Broker的實(shí)現(xiàn)邏輯-kafka知識(shí)體系(三)
上篇文章分享了kafka 生產(chǎn)端的邏輯,以及消息發(fā)送到緩存后由sender線程發(fā)送到Broker,那么Broker 是怎么進(jìn)行數(shù)據(jù)接收和持久化的呢?下面我們從Broker 的網(wǎng)絡(luò)設(shè)計(jì)聊起。
Broker 網(wǎng)絡(luò)設(shè)計(jì)
kafka的網(wǎng)絡(luò)設(shè)計(jì)和Kafka的調(diào)優(yōu)有關(guān),這也是為什么它能支持高并發(fā)的原因。
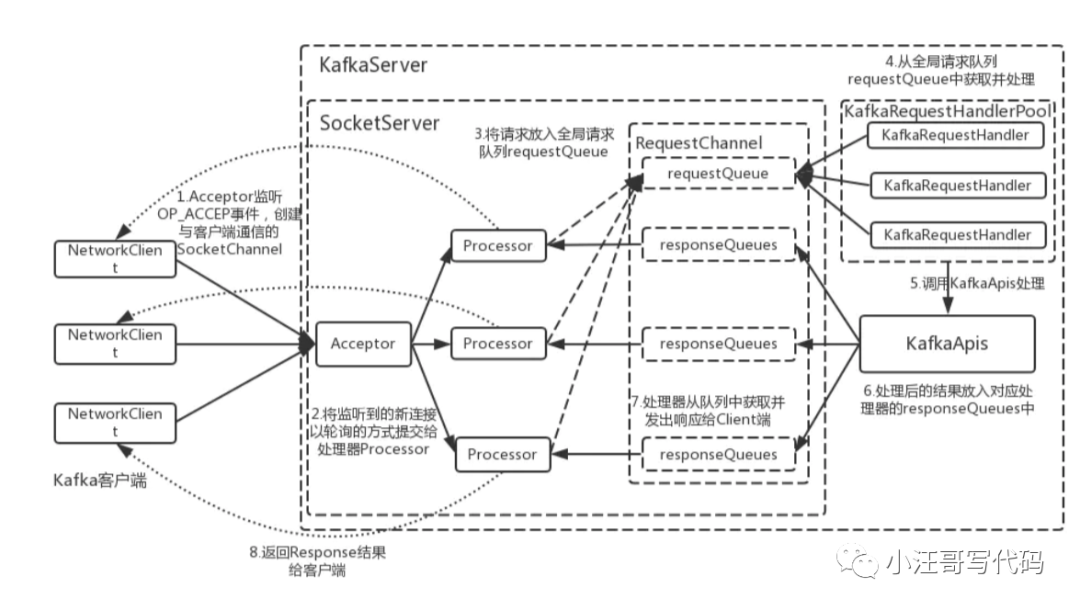
Kafka的網(wǎng)絡(luò)三層架構(gòu)
首先客戶端發(fā)送請(qǐng)求全部會(huì)先發(fā)送給一個(gè)Acceptor,broker里面會(huì)存在3個(gè)線程(默認(rèn)是3個(gè)),這3個(gè)線程都是叫做processor,
Acceptor不會(huì)對(duì)客戶端的請(qǐng)求做任何的處理,直接封裝成一個(gè)個(gè)socketChannel發(fā)送給這些processor形成一個(gè)隊(duì)列,發(fā)送的方式是輪詢,就是先給第一個(gè)processor發(fā)送,然后再給第二個(gè),第三個(gè),然后又回到第一個(gè)。
消費(fèi)者線程去消費(fèi)這些socketChannel時(shí),會(huì)獲取一個(gè)個(gè)request請(qǐng)求,這些request請(qǐng)求中就會(huì)伴隨著數(shù)據(jù)。
線程池里面默認(rèn)有8個(gè)線程,這些線程是用來處理request的,解析請(qǐng)求,如果request是寫請(qǐng)求,就寫到磁盤里。讀的話返回結(jié)果。processor會(huì)從response中讀取響應(yīng)數(shù)據(jù),然后再返回給客戶端。這就是Kafka的網(wǎng)絡(luò)三層架構(gòu)。
調(diào)優(yōu)點(diǎn)1
所以如果我們需要對(duì)kafka進(jìn)行增強(qiáng)調(diào)優(yōu),增加processor并增加線程池里面的處理線程,就可以達(dá)到效果。request和response那一塊部分其實(shí)就是起到了一個(gè)緩存的效果,是考慮到processor們生成請(qǐng)求太快,線程數(shù)不夠不能及時(shí)處理的問題。所以這就是一個(gè)加強(qiáng)版的reactor網(wǎng)絡(luò)線程模型。
Broker數(shù)據(jù)存儲(chǔ)設(shè)計(jì)
【partition 的數(shù)據(jù)文件】
我們知道topic 是邏輯上的概念,partition是topic物理上的分組,一個(gè)topic可以分為多個(gè)partition,每個(gè)partition是一個(gè)有序的隊(duì)列。
