













并發編程從操作系統底層工作整體認識開始
前言
在多線程、多處理器、分布式環境的編程時代,并發是一個不可回避的問題。既然并發問題擺在面前一個到無法回避的坎,倒不如擁抱它,把它搞清楚,花一定的時間從操作系統底層原理到Java的基礎編程再到分布式環境等幾個方面深入探索并發問題。先就從原理開始吧。
計算機系統層次結構
早期計算機系統的層次
最早的計算機用機器語言編程,機器語言稱為第一代程序設計語言

匯編語言編程
匯編語言編程

現代(傳統)計算機系統的層次
現代計算機用高級語言編程
- 第三代程序設計語言(3GL)為過程式 語言,編碼時需要描述實現過程,即“ 如何做”。
- 第四代程序設計語言(4GL) 為非過程 化語言,編碼時只需說明“做什么”, 不需要描述具體的算法實現細節。

語言處理系統包括:各種語言處理程序(如編譯、匯編、 鏈接)、運行時系統(如庫函數,調試、優化等功能)
操作系統包括人機交互界面、 提供服務功能的內核例程
可以看出:語言的發展是一 個不斷“抽象”的過程,因而,相應的計算機系統也不斷有新的層次出現。
計算機系統抽象層的轉換
功能轉換:上層是下層的抽象,下層是上層的實現 底層為上層提供支撐環境!
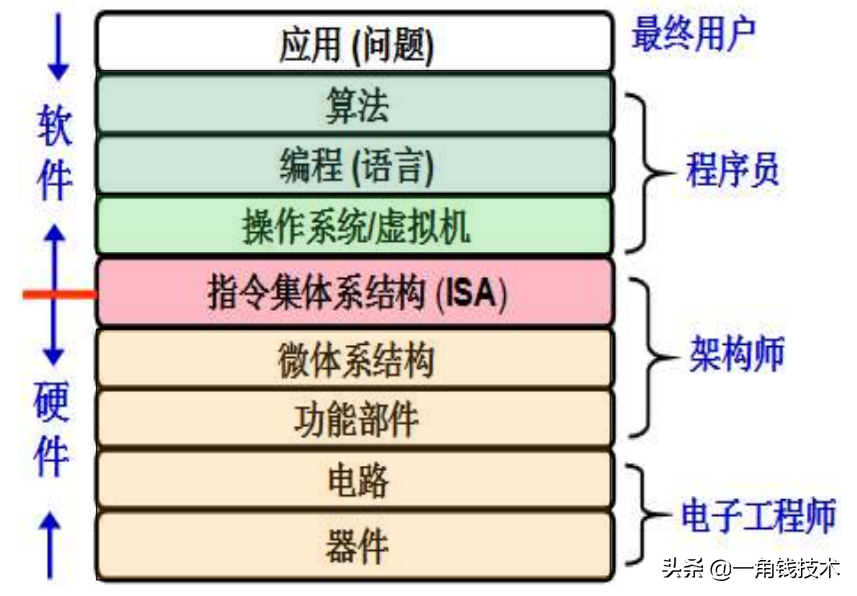
計算機系統的不同用戶
- 最終用戶工作在由應用程序提供的最上面的抽象層
- 系統管理員工作在由操作系統提供的抽象層
- 應用程序員工作在由語言處理系統(主要有編譯器和匯編器)的抽象層
- 語言處理系統建立在操作系統之上
- 系統程序員(實現系統軟件)工作在ISA層次,必須對ISA非常了解
編譯器和匯編器的目標程序由機器級代碼組成
操作系統通過指令直接對硬件進行編程控制ISA處于軟件和硬件的交界面(接口)
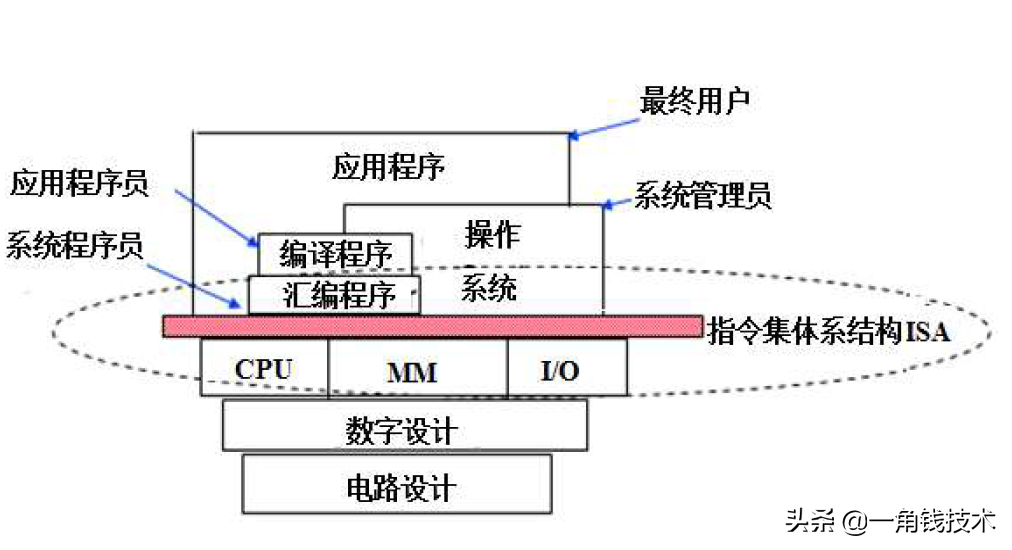
ISA是對硬件的抽象所有軟件功能都建立在ISA之上
指令集體系結構(ISA)
ISA指 Instruction Set Architecture,即指令集體系結構,有時簡稱為指令系統
