輸密碼時一定要靜音!Github上有黑客通過麥克風盜取密碼
Github 搜: "ggerganov/kbd-audio"
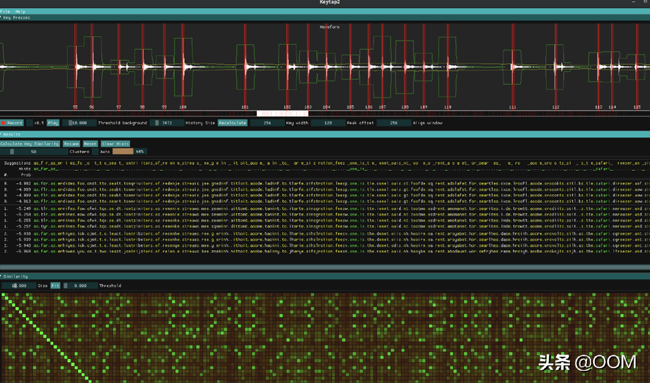
該項目的原理
主要目標是利用按鍵盤按鍵作為副聲道產生的聲音,以便猜測所鍵入文本的內容。為此,該算法將包含音頻記錄的訓練集以及在該記錄期間鍵入的相應鍵作為輸入。使用此數據,算法可 了解不同按鍵的聲音是什么,然后嘗試僅使用捕獲的音頻來識別聲音。從某種意義上講,該訓練集是針對特定的設置的-鍵盤,麥克風和二者之間的相對位置。更改這些因素中的任何一個都會使該方法無效。另外,當前的實現可以實時進行預測。
實施中涉及的主要步驟如下:
- 收集培訓數據
- 創建預測模型(學習步驟)
- 按鍵檢測
- 預測檢測到的按鍵的按鍵
收集培訓數據
在當前的實現中,擊鍵之間的聲音被簡單地丟棄。在實際按下之前和之后,我們僅將音頻保持在75-100毫秒之內。這有點棘手,因為按鍵和程序捕獲的事件之間似乎存在隨機延遲-最有可能涉及硬件和軟件因素。
例如,這是在鍵盤上按字母“ g”的完整音頻波形如下所示:
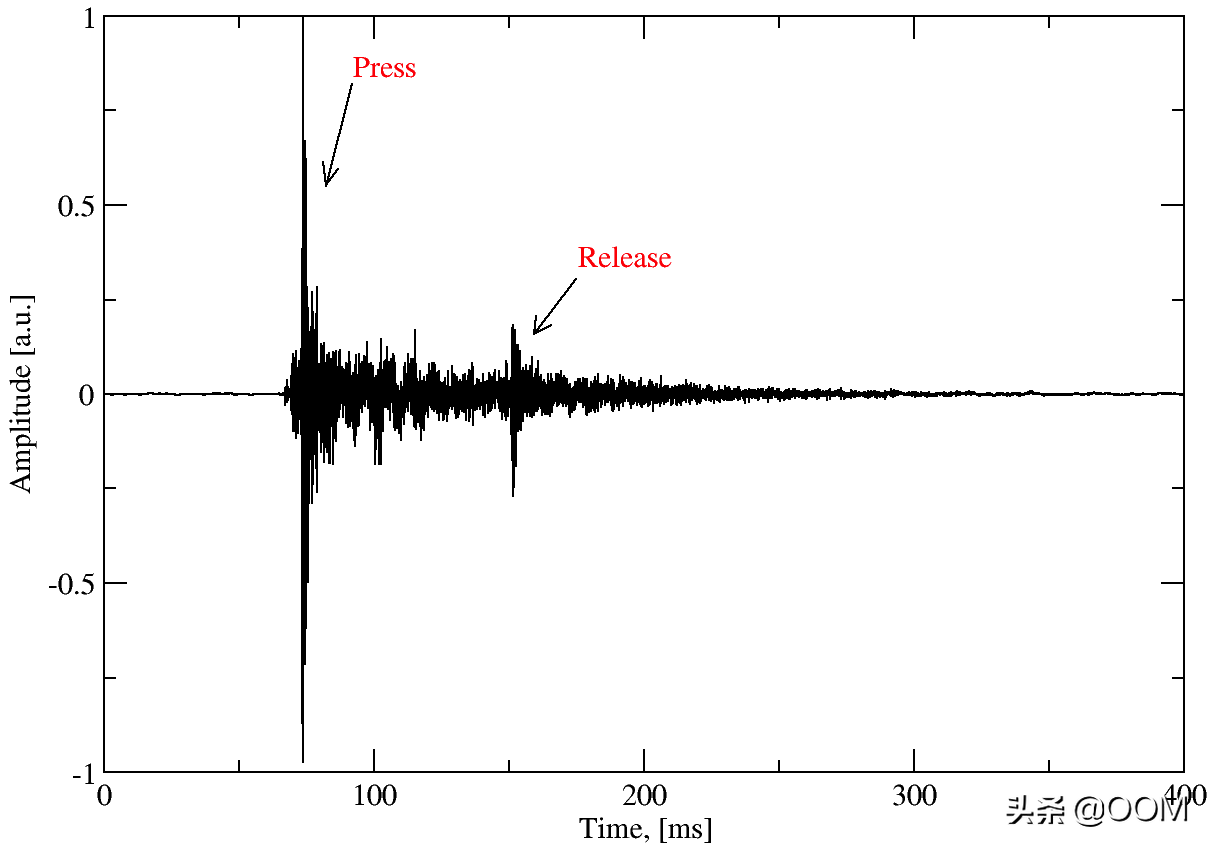
從圖中可以看出,在壓力峰值之后不久還有一個附加的釋放峰值。Keytap只是忽略發布峰值。這里可能有可能提取其他信息,但是為了簡單起見,數據被丟棄。最后,此鍵的訓練數據如下所示:
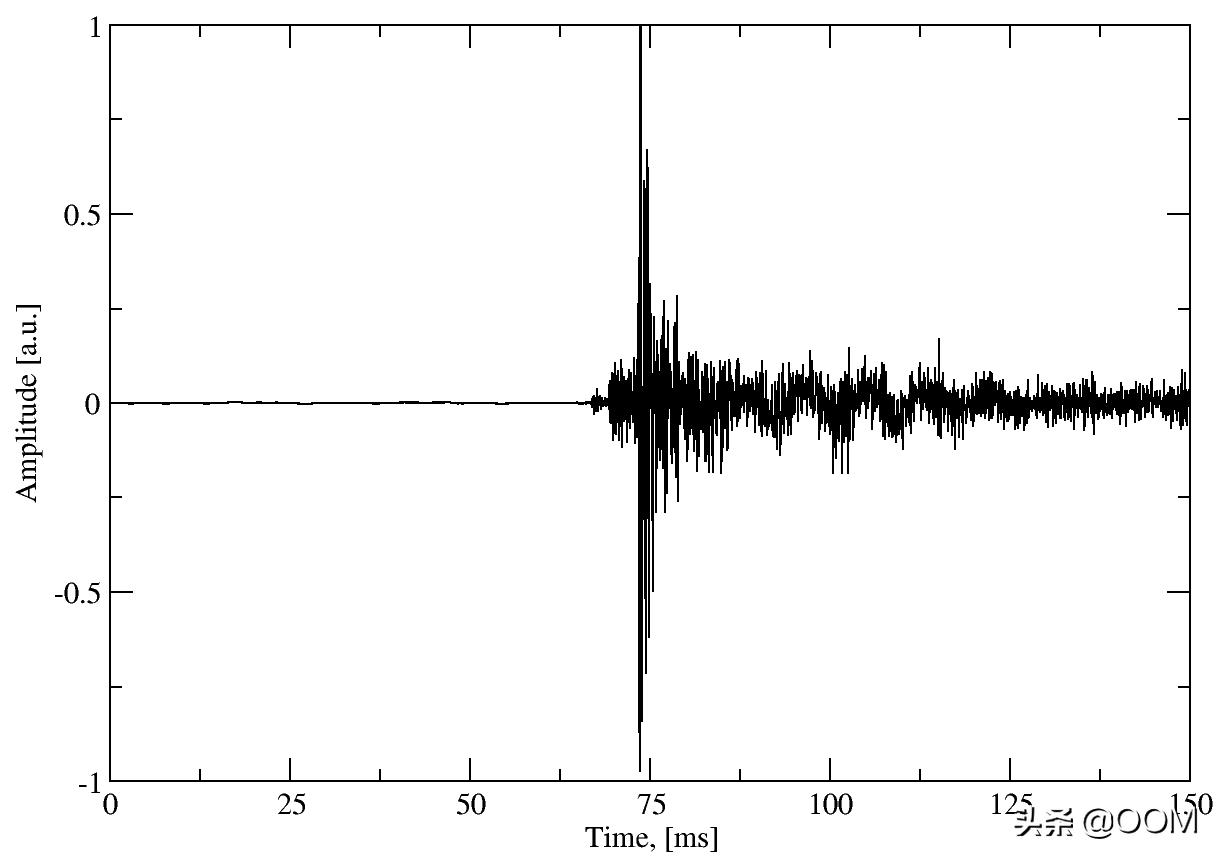
