MySQL邏輯數據恢復體系的設計
對于數據恢復來說,現在其實缺少一些有效的使用場景來更好的體現業務價值,于是我們就重新考慮了下現有的備份支持能力。
備份體系的支持能力
|
粒度 |
備份類型 |
備份模式 |
|
實例 |
全量備份 |
物理備份 |
|
實例 |
增量備份 |
物理備份 |
|
實例 |
日志備份 |
獨立服務 |
|
數據庫 |
對象備份 |
物理備份 |
其實對象層面的數據恢復能力是很重要的,而且對于業務側有很多種使用方式。整體的數據恢復流程如下:
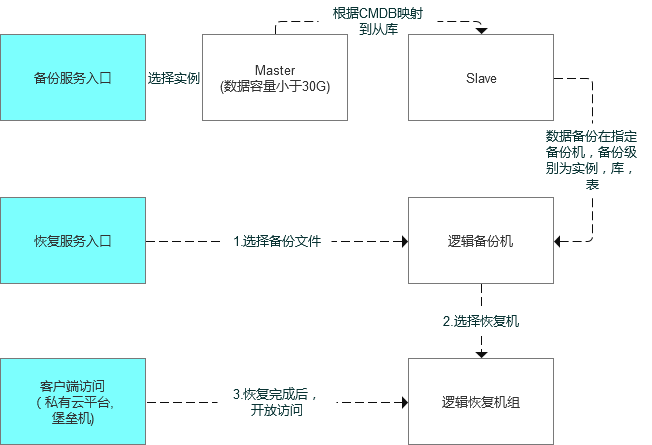
如何規劃和設計邏輯備份恢復體系,經過部分討論,我做了如下的初版設計。
1.數據備份
其中邏輯備份恢復主要面向兩個維度:
實例級別:實現表結構,表結構+數據 備份
庫/表級別:實現表結構,表結構+數據 備份
目前的邏輯備份恢復的支持范圍:
1)數據庫主從拓撲關系的實例,邏輯備份操作根據拓撲關系需要在相應的從庫端執行
2)單實例節點,邏輯備份操作在單實例節點執行,需要評估備份容量和負載等信息
目前不支持基于中間件MyCAT的節點
對于輸入為域名或者Master IP的信息,需要通過拓撲關系轉化為相應的從庫或者單實例的IP信息
對于庫表文件的備份,可以設定如下的規則:
1)單表數據量小于5000萬或者表容量在10G以內的表,可以支持邏輯備份,此外需要相應的提示,盡可能避免此類操作
2)選擇備份的數據庫容量在30G以內,此外需要相應的提示避免此類操作
需要后端提供相應的庫,表 存儲容量/數據量相關的元數據信息(估算容量即可,不需要精確值),目前可以通過生命周期管理中的數據庫基線和數據表基線元數據支持
對于備份時長的評估,目前可以提供如下的遞增區間:
1)備份容量在500M以內,顯示預計完成時間在5分鐘以內
2)備份容量在2G以內,顯示完成時間在10分鐘以內
3)備份容量在10G以內,顯示完成時間在20分鐘以內
4)備份容量在30G以內,顯示完成時間在30分鐘以內
在備份完成后,可以提供相應的即時通訊提示告知業務側備份操作已完成
備份生成的文件需要在指定的備份機存儲,按照如下的目錄規則進行存放
備份機BASE目錄:/data/logical_backup/
備份機中實例的備份目錄:
- [Slave_IP]_[port]/[YYYYmmdd]/
相應的備份文件命名規則:
- [Slave_IP]_[port]_[db_name]_[YYYYmmdd]_[hhmiss]_[username].sql
數據備份后需要生成相應的配置文件,數據格式為JSON,在數據恢復時可以進行相應數據格式的解析和顯示。
備份文件的保留周期目前暫定為7天,需要在備份時有相應的提示。
2.數據恢復
數據恢復是業務自助發起,而且相關的數據恢復資源具有使用時限,目前暫定為2天,2天后相應的數據和權限會進行相應的回收,會有相應的資源回收提示,同時需要在使用中進行相關提示。
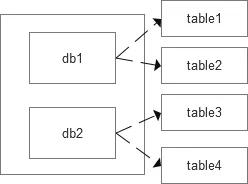
數據恢復粒度基于備份數據文件中指定的對象(數據庫,表)粒度,如業務同學A備份了表db1.table1,db1.table2,則不能僅恢復db1.table1,恢復工作會直接恢復db1.table1,db1.table2
數據恢復文件的選擇需要考慮相關的權限,如業務同學A備份了表db1.table1,db1.table2,業務同學B備份了表db2.table3,db2.table4,則在選擇備份文件中,應該彼此不可見。
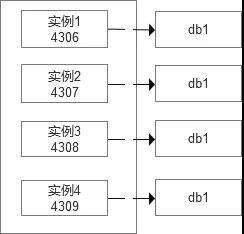
如果對于同一個數據庫需要進行多次數據恢復,則可以根據服務器的資源配比進行動態的調配,比如一個數據恢復服務器中有4個實例,端口分別是4306-4309,業務同學在使用中可以相應的恢復4次,在實際使用中需要根據使用的頻率和情況進行資源的擴展,后續應該為一個數據恢復服務器組
在數據恢復中,需要恢復到哪一個實例,由后端提供相應的調度邏輯進分配
對于數據恢復后的使用,可以提供一體化服務,由業務側使用客戶端工具如workbench進行連接和使用,權限開通的部分,需要根據用戶的域名信息得到辦公機的IP地址,進行相關數據庫權限的開通,開通后有對應的即時通訊提示。
數據庫層的權限開通,如果數據庫用戶已經存在,則進行相應的權限補充,如果數據庫用戶不存在,則需要在指定的實例中創建用戶,并分配相應的權限
整個備份數據的使用,需要考慮到便利性和安全性,可以和安全部進行對接,進行部分工作的評估和考量。
備份和恢復的相關操作和歷史記錄,需要統一存儲和管理
對于數據恢復的相關日志,為了便于后續管理和跟蹤,需要在恢復記錄中記錄備份文件的路徑
本文轉載自微信公眾號「楊建榮的學習筆記」,可以通過以下二維碼關注。轉載本文請聯系楊建榮的學習筆記公眾號。