- ISA是一種規約(Specification),它規定了如何使用硬件可執行的指令的集合,包括指令格式、操作種類以及每種操作對應的 操作數的相應規定;指令可以接受的操作數的類型;操作數所能存放的寄存器組的結構,包括每個寄存器的名稱、編號、 長度和用途;操作數所能存放的存儲空間的大小和編址方式;操作數在存儲空間存放時按照大端還是小端方式存放;指令獲取操作數的方式,即尋址方式;指令執行過程的控制方式,包括程序計數器(PC)、條件碼定義等。
- ISA在通用計算機系統中是必不可少的一個抽象層,沒有它,軟件無法使用計算機硬件!沒有它,一臺計算機不能稱為“通用計算機”
ISA和計算機組成(微結構)之間的關系
ISA是計算機組成的抽象,不同ISA規定的指令集不同
- 如,IA-32、MIPS、ARM等 計算機組成必須能夠實現ISA規定的功能
- 如提供GPR、標志、運算電路等 同一種ISA可以有不同的計算機組成
- 如乘法指令可用ALU或乘法器實現
現代計算機的原型
現代計算機模型是基于-馮諾依曼計算機模型
1946年,普林斯頓高等研究院(the Institute for Advance Study at Princeton,IAS )開始設計“存儲程序”計算機,被稱為IAS計算機.
- 馮·諾依曼結構最重要的思想是“存儲程序(Stored-program)”
- 工作方式:任何要計算機完成的工作都要先被編寫成程序,然后將程序和原始數據送入主存并啟動執行。一旦程序被啟動,計算機應能在不需操作人員干預下,自動完成逐條取出指令和執行指令的任務。馮·諾依曼結構計算機也稱為馮·諾依曼機器(Von Neumann Machine)。幾乎現代所有的通用計算機大都采用馮·諾依曼結構,因此,IAS計算機是現代計算機的原型機。
計算機在運行時,先從內存中取出第一條指令,通過控制器的譯碼,按指令的要求,從存儲器中取出數據進行指定的運算和邏輯操作等加工,然后再按地址把結果送到內存中去。接下來,再取出第二條指令,在控制器的指揮下完成規定操作。依此進行下去。直至遇到停止指令。
程序于數據一樣存貯,按程序編排的順序,一步一步地取出指令,自動地完成指令規定的操作是計算機最基本的工作模型。這一原理最初是由美籍匈牙利數學家馮.諾依曼于1945年提出來的,故稱為馮.諾依曼計算機模型。
馮·諾依曼結構是怎樣的?