顯然,75 ms的窗口對鍵入速度施加了一定的限制-如果在此時間段內擊鍵重疊,則會混入不同鍵的訓練數據。
另一個觀察結果是,某個鍵的可用訓練波形越多-越好。組合多個波形有助于減輕環境噪聲。此外,根據用戶按下按鍵的方式,各個按鍵的聽起來可能略有不同,因此可能會捕獲各種按鍵可能發出的聲音。
創建預測模型
人們可以在這里獲得很大的創造力-機器學習,人工智能,神經網絡等。Keytap 使用非常簡單的方法。對于每個培訓密鑰,我們執行3個步驟:
- 對齊收集的波形的峰值。這有助于避免在檢測到按鍵事件之前進行隨機的時間延遲(前面已說明)。
- 基于相似性度量的波形更精細的對齊。有時,峰值并不是最好的指標,因此我們使用更精確的方法。
- 對齊波形的簡單加權平均。權重由相似性度量標準定義。
我們不希望直接應用步驟2,因為相似度指標的計算可能會占用大量CPU資源。因此,步驟1有效地縮小了對齊窗口的范圍并減少了計算量。
在第3步之后,我們為每個鍵最終得到一個平均波形。稍后將其與實時捕獲的數據進行比較,并用于預測最可能的密鑰。
按鍵過程中使用的相似性指標是互相關(CC):
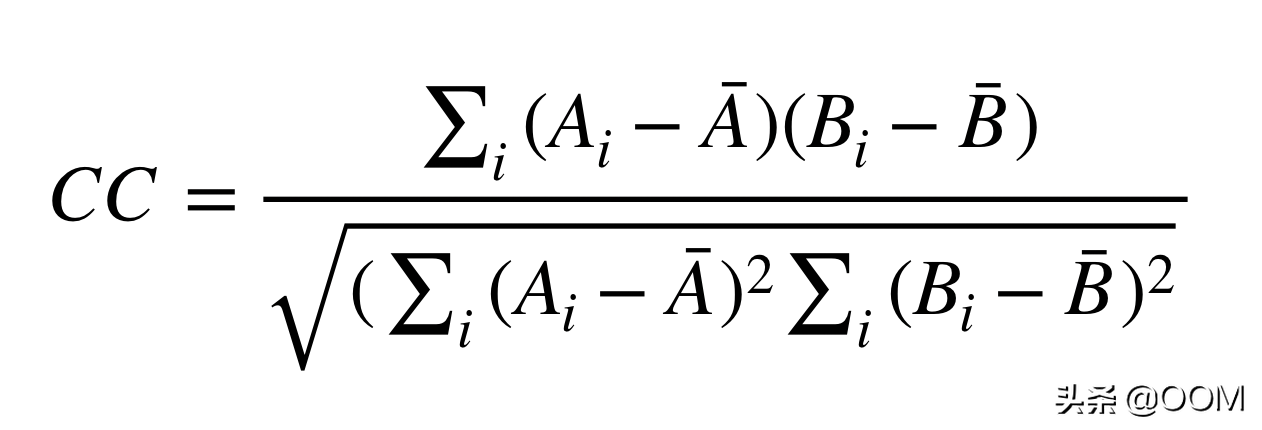
在此,Ai和Bi是被比較的兩個波形的波形樣本。較高的CC值對應于多個相似的波形。也可以使用其他相似性度量。
按鍵之間間隔的時間信息可能會集成到預測模型中。到目前為止,我已經避免了這樣的方法,因為它們很難實施。
