













機器學習論文復現(xiàn),這五大問題你需要注意
我最初接觸機器學習時,花費了大量時間來閱讀論文,并嘗試實現(xiàn)。當然,我不是天才。實現(xiàn)它意味著要執(zhí)行 git clone 并嘗試運行論文作者的代碼。對于我感興趣的概念,我可能還手動輸入一些代碼并進行注釋,以便更好地理解論文和項目。
這樣的學習方法令人沮喪。嘗試復現(xiàn)論文的流程大致如下:
- 一些達到新 SOTA 的論文在新聞媒體中引起關(guān)注;
- 讀者深入研究或快速瀏覽論文內(nèi)容;
- 讀者對論文中的實驗結(jié)果印象深刻,并產(chǎn)生復現(xiàn)的興趣。
接下來就是瘋狂搜索項目代碼,并嘗試在作者所用的數(shù)據(jù)集上運行代碼。這時,你需要祈禱該項目具備以下要素:運行說明(README.md)、代碼、參數(shù)、數(shù)據(jù)集、數(shù)據(jù)集路徑、軟件環(huán)境、所需依賴項以及硬件條件。了解這些,才能順利復現(xiàn)論文中的 SOTA 結(jié)果。
而在這個過程中,你可能會遇到很多常見問題(參見下文)。遇到問題之前先了解它們是很有幫助的,畢竟,沒人喜歡空手而歸。
復現(xiàn)機器學習論文時的常見問題
復現(xiàn)過程中的常見問題如下所示:
- README 文件不完整或缺失;
- 未定義依賴項、代碼存在 bug、缺少預訓練模型;
- 未公開參數(shù);
- 私有數(shù)據(jù)集或缺少預處理步驟;
- 對 GPU 資源的需求不切實際。
1. README 文件不完整或缺失
如果一篇論文在發(fā)表時開源了代碼,那么 README 就是你著手開始復現(xiàn)項目的文檔之一。好的 README 文件通常具備以下幾個組成部分:依賴項列表、訓練腳本、評估腳本、預訓練模型以及運行腳本得到的結(jié)果。
實際上,這些內(nèi)容已經(jīng)在 Papers with Code 發(fā)布的《機器學習代碼完整性自查清單》中列出(該清單已成為 NeurIPS 2020 代碼提交流程的一部分)。該清單受到麥吉爾大學副教授、Facebook 蒙特利爾 FAIR 實驗室負責人 Joelle Pineau 的啟發(fā)。
Papers with Code 提供的 README 樣例參見:
https://github.com/paperswithcode/releasing-research-code
不完整的 README 文件對運行代碼而言是一個壞的開端。
一個需要注意的信號是示例 notebook 或示例代碼。notebook 的用途是演示代碼的使用。理想情況下,除了點擊「Run all」以外,不需要任何其他調(diào)整就能夠運行 notebook。預填充參數(shù)和數(shù)據(jù)路徑的命令行也能夠?qū)崿F(xiàn)同樣的效果。
