前沿實踐:垃圾回收器是如何演進的?
下面將結合業界目前垃圾回收器的發展方向,介紹幾種較前沿的垃圾回收器,以便于加深對垃圾回收算法的理解。
注:如無特別說明,本文中垃圾回收器的內容都是基于 HotSpot Java 虛擬機展開的。
一 、垃圾回收器簡介
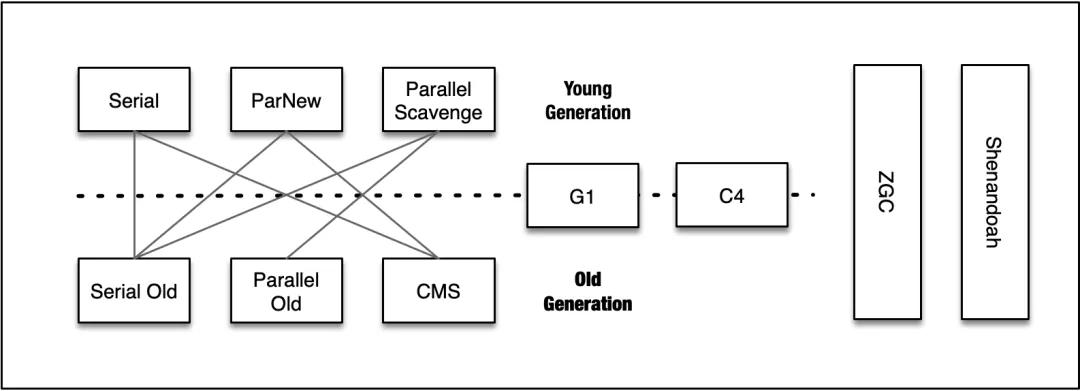
工業界的垃圾回收器,一般都是上篇中幾種垃圾回收算法的組合實現。下圖中列舉了最常見及最新的幾種垃圾回收器,大多數的垃圾回收器均采用了分代設計(或者適用于分代場景),且一般有固定的搭配使用模式,每種垃圾回收器的用法和特性在這里就不贅述了,有需要的話可以參考其他資料。圖中的垃圾回收器,還需要補充的一些內容有:
- CMS 是適用于老年代的垃圾回收器,雖然在回收過程中可能也會觸發新生代垃圾回收。CMS 在 JDK 9中被聲明為廢棄的,在JDK 14中將被移除;
- Parallel Scavenge 和大部分垃圾回收器都不兼容,原因是其實現未基于 HotSpot VM 框架;
- Parallel Scavenge + Parallel Old 的組合有自適應調節策略,適用于對吞吐量敏感的場景;
- C4 和 ZGC 可以視為是同一種垃圾回收算法的不同實現,ZGC 目前還沒有分代設計(規劃中);
- C4、ZGC、Shenandoah GC 的垃圾回收算法在多處是趨同的,同時各自也有比較獨特的設計理念。
?? 
各種垃圾回收器和垃圾回收算法間的關系如下:
- Serial:標記-復制
- Serial Old:標記-壓縮
- ParNew:標記-復制
- Parallel Scavenge:標記-復制
- Parallel Old:標記-壓縮
- CMS(Concurrent-Mark-Sweep):(并發)標記-清除
- G1(Garbage-First):并發標記 + 并行復制
- ZGC/C4:并發標記 + 并發復制
- Shenandoah GC:并發標記 + 并發復制
可以看到,如果堆空間進行了分代,那么新生代通常采用復制算法,老生代通常采用壓縮-復制算法。G1、C4、ZGC、Shenandoah GC 是幾種比較新的垃圾回收器,下面會結合算法實現,分別介紹這四種垃圾回收器的核心原理。
二、 G1 垃圾回收器
G1是從JDK 7 Update 4及后續版本開始正式提供的,從JDK 9開始G1作為默認的垃圾回收器。