- 有主存,用來存放程序和數據
- 一個自動逐條取 出指令的部件
- 具體執行指令 (即運算)的部件
- 程序由指令構成
- 指令描述如何對數據進 行處理
- 將程序和原始數據輸入計算機的部件
- 將運算結果輸出計算機的部件
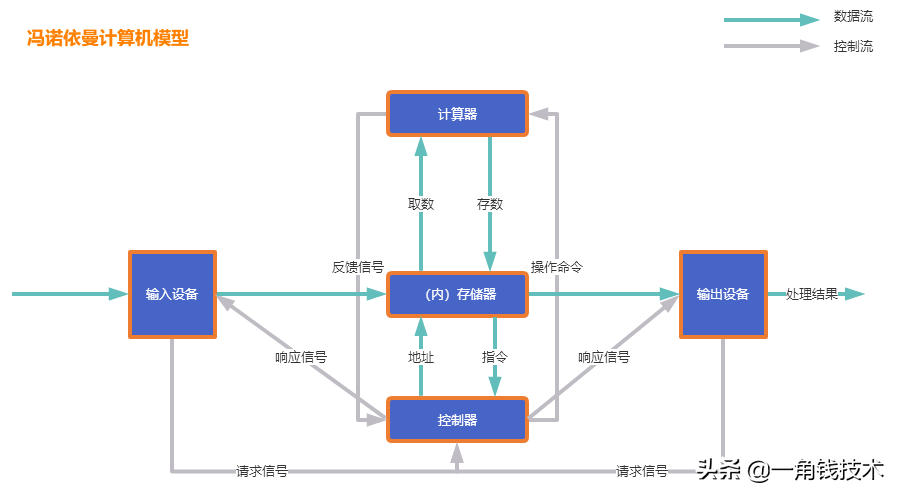
馮·諾依曼結構的主要思想
- 計算機應由計算器(運算器)、控制器、存儲器、輸入設備和輸出設備 五個基本部件組成。
- 各基本部件的功能是:控制器(Control):是整個計算機的中樞神經,其功能是對程序規定的控制信息進行解釋,根據其要求進行控制,調度程序、數據、地址,協調計算機各部分工作及內存與外設的訪問等。運算器(Datapath):運算器的功能是對數據進行各種算術運算和邏輯運算,即對數據進行加工處理。存儲器(Memory):存儲器的功能是存儲程序、數據和各種信號、命令等信息,并在需要時提供這些信息。輸入(Input system):輸入設備是計算機的重要組成部分,輸入設備與輸出設備合并為外部設備,簡稱外設,輸入設備的作用是將程序、原始數據、文字、字符、控制命令或現場采集的數據等信息輸入到計算機。常見的輸入設備有鍵盤、鼠標器、光電輸入機、磁帶機、磁盤機、光盤機等。輸出(Output system):輸出設備與輸入設備同樣是計算機的重要組成部分,它把外算機的中間結果或最后結果、機內的各種數據符號及文字或各種控制信號等信息輸出出來。微機常用的輸出設備有顯示終端CRT、打印機、激光印字機、繪圖儀及磁帶、光盤機等。
- 內部以二進制表示指令和數據。每條指令由操作碼和地址碼 兩部分組成。操作碼指出操作類型,地址碼指出操作數的地址。由一串指令組成程序。
- 采用“存儲程序”工作方式。
現代計算機結構模型
基于馮·諾依曼計算機理論的抽象簡化模型,它的具體應用就是現代計算機當中的硬件結構設計:
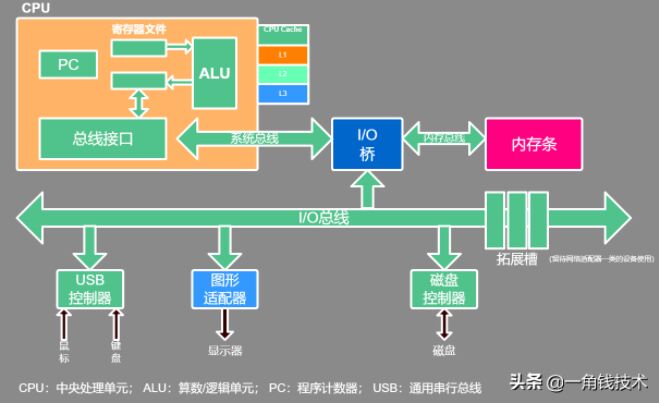
在上圖硬件結構當中,配件很多,但最核心的只有兩部分:CPU、內存。所以我們重點學習的也是這兩部分。
CPU:中央處理器;PC:程序計數器; MAR:存儲器地址寄存器 ALU:算術邏輯部件; IR:指令寄存器;MDR:存儲器數據寄存器 GPRs:通用寄存器組(由若干通用寄存器組成,早期就是累加器)
CPU指令結構
CPU內部結構
- 控制單元
- 運算單元
- 數據單元