還有一些次要但有用的信息,比如作者的聯(lián)系方式或展示模型架構(gòu)或數(shù)據(jù)轉(zhuǎn)換流程的 gif 圖片等,這些都是完備的 README 文件應該包含的。如果代碼庫托管在 GitHub 上,請檢查 Issue 區(qū)域的問題是否得到了積極回復,以及 pull request 是否定期被查看。這些事項均能證明庫得到精心維護,確保后續(xù)復現(xiàn)工作得到有效支持。當然會有例外,但請慎重考慮以上各項出現(xiàn)缺失的情況。

Joelle Pineau 發(fā)布的機器學習可復現(xiàn)性檢查清單
(圖源:https://www.cs.mcgill.ca/~jpineau/ReproducibilityChecklist.pdf)
2. 未定義依賴項、代碼存在 bug、缺少預訓練模型
當你對示例 notebook 覺得滿意后,你或許想嘗試用不同的參數(shù)在自己的數(shù)據(jù)集上試用模型。在這一階段,你或許會調(diào)用示例 notebook 中未用到的函數(shù),或者在自己的數(shù)據(jù)集上嘗試預訓練模型,這時可能會遇到問題。
例如,你可能注意到 requirements.txt 缺失,或者軟件包版本未固定(如 tensorflow==2.2)想象一下當你發(fā)現(xiàn) TensorFlow 版本是 1.15 而不是 2.2,原因只是作者沒有指定版本時的爆炸心態(tài)吧。
假設你檢查過了依賴項,然而現(xiàn)在卻發(fā)現(xiàn)預訓練模型失蹤了!這種情況下,你要么 debug 代碼,要么提交 bug 報告,要么忽略代碼。請謹慎選擇第一個選項,因為你可能會在這上面花費好幾個小時。當然有的 bug 很容易解決,如果我能修復的話,我會提交 pull request。但并不是每次都那么好運,這些隨手可及的果子有時候很難摘。
預訓練模型缺失是一個危險信號,但這其實并不罕見。畢竟,論文作者沒有義務發(fā)布模型。那么,另一個替代方法是使用公開的參數(shù)訓練模型進行復現(xiàn)。不過參數(shù)也不總是公開……
3. 未公開參數(shù)
根據(jù)模型情況來看,超參數(shù)對于實現(xiàn) SOTA 結(jié)果是非常重要的。下圖展示了不同參數(shù)產(chǎn)生不同的 f1 分數(shù)(范圍從 0.5 到 1.0)。模型中的參數(shù)通常是學習率(learning rate)、嵌入尺寸(embedding size)、層數(shù)、dropout 量、批處理大小、訓練 epoch 數(shù)量等。
因此,如果作者沒有提供他們使用的確切參數(shù),你可能必須自己進行所有實驗才能復現(xiàn) SOTA 結(jié)果。
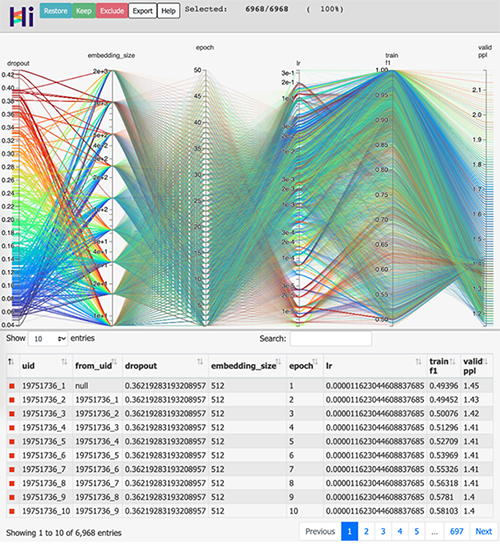
順便說一句,F(xiàn)acebook 的 HiPlot 是一個很好的工具,幫助你在使用不同參數(shù)組合時將模型結(jié)果可視化。
HiPlot 地址:https://github.com/facebookresearch/hiplot
4. 私有數(shù)據(jù)集或缺少預處理步驟