G1 的垃圾回收是分代的,整個堆分成一系列大小相等的分區(Region)。新生代的垃圾回收(Young GC)使用的是并行復制的方式,一旦發生一次新生代回收,整個新生代都會被回收(根據對暫停時間的預測值,新生代的大小可能會動態改變)。老年代回收不會回收全部老年代空間,只會選擇一部分收益最高的 Region,回收時一般會搭便車——把待回收的老年代 Region 和所有的新生代 Region 放在一起進行回收,這個過程一般被稱為 Mixed GC,Young GC 和 Mixed GC 最大的不同就在于是否回收了老年代的 Region。注意:Young GC 和 Mixed GC 都是在進行對象標記,具體的回收過程與這兩個過程是獨立的,回收時 GC 線程會根據標記的結果選擇部分收益高的 Region 進行復制。從某種角度來說,G1 可視為是一種「標記-復制算法」的實現(注意這里不是壓縮算法,因為 G1 的復制過程完全依賴于之前標記階段對對象生死的判定,而不是自行從 GC Roots 出發遍歷對象引用關系圖)。
G1 老年代的標記過程大致可以分為下面四個階段:
- 初始標記階段(STW)
- 并發標記階段
- 再標記階段(STW)
- 清理階段(STW)
上面的四個階段中,有三個階段都是 STW 的,每個階段的內容就不具體敘述了。為了降低標記階段中 STW 的時間,G1 使用了記錄集(Remembered Set, RSet)來記錄不同代際之間的引用關系。在并發標記階段,GC 線程和應用線程并發運行,在這個過程中涉及到引用關系的改變,G1 使用了 SATB(Snapshot-At-The-Beginning) 記錄并發標記時引用關系的改變,保證并發結束后引用關系的正確性。實現 RSet 和 SATB 的關鍵就是之前提到的寫屏障。
G1 中的寫屏障分為 pre_write_barrier 和 post_write_barrier,如下面的代碼所示,應用 field 將要被賦予新值 value,由于 field 指向的舊的引用對象會丟失引用關系,因此在賦值之前會觸發 pre_write_barrier,更新 SATB 日志記錄,記錄下引用關系變化時舊的引用值;在正式賦值之后,會執行 post_write_barrier,更新新引用對象所在的 RSet。
SATB 和 RSet 的更新都是通過寫屏障來實現的,但是更新操作并不都是在屏障里做的,否則會對應用線程造成很大的干擾。G1 中的寫屏障實現為線程隊列+全局隊列的兩級結構,當寫屏障觸發后,記錄會首先加入到線程隊列(線程隊列是獨立、定長的)中,線程隊列區滿了后,就會加入到全局隊列區里,換一個新的、干凈的隊列繼續執行下去,全局隊列里的記錄超過一定的閾值,相關線程就會去做相應處理(更新 RSet 或是將記錄壓入標記棧中)。
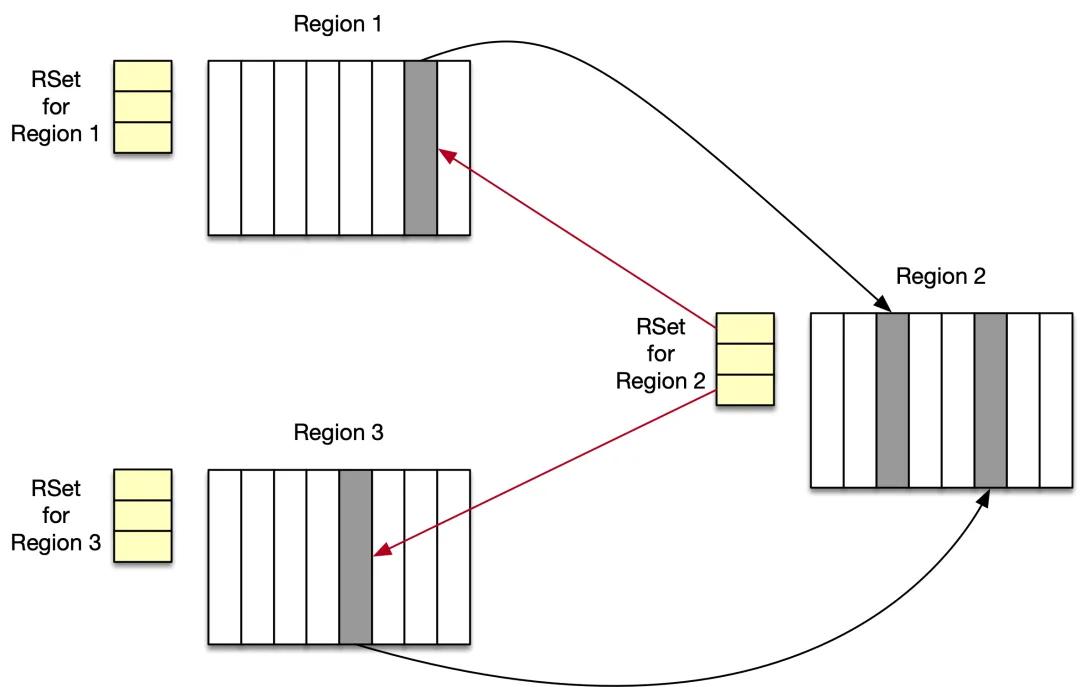
RSet
首先來看一下 RSet,這個數據結構是為了記錄對象代際之間的引用關系而提出的,目的是加速垃圾回收的速度。引用關系的記錄方式通常有兩種方式:「我引用了誰」和「誰引用了我」,前一種記錄簡單,但是在回收時需要對記錄集做全部掃描,后一種記錄復制,占用空間大,但是在回收時只需要關注對象本身,即可通過 RSet 直接定位到引用關系。G1 的 RSet 使用的是后一種「誰引用了我」的記錄方式,其數據結構可理解為一個哈希表。每次向引用類型字段賦值時,會觸發:「寫屏障 -> 線程隊列 -> 全局隊列 -> 并發 RSet 更新」這樣一個過程。