例如創(chuàng)建2個(gè)topic名稱分別為report_push、launch_info, partitions數(shù)量都為partitions=4 存儲(chǔ)路徑和目錄規(guī)則為:xxx/message-folder
- |--report_push-0
- |--report_push-1
- |--report_push-2
- |--report_push-3
- |--launch_info-0
- |--launch_info-1
- |--launch_info-2
- |--launch_info-3
而partition物理上由多個(gè)segment組成。
【segment】log
每個(gè)segment 大小相等,順序讀寫.
每個(gè)segment數(shù)據(jù)文件以該段中最小的offset 命名,文件擴(kuò)展名為.log
日志回滾受log.segment.bytes控制,默認(rèn)1G;
這樣在查找指定offset 的Message 的時(shí)候,用二分查找(跳表)就可以定位到該Message 在哪個(gè)segment 數(shù)據(jù)文件中.
在磁盤上,一個(gè)partition就是一個(gè)目錄,然后每個(gè)segment由一個(gè)index文件和一個(gè)log文件組成。如下:
- $ tree kafka | head -n 6
- kafka
- ├── events-1
- │ ├── 00000000003064504069.index
- │ ├── 00000000003064504069.log
- │ ├── 00000000003065011416.index
- │ ├── 00000000003065011416.log
Segment下的log文件就是存儲(chǔ)消息的地方
每個(gè)消息都會(huì)包含消息體、offset、timestamp、key、size、壓縮編碼器、校驗(yàn)和、消息版本號(hào)等。
在磁盤上的數(shù)據(jù)格式和producer發(fā)送到broker的數(shù)據(jù)格式一模一樣,也和consumer收到的數(shù)據(jù)格式一模一樣。由于磁盤格式與consumer以及producer的數(shù)據(jù)格式一模一樣,這樣就使得Kafka可以通過零拷貝(zero-copy)技術(shù)來提高傳輸效率。
【segment】index
索引文件是內(nèi)存映射(memory mapped)的。
索引文件,一個(gè)稀疏格式的索引,受參數(shù)log.index.interval.bytes控制,默認(rèn)4KB。即不是每條數(shù)據(jù)都會(huì)寫索引,默認(rèn)每寫4KB數(shù)據(jù)才會(huì)寫一條索引。
Kafka 為每個(gè)分段后的數(shù)據(jù)文件建立了索引文件,文件名與數(shù)據(jù)文件的名字是一樣的,只是文件擴(kuò)展名為.index.
index 文件中并沒有為數(shù)據(jù)文件中的每條 Message 建立索引,而是采用了稀疏存儲(chǔ)的方式,每隔一定字節(jié)的數(shù)據(jù)建立一條索引.