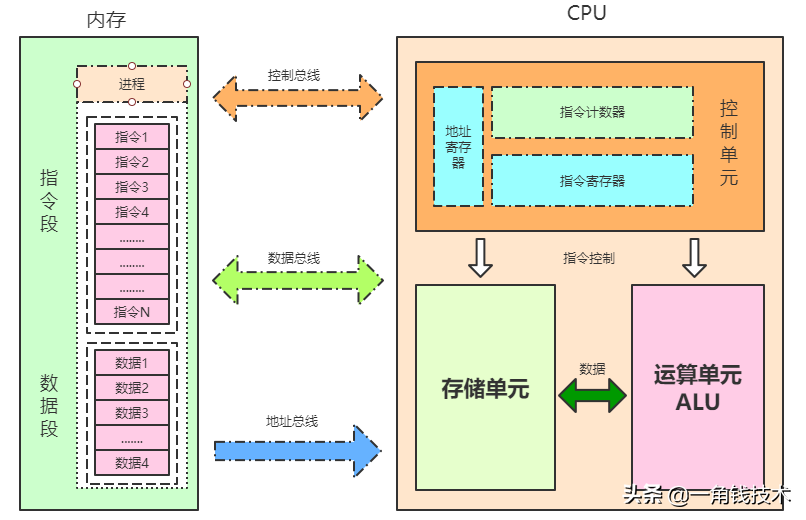
控制單元
控制單元是整個CPU的指揮控制中心,由指令寄存器IR(Instruction Register)、指令譯碼器ID(Instruction Decoder)和 操作控制器OC(Operation Controller) 等組成,對協調整個電腦有序工作極為重要。它根據用戶預先編好的程序,依次從存儲器中取出各條指令,放在指令寄存器IR中,通過指令譯碼(分析)確定應該進行什么操作,然后通過操作控制器OC,按確定的時序,向相應的部件發出微操作控制信號。操作控制器OC中主要包括:節拍脈沖發生器、控制矩陣、時鐘脈沖發生器、復位電路和啟停電路等控制邏輯。
運算單元
運算單元是運算器的核心。可以執行算術運算(包括加減乘數等基本運算及其附加運算)和邏輯運算(包括移位、邏輯測試或兩個值比較)。相對控制單元而言,運算器接受控制單元的命令而進行動作,即運算單元所進行的全部操作都是由控制單元發出的控制信號來指揮的,所以它是執行部件。
存儲單元
存儲單元包括 CPU 片內緩存Cache和寄存器組,是 CPU 中暫時存放數據的地方,里面保存著那些等待處理的數據,或已經處理過的數據,CPU 訪問寄存器所用的時間要比訪問內存的時間短。 寄存器是CPU內部的元件,寄存器擁有非常高的讀寫速度,所以在寄存器之間的數據傳送非常快。采用寄存器,可以減少 CPU 訪問內存的次數,從而提高了 CPU 的工作速度。寄存器組可分為專用寄存器和通用寄存器。專用寄存器的作用是固定的,分別寄存相應的數據;而通用寄存器用途廣泛并可由程序員規定其用途。
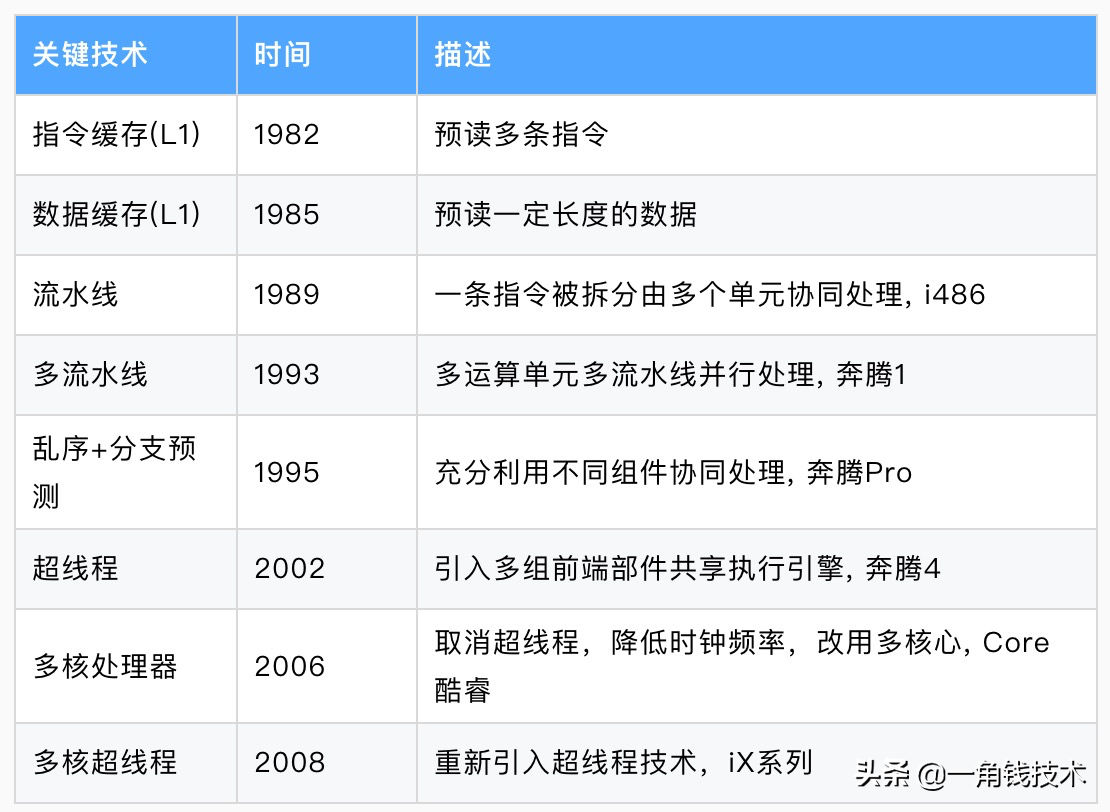
下表列出了CPU關鍵技術的發展歷程以及代表系列,每一個關鍵技術的誕生都是環環相扣的,處理器這些技術發展歷程都圍繞著如何不讓“CPU閑下來”這一個核心目標展開。
CPU緩存結構
現代CPU為了提升執行效率,減少CPU與內存的交互(交互影響CPU效率),一般在CPU上集成了多級緩存架構,常見的為三級緩存結構
- L1 Cache,分為數據緩存和指令緩存,邏輯核獨占
- L2 Cache,物理核獨占,邏輯核共享
- L3 Cache,所有物理核共享
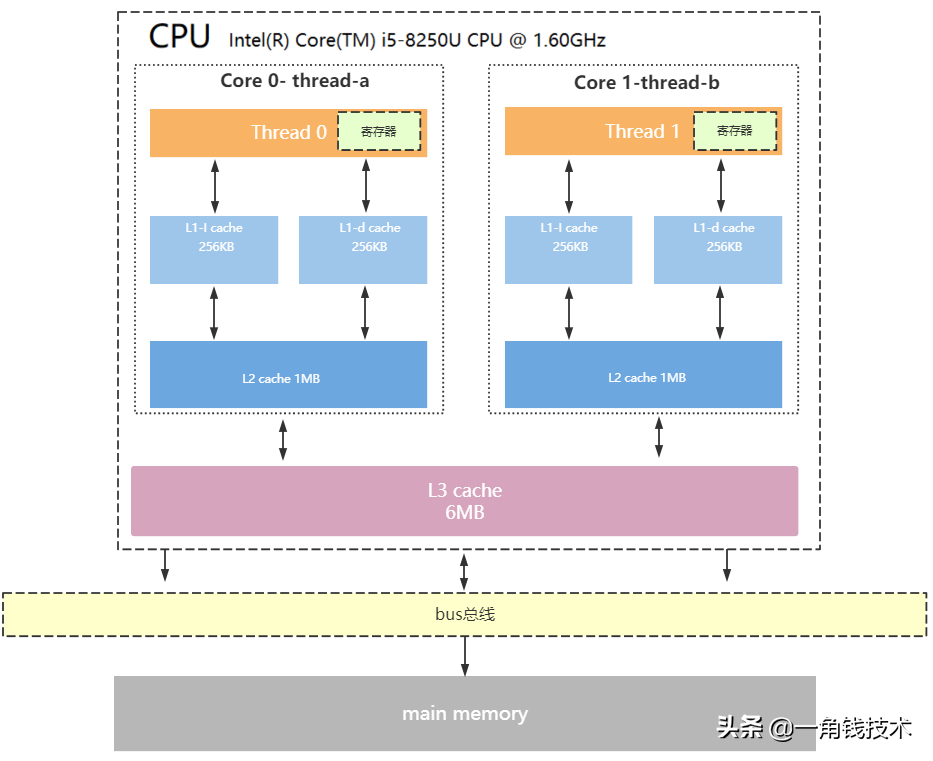
- 存儲器存儲空間大小:內存>L3>L2>L1>寄存器;
- 存儲器速度快慢排序:寄存器>L1>L2>L3>內存;