G1 RSet 記錄的是對象之間的引用關系,那到底需要記錄哪些引用關系呢?
- Region 內部的引用:無需記錄,因為垃圾回收時 Region 內對象肯定要掃描的;
- 新生代 Region 間的引用:無需記錄,因為新生代在 Young GC 和 Mixed GC 中都會被整體回收:
- 老年代 Region 間的引用:需要記錄,因為老年代回收時是按 Region 進行回收的,因此需要記錄;
- 新生代 Region 到老年代 Region 的引用:無需記錄,Mixed GC 中會把整個新生代作為 GC Roots;
- 老年代 Region 到新生代 Region 的引用:需要記錄,Young GC 時直接將這種引用加入 GC Roots。
具體在回收時,RSet 的作用是這樣的:進行 Young GC 時,選擇新生代所在的 Region 作為 GC Roots,這些 Region 中的 RSet 記錄了老年代->新生代的的跨代引用(「誰引用了我」),從而可以避免了掃描整個老年代。進行 Mixed GC 時,「老年代->老年代」之間的引用,可以通過待回收 Region 中的 RSet 記錄獲得,「新生代->老年代」之間的引用通過掃描全部的新生代獲得(前面提到過 Mixed GC 會搭 Young GC 的便車),也不需要掃描全部老年代。總之,引入 RSet 后,GC 的堆掃描范圍大大減少了。
?? 
SATB
SATB 在算法篇介紹過,其實就是在一次 GC 活動前所有對象引用關系的一個快照。之所以需要快照,是因為并發標記時,GC 線程一邊在標記垃圾對象,應用線程一邊還在生成垃圾對象,如果我們記錄下快照,以及并發標記期間引用發生過變更的對象(包括新增對象和引用發生變更的對象),則我們就可以實現一次完整的標記。
SATB 的過程可以簡單理解為:當并發標記階段引用的關系發生變化時,舊引用所指向的對象就會被標記,同時其子引用對象也會被遞歸標記,這樣快照的完整性就得到保證了。SATB 的記錄更新是由 pre_write_barrier 寫屏障觸發的,下面是 G1 論文中介紹的 SATB 原始表述,具體實現時,還是由兩級的隊列結構緩存,再由并發標記線程批量處理進入標記隊列 satb_mark_queue。
因此,G1 在結束并發標記后還有一個需要 STW 的再標記(remark)階段就可以理解了,因為如果不引入一個 STW 的過程,那么新的引用變更會不斷產生,永遠就無法達成完成標記的條件。再標記階段,因為有了SATB 的設計,則只需要掃描 satb_mark_queue 隊列里的引用變更記錄就可以對此次 GC 活動形成完整標記了(可以對比 CMS 的 remark 階段)。
