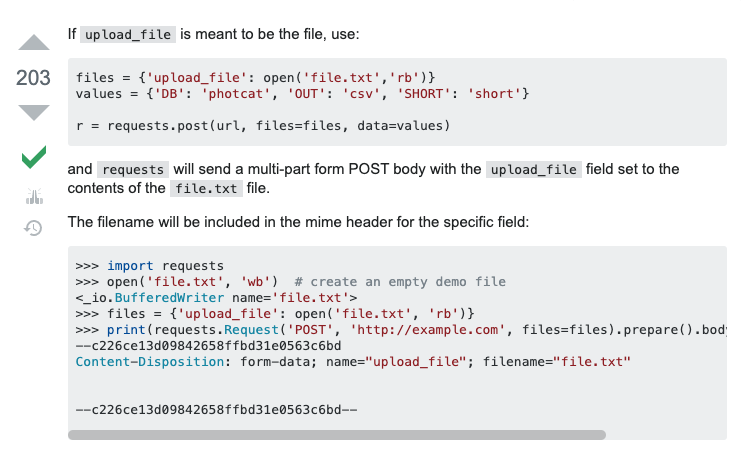
這里最高票的答案如圖瑣事,然后把它的代碼 copy 下來試試看看,然后就跑通了。
不過似乎還是有一點麻煩的?開瀏覽器,開 Google 或 Stack Overflow,找最高票答案試試。
介紹
今天給大家介紹一個神器,叫做 howdoi,有了它,似乎我們就可以告別 Stack Overflow 了。
下面我們就先來看看 howdoi 能做點什么,安裝了之后,我們就能直接輸入這樣的命令,比如:
- howdoi python requests upload file
它給我的返回結果就是這樣:
- files = {'upload_file': open('file.txt','rb')}values = {'DB': 'photcat', 'OUT': 'csv', 'SHORT': 'short'}
- r = requests.post(url, files=files, data=values)
比如我想搜 python 怎么發送 POST 請求,輸入這樣的命令:
- howdoi python requests post
返回結果就是這樣:
- >>> importrequests>>> r = requests.post('http://httpbin.org/post', json={"key": "value"})>>> r.status_code200>>> r.json{'args': {}, 'data': '{"key": "value"}', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', 'Content-Length': '16', 'Content-Type': 'application/json', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.4.3 CPython/3.4.0', 'X-Request-Id': 'xx-xx-xx'}, 'json': {'key': 'value'}, 'origin': 'x.x.x.x', 'url': 'http://httpbin.org/post'}
看起來還不錯對不對。
比如我想搜 Python 里面怎么把 timestamp 轉 datetime,輸入這樣的命令:
- howdoi python timestamp to datetime
返回結果就是這樣:
- fromdatetimeimportdatetimets = int("1284101485")
- # if you encounter a "year is out of range" error the timestamp# may be in milliseconds, try `ts /= 1000` in that caseprint(datetime.utcfromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S'))
那 Java 它會嗎?試試看:
- howdoi java timestamp to datetime
返回結果就是這樣:
- Timestampstamp =newTimestamp(System.currentTimeMillis);Datedate =newDate(stamp.getTime);System.out.println(date);
有點牛逼啊,搜啥答案都有,準確率還蠻高。
以上是怎么實現的?沒錯,就是借助于 howdoi 這個項目。
howdoi
那么這個 howdoi 究竟是個什么?我們 GitHub 上就能找到,鏈接地址為:https://github.com/gleitz/howdoi。
看下簡介:
Are you a hack programmer? Do you find yourself constantly Googling for how to do basic programming tasks?
Suppose you want to know how to format a date in bash. Why open your browser and read through blogs (risking major distraction) when you can simply stay in the console and ask howdoi.
意思就是說,如果你想搜一些編程相關的解決方案,我們可以不用再去開瀏覽器,然后再去讀文檔或者博客,你可以通過 howdoi 就能直接得到答案。
操作就是上面我們講的。
howdoi 是一個 Python 項目,我們可以 pip 命令安裝:
- pip3 install howdoi
如果是 Mac 的話,推薦使用 brew 來安裝:
- brew install howdoi
安裝完了就能使用 howdoi 命令了。
完整用法如下:
- usage: howdoi.py [-h] [-p POS] [-a] [-l] [-c] [-j] [-n NUM_ANSWERS] [-C] [-v] [-e ENGINE] QUERY [QUERY ...]
- instant coding answers via the command line
- positional arguments: QUERY the question to answer
- optional arguments: -h, --help show thishelp messageandexit -p POS, --pos POS selectanswerinspecified position (default:1) -a, --all display the full text of the answer -l, --link display only the answer link -c, --color enable colorized output -j, --json-output returnanswersinraw json format, to prettyprinttry'howdoi pretty print json command line' -n NUM_ANSWERS, --num-answers NUM_ANSWERS number of answers to return -C, --clear-cache clear the cache -v, --version displays the current version of howdoi -e ENGINE, --engine ENGINE change search engine forthisquery only.Currentlysupported engines: google (default), bing, duckduckgo.