注意:緩存是由最小的存儲區塊-緩存行(cacheline)組成,緩存行大小通常為64byte。
緩存行是什么意思呢? 比如你的L1緩存大小是512kb,而cacheline = 64byte,那么就是L1里有512 * 1024/64個cacheline
CPU讀取存儲器數據過程
- CPU要取寄存器X的值,只需要一步:直接讀取。
- CPU要取L1 cache的某個值,需要1-3步(或者更多):把cache行鎖住,把某個數據拿來,解鎖,如果沒鎖住就慢了。
- CPU要取L2 cache的某個值,先要到L1 cache里取,L1當中不存在,在L2里,L2開始加鎖,加鎖以后,把L2里的數據復制到L1,再執行讀L1的過程,上面的3步,再解鎖。
- CPU取L3 cache的也是一樣,只不過先由L3復制到L2,從L2復制到L1,從L1到CPU。
- CPU取內存則最復雜:通知內存控制器占用總線帶寬,通知內存加鎖,發起內存讀請求,等待回應,回應數據保存到L3(如果沒有就到L2),再從L3/2到L1,再從L1到CPU,之后解除總線鎖定。
CPU為何要有高速緩存
CPU在摩爾定律的指導下以每18個月翻一番的速度在發展,然而內存和硬盤的發展速度遠遠不及CPU。這就造成了高性能能的內存和硬盤價格及其昂貴。然而CPU的高度運算需要高速的數據。為了解決這個問題,CPU廠商在CPU中內置了少量的高速緩存以解決I\O速度和CPU運算速度之間的不匹配問題。
在CPU訪問存儲設備時,無論是存取數據抑或存取指令,都趨于聚集在一片連續的區域中,這就被稱為局部性原理。
- 時間局部性(Temporal Locality):如果一個信息項正在被訪問,那么在近期它很可能還會被再次訪問。
比如循環、遞歸、方法的反復調用等。
- 空間局部性(Spatial Locality):如果一個存儲器的位置被引用,那么將來他附近的位置也會被引用。
比如順序執行的代碼、連續創建的兩個對象、數組等。
空間局部性案例:
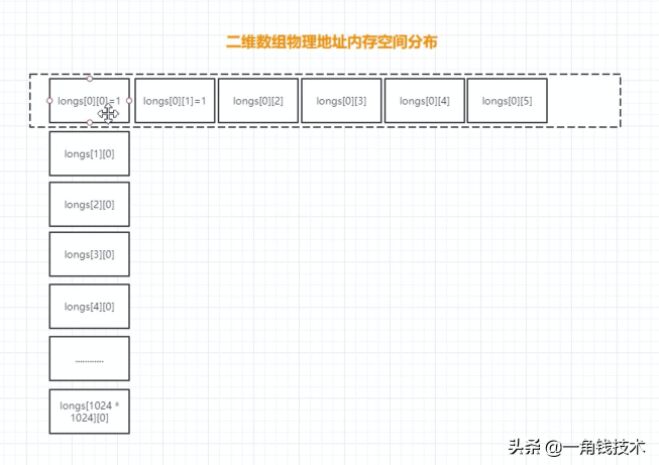
- public class TwoDimensionalArraySum {
- private static final int RUNS = 100;
- private static final int DIMENSION_1 = 1024 * 1024;
- private static final int DIMENSION_2 = 6;