這樣避免了索引文件占用過多的空間,從而可以將索引文件保留在內(nèi)存中。
有關(guān)內(nèi)存映射:
- 即便是順序?qū)懭胗脖P,硬盤的訪問速度還是不可能追上內(nèi)存。所以Kafka的數(shù)據(jù)并不是實(shí)時(shí)的寫入硬盤,它充分利用了現(xiàn)代操作系統(tǒng)分頁存儲(chǔ)來利用內(nèi)存提高I/O效率。Memory Mapped Files(后面簡稱mmap)也被翻譯成內(nèi)存映射文件,它的工作原理是直接利用操作系統(tǒng)的Page來實(shí)現(xiàn)文件到物理內(nèi)存的直接映射。完成映射之后你對(duì)物理內(nèi)存的操作會(huì)被同步到硬盤上(操作系統(tǒng)在適當(dāng)?shù)臅r(shí)候)。通過mmap,進(jìn)程像讀寫硬盤一樣讀寫內(nèi)存,也不必關(guān)心內(nèi)存的大小有虛擬內(nèi)存為我們兜底。mmap其實(shí)是Linux中的一個(gè)用來實(shí)現(xiàn)內(nèi)存映射的函數(shù),在Java NIO中可用MappedByteBuffer來實(shí)現(xiàn)內(nèi)存映射。
【Kafka中通過offset查詢消息內(nèi)容的整個(gè)流程】
Kafka 中存在一個(gè) ConcurrentSkipListMap 來保存在每個(gè)日志分段。
offset-->concurrentSkipListMap-->找到baseOffset對(duì)應(yīng)的日志分段-->讀取索引文件.index-->找打不大于offset-baseoffset的最大索引項(xiàng)-->讀取分段文件(.log)-->從日志分段文件(.log)中順序查找
當(dāng)前索引文件的文件名即為 baseOffset 的值。
【日志留存策略】
Kafka 會(huì)定期檢查是否要?jiǎng)h除舊消息,見參數(shù)
log.retention.check.interval.ms,默認(rèn)5分鐘。當(dāng)前有三種日志留存策略:
基于空間:log.retention.bytes,默認(rèn)未開啟;
基于時(shí)間:log.retention.hours(mintues/ms),默認(rèn)7天;
基于起始位移:Kafka 0.11.0.0版本引入,解決流處理場景中已處理的中間消息刪除問題。
目前基于時(shí)間的日志留存策略最常使用。
調(diào)優(yōu)點(diǎn)2
即盡力保持客戶端版本和 Broker 端版本一致
即盡力保持客戶端版本和 Broker 端版本一致。不要小看版本間的不一致問題,它會(huì)令 Kafka 喪失很多性能收益,比如 Zero Copy。
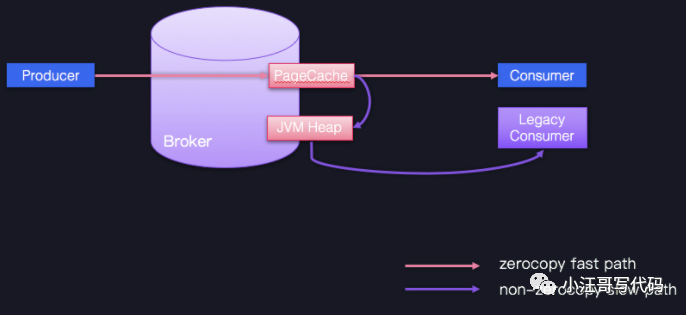
圖中藍(lán)色的 Producer、Consumer 和 Broker 的版本是相同的,它們之間的通信可以享受 Zero Copy 的快速通道;相反,一個(gè)低版本的 Consumer 程序想要與 Producer、Broker 交互的話,就只能依靠 JVM 堆中轉(zhuǎn)一下,丟掉了快捷通道,就只能走慢速通道了。因此,在優(yōu)化 Broker 這一層時(shí),你只要保持服務(wù)器端和客戶端版本的一致,就能獲得很多性能收益了。
Broker 副本機(jī)制
分區(qū)副本默認(rèn)1,見參數(shù)
default.replication.factor。
【副本作用(并不提供讀寫分離)】
1、實(shí)現(xiàn)冗余,提高消息可靠性
2、實(shí)現(xiàn)高可用,參與leader選舉,在leader不可用時(shí)提高可用性。
3、leader處理partition的所有讀寫請(qǐng)求;follower會(huì)被動(dòng)定期地去復(fù)制leader上的數(shù)據(jù)
【leader副本選舉】
1、由控制器負(fù)責(zé)
2、選舉機(jī)制或策略
所有的副本(replicas)統(tǒng)稱為Assigned Replicas,即AR
副本同步隊(duì)列(ISR)