按鍵檢測
Keytap使用相對簡單的閾值技術來檢測原始音頻中的按鍵事件。顯然,我們希望用戶按下按鍵時會出現一個巨大的峰值,所以這就是我們想要的。該閾值是自適應的-它相對于過去幾百毫秒的平均樣本強度而言。
這種方法絕對不是完美的,我希望我知道如何做出更可靠的方法來檢測新聞事件。我也不喜歡與當前閾值處理技術相關聯的free參數。
預測檢測到的按鍵的按鍵
一旦識別出潛在的按鍵事件,我們就可以確定波形中峰值的位置,并計算該部分波形與訓練數據中所有平均波形的相似性度量。我們允許在峰周圍有一個小的對齊窗口(如前所述)。我們期望最高相似性度量將對應于所鍵入的密鑰。
一些觀察
我注意到,當算法無法檢測到正確的密鑰時,它仍會預測附近的密鑰。鄰近,因為它位于真鑰匙旁邊。為此,我可以想到2種解釋:
- 鍵盤上的附近按鍵會發出類似的聲音
- 在這種方法中,按鍵相對于麥克風的位置對于預測非常重要
我認為選項1不太可能。
另一個觀察結果是,與非機械鍵盤相比,機械鍵盤更容易受到此類攻擊。
按鍵2
我很確定可以實現一種根本不需要收集訓練數據的預測方法。假設用戶以某種已知語言(例如英語)鍵入文本,則與該語言的N-gram有關的統計信息與檢測到的按鍵的相似性度量結合起來足以檢測出正在鍵入的文本。實際上,它歸結為打破替代密碼。
Keytap2是嘗試演示這種攻擊的一種嘗試。我仍在努力-我停留在根據其CC對按鍵進行聚類的部分。但是我認為至少我已經準備好了替代密碼破解部分。在實際工作時會嘗試提供更多詳細信息。