- private static long[][] longs;
- public static void main(String[] args) throws Exception {
- /*
- * 初始化數組
- */
- longs = new long[DIMENSION_1][];
- for (int i = 0; i < DIMENSION_1; i++) {
- longs[i] = new long[DIMENSION_2];
- for (int j = 0; j < DIMENSION_2; j++) {
- longs[i][j] = 1L;
- }
- }
- System.out.println("Array初始化完畢....");
- long sum = 0L;
- long start = System.currentTimeMillis();
- for (int r = 0; r < RUNS; r++) {
- for (int i = 0; i < DIMENSION_1; i++) {//DIMENSION_1=1024*1024
- for (int j=0;j<DIMENSION_2;j++){//6
- sum+=longs[i][j];
- }
- }
- }
- System.out.println("spend time1:"+(System.currentTimeMillis()-start));
- System.out.println("sum1:"+sum);
- sum = 0L;
- start = System.currentTimeMillis();
- for (int r = 0; r < RUNS; r++) {
- for (int j=0;j<DIMENSION_2;j++) {//6
- for (int i = 0; i < DIMENSION_1; i++){//1024*1024
- sum+=longs[i][j];
- }
- }
- }
- System.out.println("spend time2:"+(System.currentTimeMillis()-start));
- System.out.println("sum2:"+sum);
- }
- }
帶有高速緩存的CPU執行計算的流程
- 程序以及數據被加載到主內存