SR是AR中的一個(gè)子集,由leader維護(hù)ISR列表,follower從leader同步數(shù)據(jù)有一些延遲。任意一個(gè)超過閾值都會(huì)把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也會(huì)先存放在OSR中。AR=ISR+OSR
基本策略是從AR中找第一個(gè)存活的副本,且該副本在ISR中。
3、leader來維護(hù):leader有單獨(dú)的線程定期檢測ISR中follower是否脫離ISR, 如果發(fā)現(xiàn)ISR變化,則會(huì)將新的ISR的信息返回到Zookeeper的相關(guān)節(jié)點(diǎn)中。
【副本機(jī)制的好處】
通常來講副本機(jī)制的好處:
1、提供數(shù)據(jù)冗余。即使系統(tǒng)部分組件失效,系統(tǒng)依然能夠繼續(xù)運(yùn)轉(zhuǎn),因而增加了整體可用性以及數(shù)據(jù)持久性。
2、提供高伸縮性。支持橫向擴(kuò)展,能夠通過增加機(jī)器的方式來提升讀性能,進(jìn)而提高讀操作吞吐量。
3、改善數(shù)據(jù)局部性。允許將數(shù)據(jù)放入與用戶地理位置相近的地方,從而降低系統(tǒng)延時(shí)。
對(duì)于 Apache Kafka 而言,目前只能享受到副本機(jī)制帶來的第 1 個(gè)好處,也就是提供數(shù)據(jù)冗余實(shí)現(xiàn)高可用性和高持久性。
對(duì)于客戶端用戶而言,Kafka 的追隨者副本沒有任何作用,它既不能像 MySQL 那樣幫助領(lǐng)導(dǎo)者副本“抗讀”,也不能實(shí)現(xiàn)將某些副本放到離客戶端近的地方來改善數(shù)據(jù)局部性。
Broker 高水位機(jī)制
【概念】
HW即高水位,是Kafka副本對(duì)象的重要屬性,分區(qū)的高水位由leader副本的高水位表示,含義是被follower副本同步之后的位置。
對(duì)于leader新寫入的消息,consumer不能立刻消費(fèi),leader會(huì)等待該消息被所有ISR中的replicas同步后更新HW,此時(shí)消息才能被consumer消費(fèi)
【作用】
定義消息可見性,只有分區(qū)高水位以下的消息才能被消費(fèi);
幫助kafka完成副本同步,kafka是基于高水位實(shí)現(xiàn)的異步的副本同步機(jī)制。
【LEO的概念】
含義是日志末端位移(Log End Offset),下一條消息寫入的位移。
總結(jié)為什么MySQL的索引不采用kafka的索引機(jī)制?
既然kafka那么優(yōu)秀那么快,為什么MySQL的索引不采用kafka的索引機(jī)制?
我們還要考慮一個(gè)問題:InnoDB中維護(hù)索引的代價(jià)比Kafka中的要高。Kafka中當(dāng)有新的索引文件建立的時(shí)候ConcurrentSkipListMap才會(huì)更新,而不是每次有數(shù)據(jù)寫入時(shí)就會(huì)更新,這塊的維護(hù)量基本可以忽略,B+樹中數(shù)據(jù)有插入、更新、刪除的時(shí)候都需要更新索引,還會(huì)引來“頁分裂”等相對(duì)耗時(shí)的操作。Kafka中的索引文件也是順序追加文件的操作,和B+樹比起來工作量要小很多。
其實(shí)說到底還是應(yīng)用場景不同所決定的。MySQL中需要頻繁地執(zhí)行CRUD的操作,CRUD是MySQL的主要工作內(nèi)容,而為了支撐這個(gè)操作需要使用維護(hù)量大很多的B+樹去支撐。Kafka中的消息一般都是順序?qū)懭氪疟P,再到從磁盤順序讀出(不深入探討page cache等),他的主要工作內(nèi)容就是:寫入+讀取,很少有檢索查詢的操作,換句話說,檢索查詢只是Kafka的一個(gè)輔助功能,不需要為了這個(gè)功能而去花費(fèi)特別太的代價(jià)去維護(hù)一個(gè)高level的索引。前面也說過,Kafka中的這種方式是在磁盤空間、內(nèi)存空間、查找時(shí)間等多方面之間的一個(gè)折中。