三、ZGC/C4 垃圾回收器
G1 目前的發展已經相當成熟了,從眾多的測評結果上看,也達到了其最初的設計目標。但是 G1 也有下面這些不足之處:
- 堆利用率不高:原因就是引入的 RSet 占用內存空間較大,一般會達到1%~20%;
- 暫停時間較長:通常 G1 的 STW 時間要達到幾十到幾百毫秒,還不夠低。
G1 由于使用了并發標記,因此標記階段對暫停時間的影響較小,暫停時間主要來自于標記階段結束后的 Region 復制(一般占用整個 GC STW 的 80%),這個階段使用的是復制算法:GC 把一部分 Region 里的活的對象復制到空 Region 里去,然后回收原本的 Region的空間。上述過程是無法并發進行的(并發復制一般需要通過「讀屏障」來實現,G1 并未使用),因為需要一邊移動對象,同時一邊修正指向這些對象的引用(并發期間應用線程可能會訪問到這些對象),G1 雖然在復制對象時也做到了并行化,但大量對象的復制會涉及到很多內存分配、變量復制的操作,非常耗時。
ZGC 就是針對上述 G1 的不足提出的,2017 年 Oracle 將 ZGC 貢獻給 OpenJDK 社區,2018年 JEP-333 正式引入:ZGC: A Scalable Low-Latency Garbage Collector (Experimental)。ZGC 的設計思路借鑒了一款商業垃圾回收器——Azul Systems公司的的 C4(Continuously Concurrent Compacting Collector) 垃圾回收器,后者是一款分代式的、并發的、協作式垃圾回收算法,目前只在 Azul System 公司的 Zing JVM 得到實現,詳細介紹請參考論文:http://go.azul.com/continuously-concurrent-compacting-collector。ZGC 和 C4 背后的算法均是 Azul Systems 很多年前提出的 Pauseless GC,區別在于 C4 是一種分代的實現,而 ZGC 現在還是不分代的。
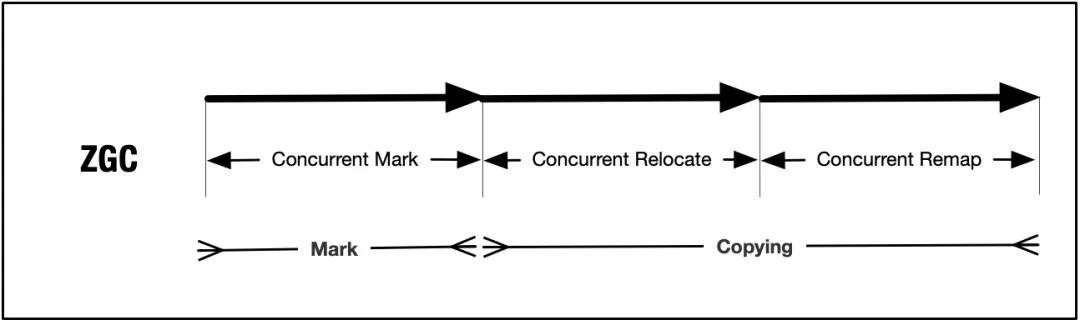
ZGC 可以視為是一種「標記-復制」算法的并發實現,其中標記階段是并發的,復制階段又分為轉移(Relocate)和重定位(Remap)兩個子階段,也都是并發的,通過全程并發,可以讓暫停時間保持在10ms以內。標記和復制看上去是兩個串行的階段,其實也是有重疊的,譬如重定位(remap)階段實際上被合并到標記階段中,即在標記的時候如果發現對象引用到老的地址,這時會先完成重定位更新對象的引用關系,然后再標記對象。
下面具體來看一下 ZGC 是如何高效地設計并發操作的。
?? 