- 指令和數據被加載到CPU的高速緩存
- CPU執行指令,把結果寫到高速緩存
- 高速緩存中的數據寫回主內存
CPU運行安全等級
CPU有4個運行級別,分別為:
- ring0
- ring1
- ring2
- ring3
Linux與Windows只用到了2個級別:ring0、ring3,操作系統內部內部程序指令通常運行在ring0級別,操作系統以外的第三方程序運行在ring3級別,第三方程序如果要調用操作系統內部函數功能,由于運行安全級別不夠,必須切換CPU運行狀態,從ring3切換到ring0,然后執行系統函數,說到這里相信大家明白為什么JVM創建線程,線程阻塞喚醒是重型操作了,因為CPU要切換運行狀態。 下面我大概梳理一下JVM創建線程CPU的工作過程
- step1:CPU從ring3切換ring0創建線程
- step2:創建完畢,CPU從ring0切換回ring3
- step3:線程執行JVM程序
- step4:線程執行完畢,銷毀還得切會ring0
操作系統內存管理
執行空間保護
操作系統有用戶空間與內核空間兩個概念,目的也是為了做到程序運行安全隔離與穩定,以32位操作系統4G大小的內存空間為例
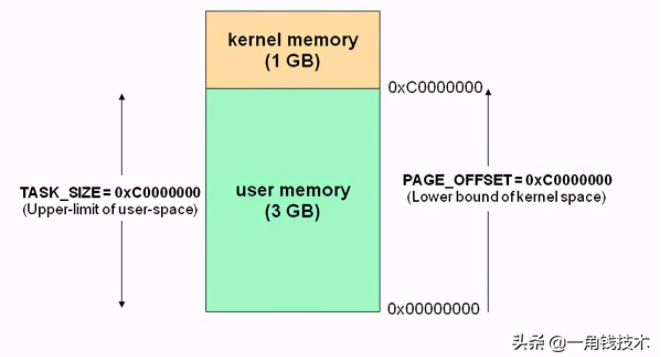
Linux為內核代碼和數據結構預留了幾個頁框,這些頁永遠不會被轉出到磁盤上。從 0x00000000 到 0xC0000000(PAGE_OFFSET) 的線性地址可由用戶代碼 和 內核代碼進行引用(即用戶空間)。從0xC0000000(PAGE_OFFSET)到 0xFFFFFFFFF的線性地址只能由內核代碼進行訪問(即內核空間)。內核代碼及其數據結構都必須位于這 1 GB的地址空間中,但是對于此地址空間而言,更大的消費者是物理地址的虛擬映射。
這意味著在 4 GB 的內存空間中,只有 3 GB 可以用于用戶應用程序。進程與線程只能運行在用戶方式(usermode)或內核方式(kernelmode)下。用戶程序運行在用戶方式下,而系統調用運行在內核方式下。在這兩種方式下所用的堆棧不一樣:用戶方式下用的是一般的堆棧(用戶空間的堆棧),而內核方式下用的是固定大小的堆棧(內核空間的對戰,一般為一個內存頁的大小),即每個進程與線程其實有兩個堆棧,分別運行與用戶態與內核態。
由空間劃分我們再引申一下,CPU調度的基本單位線程,也劃分為:
- 內核線程模型(KLT)
- 用戶線程模型(ULT)