但一般來說就按照前文所演示的直接輸入問題就行了。
比如看看怎樣在 Python 中打印 traceback,這么搜:
- howdoi printstack trace python
結果如下:
- importtraceback
- try: raiseTypeError("Oups!")exceptException, err: try: raiseTypeError("Again !?!") except: pass
- traceback.print_exc
不錯不錯。
原理
這時候大家可能就有疑問了,這到底是怎么實現的?為什么還能這么精準。
其實看下源碼就知道了,我們稍微扒下看看,其實源碼就都在這里了:https://github.com/gleitz/howdoi/blob/master/howdoi/howdoi.py。
先看看一上來定義了這么多:
- SUPPORTED_SEARCH_ENGINES = ('google', 'bing', 'duckduckgo')
- URL = os.getenv('HOWDOI_URL') or'stackoverflow.com'
- USER_AGENTS = ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10.7; rv:11.0) Gecko/20100101 Firefox/11.0', 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100 101 Firefox/22.0', 'Mozilla/5.0 (Windows NT 6.1; rv:11.0) Gecko/20100101 Firefox/11.0', ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/536.5 (KHTML, like Gecko) ' 'Chrome/19.0.1084.46 Safari/536.5'), ('Mozilla/5.0 (Windows; Windows NT 6.1) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.46' 'Safari/536.5'), )SEARCH_URLS = { 'bing': SCHEME + 'www.bing.com/search?q=site:{0}%20{1}&hl=en', 'google': SCHEME + 'www.google.com/search?q=site:{0}%20{1}&hl=en', 'duckduckgo': SCHEME + 'duckduckgo.com/?q=site:{0}%20{1}&t=hj&ia=web'}
- 貌似我們就懂了什么,這些答案是從搜索引擎得來的。
然后我們再扒一扒,又看到一個關鍵的 _get_result 方法,定義如下:
- def_get_result(url): try: returnhowdoi_session.get(url, headers={'User-Agent': _random_choice(USER_AGENTS)}, proxies=get_proxies, verify=VERIFY_SSL_CERTIFICATE).text exceptrequests.exceptions.SSLErrorase: _print_err('Encountered an SSL Error. Try using HTTP instead of ' 'HTTPS by setting the environment variable "HOWDOI_DISABLE_SSL".\n') raisee
看到了吧,這里就是一次 requests 發起了 get 請求,那么這個 url 究竟是怎么來的呢?我們再順著找下調用 _get_result 方法的地方:
- def_get_links(query): search_engine = os.getenv('HOWDOI_SEARCH_ENGINE', 'google') search_url = _get_search_url(search_engine)
- result = _get_result(search_url.format(URL, url_quote(query))) if_is_blocked(result): _print_err('Unable to find an answer because the search engine temporarily blocked the request. Please wait a few minutes or select a different search engine.') raiseBlockError("Temporary block by search engine")
- html = pq(result) return_extract_links(html, search_engine)
這里就是 _get_links 方法調用了 _get_result 方法,就是 search_url 的格式化結果,傳入了 URL 還有 query,其中 search_url 是 _get_search_url 方法傳入了 search_engine,search_engine 是通過環境變量 HOWDOI_SEARCH_ENGINE 獲取的,默認是 google。
好,那順著再看看 _get_search_url 的實現,定義如下:
- def_get_search_url(search_engine): returnSEARCH_URLS.get(search_engine, SEARCH_URLS['google'])
很明顯了,就是 SEARCH_URLS 里面定義的,所以最后,我們就可以得到如下的搜索 URL:
- www.google.com/search?q=site:stackoverflow.com%20{query}&hl=en
這里 query 就是我們搜索的內容,比如搜索 print stack trace python,構造的 URL 就是:
- https://www.google.com/search?q=site:stackoverflow.com%20print%20stack%20trace%20python&hl=en
我們訪問一下就是這樣的結果:
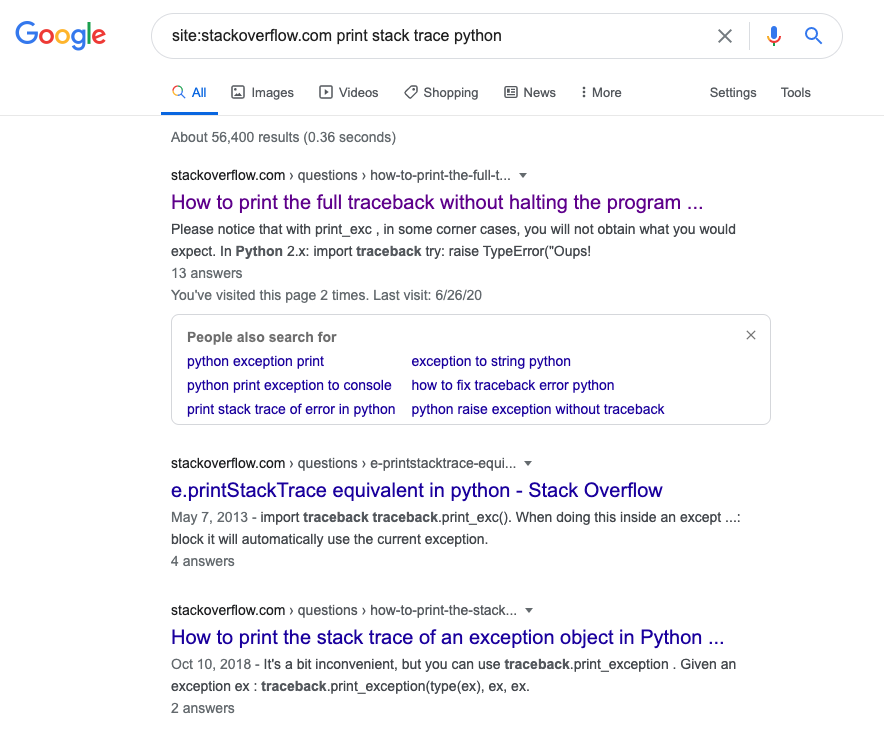
其實這就是借助 Google 搜索了 Stack Overflow 的內容,搜索了 python 關鍵字的內容。
然后 howdoi 就是提取了其中的 TOP 答案,然后解析一下返回即可。