從很多方面來說,我們很幸運地擁有世界各地研究者提供的開源數(shù)據(jù)集。事實就是如此,數(shù)據(jù)的收集絕非易事,而清理這些數(shù)據(jù)并將其格式化以供研究使用,就更加麻煩一些。在此需感謝學術(shù)機構(gòu)和 Kaggle 免費托管這些開源數(shù)據(jù)集,因為帶寬和存儲成本是很高的。
然而想使用私有數(shù)據(jù)集,并非易事。數(shù)據(jù)集可能包含受版權(quán)保護的信息,比如 ImageNet。通常你需要填寫一份申請表,版權(quán)所有者將自行決定是否批準。
某些時候這個過程會很麻煩,如果你所需的數(shù)據(jù)集不可用,在申請行動之前要先認真考慮一下。或者你可以從其他渠道搜索或者下載數(shù)據(jù),比如 Academic Torrents:
https://academictorrents.com/。
5. 對 GPU 資源的需求不切實際
近期出現(xiàn)了一股趨勢:模型越大性能越好。一些論文使用了整個數(shù)據(jù)中心的算力才達到 SOTA 結(jié)果,這些論文復現(xiàn)起來當然很難。例如,2019 年 10 月谷歌發(fā)表論文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,嘗試通過將參數(shù)擴展到 110 億來探索 Transformer 模型架構(gòu)的局限性。然而幾個月后微軟用 170 億參數(shù)創(chuàng)建了 Turning-NLG,不久 OpenAI 放出 1750 億參數(shù)的預訓練語言模型 GPT-3……
要想訓練數(shù)十億參數(shù)的模型,你需要使用分布式訓練方法以及某種形式的高性能計算(HPC)或 GPU 集群。具備 110 億和 170 億參數(shù)的模型分別需要約 44GB 和 68GB 的內(nèi)存,因此這些模型無法僅使用一塊 GPU 完成訓練。
簡而言之,盡早發(fā)現(xiàn)論文所用大模型是否超出你的個人能力。
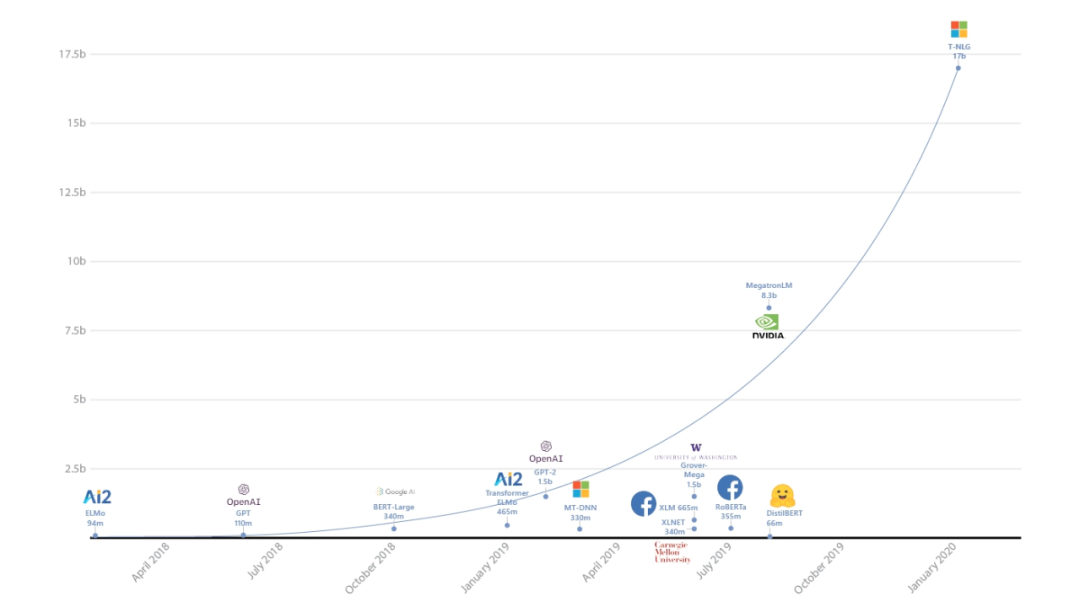
微軟訓練 Turning-NLG。
總結(jié)
復現(xiàn)論文代碼并非易事,不過越來越多的項目嘗試標準化 SOTA 模型。我個人最喜歡的是 HuggingFace 的 Transformers,它為研究者和開發(fā)者提供了足夠低的進入門檻。另外,TensorFlow 的 Model Garden 和 PyTorch 的 Model Zoo 也發(fā)展迅速(其中分別是 TensorFlow 和 PyTorch 團隊構(gòu)建的預訓練模型)。
這些庫旨在標準化預訓練模型的使用,并為模型貢獻和分發(fā)提供合適的條件。它們對代碼質(zhì)量提供了保障,并且具備不錯的文檔。我希望社區(qū)能從這些庫中獲益,并幫助復現(xiàn) SOTA 結(jié)果,輕松地使用 SOTA 模型。
【本文是51CTO專欄機構(gòu)“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】