內核線程模型
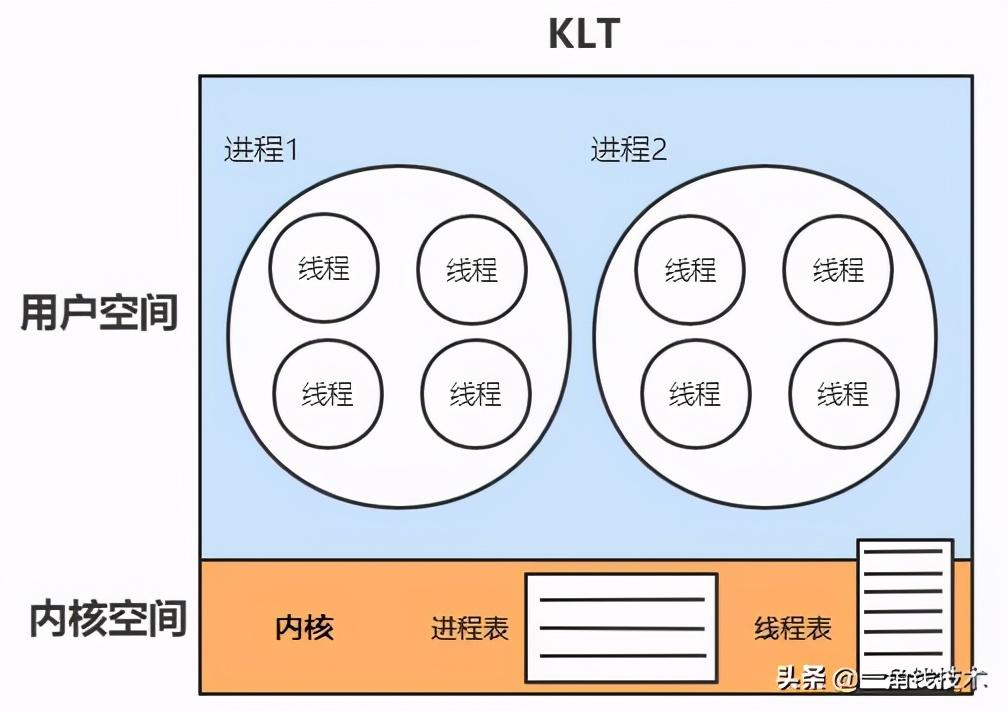
內核線程(KLT):系統內核管理線程(KLT),內核保存線程的狀態和上下文信息,線程阻塞不會引起進程阻塞。在多處理器系統上,多線程在多處理器上并行運行。線程的創建、調度和管理由內核完成,效率比ULT要慢,比進程操作快。
用戶線程模型
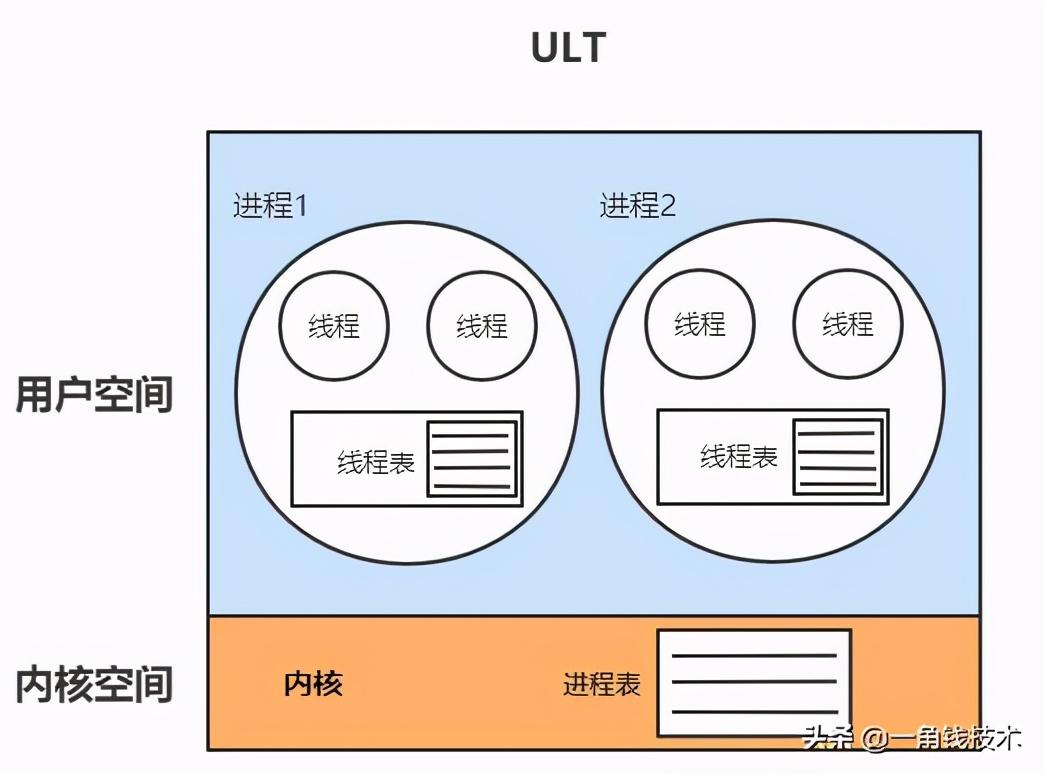
用戶線程(ULT):用戶程序實現,不依賴操作系統核心,應用提供創建、同步、調度和管理線程的函數來控制用戶線程。不需要用戶態/內核態切換,速度快。內核對ULT無感知,線程阻塞則進程(包括它的所有線程)阻塞。
到這里,大家不妨思考一下,jvm是采用的哪一種線程模型?
進程與線程
什么是進程?
現代操作系統在運行一個程序時,會為其創建一個進程;例如,啟動一個Java程序,操作系統就會創建一個Java進程。進程是OS(操作系統)資源分配的最小單位。
什么是線程?
線程是OS(操作系統)調度CPU的最小單元,也叫輕量級進程(Light Weight Process),在一個進程里可以創建多個線程,這些線程都擁有各自的計數器、堆棧和局部變量等屬性,并且能夠訪問共享的內存變量。CPU在這些線程上高速切換,讓使用者感覺到這些線程在同時執行,即并發的概念,相似的概念還有并行!
線程上下文切換過程:

虛擬機指令集架構
虛擬機指令集架構主要分兩種:
- 棧指令集架構
- 寄存器指令集架構
關于指令集架構的wiki詳細說明:http://zh.wikipedia.org/wiki/指令集架構
棧指令集架構
- 設計和實現更簡單,適用于資源受限的系統;
- 避開了寄存器的分配難題:使用零地址指令方式分配;
- 指令流中的指令大部分是零地址指令,其執行過程依賴于操作棧,指令集更小,編譯器容易實現;
- 不需要硬件支持,可移植性更好,更好實現跨平臺。
寄存器指令集架構
典型的應用是x86的二進制指令集:比如傳統的PC以及Android的Davlik虛擬機。
指令集架構則完全依賴硬件,可移植性差。
性能優秀和執行更高效。
花費更少的指令去完成一項操作。
在大部分情況下,基于寄存器架構的指令集往往都以一地址指令、二地址指令和三地址指令為主,而基于棧式架構的指令集卻是以零地址指令為主。
- Java符合典型的棧指令集架構特征,像Python、Go都屬于這種架構。