算法設計
SATB
ZGC 在進行并發標記和并發復制時也會面臨引用關系改變造成的「漏標」和「漏轉移」,解決的方法是引入 SATB,和 G1 中通過寫屏障實現的 SATB 不同,ZGC 是通過「讀屏障」+「多視圖映射」來實現 SATB 的。讀屏障在算法篇已經介紹過了,它發生在從堆上加載一個對象引用時,后續使用該引用不會觸發讀屏障。
讀屏障是實現 SATB 的關鍵,除此之外,ZGC 引入讀屏障后,也實現了對象的并發復制,彌補了 G1 垃圾回收算法中最大的不足。讀屏障和寫屏障解決的問題是不一樣的,標記-清除算法是不需要讀讀屏障的,因為沒有內存移動的過程(壓縮或者復制),但是對于復制算法,如果不用讀屏障去跟蹤讀的情況,并發執行的應用線程可能就會讀取到錯誤的引用。引入讀屏障后,GC 線程可以并發執行,應用讀取的引用如果發生了轉移或者修改,可以在讀屏障內完成內存的轉移或者重定位,也就不會出現長時間的 STW 了。
可以通過從堆空間中加載對象的執行代碼這里對讀屏障有更直觀的感受,這里調用的load_barrier_on_oop_field_preloaded 就是讀屏障。
讀屏障觸發后,SATB 的具體執行細節就不展開了,SATB 雖然實現的方式不一樣,如 G1 中是通過寫屏障實現的,但是其核心思想是一致的:標記開始后,把引用關系快照里所有的活對象都看作是活的,如果出現了引用關系變更,則把舊的引用所指向的對象進行標記或記錄下來。
讀屏障的開銷是很大的,因為堆的讀操作頻率是遠高于寫操作的,ZGC 是如何對對象進行標記,實現高效的 SATB 算法的呢?答案是上面提到過的「多視圖映射」,下面簡單介紹下。
多視圖映射
和 G1 一樣,ZGC 將內存劃分成小的分區,在ZGC中稱為頁面(page),但是 ZGC 中的頁面大小并不是固定的,分為小頁面、中頁面和大頁面,其中小頁面大小為 2MB,中頁面大小為 32MB,而大頁面則和操作系統中的大頁面的大小一致。
多視圖映射指的是在 ZGC 的內存管理中,同一物理地址的對象可以映射到多個虛擬地址上,虛擬地址有 Marked0、Marked1 和 Remapped 三種,在 ZGC 中這三個虛擬空間在同一時間點有且僅有一個空間有效。下表中顯示了這三個地址空間的范圍,[0~4TB)對應的是Java的堆空間,該虛擬地址對應用程序可見,經 ZGC 映射后,真正使用的就是 Marked0、Marked1 和 Remapped 這三個視圖對應的地址空間,這三個視圖的切換是由垃圾回收的不同階段觸發的。
既然多個視圖映射的是同一個物理對象,那么就需要對引用(指針)進行若干改造,ZGC 在堆引用(指針)上增加了若干元數據信息:前42位保留為對象的實際地址(在源代碼中作為偏移量引用),42位地址理論上提供了4TB的堆限制,其余的位用于標記:Finalizable、Remapped、Marked1 和 Marked0 (保留一位以備將來使用),這種引用也被稱為著色指針(Color Pointers)。
為什么要使用多視圖映射呢?最直接的好處就是可以加快標記和轉移的速度。比如在標記階段,標記某個對象時只需要轉換地址視圖即可,而地址視圖的轉化非常簡單,只需要設置地址中第42~45位中相應的標記位即可。而在以前的垃圾回收器實現中,需要修改相應對象頭的標記位,而這會有內存存取訪問的開銷。在 ZGC 標記對象中無須任何對象訪問,這就是ZGC在標記和轉移階段速度更快的原因。
把讀屏障、 SATB 和多視圖映射放在一起,可以總結 ZGC 中的并發算法的核心要點為:
- SATB 保證了在并發標記和并發復制階段引用變更的正確性;
- 在并發標記階段,通過標記引用(指針)實現對對象的遍歷;
- 在并發轉移階段,讀屏障會保證并發轉移時應用線程讀出的指針為對象的新地址;
- 在并發重定位階段,讀屏障會保證應用線程可以獲取到轉移后的對象的新地址。
引用 R 大(RednaxelaFX)的話就是:與標記對象的傳統算法相比,ZGC 在指針上做標記,在訪問指針時加入 Load Barrier(讀屏障),比如當對象正被 GC 移動,指針上的顏色就會不對,這個屏障就會先把指針更新為有效地址再返回,也就是,永遠只有單個對象讀取時有概率被減速,而不存在為了保持應用與 GC 一致而粗暴整體的 Stop The World。
算法實現
下面通過一個簡單的例子看了解 ZGC 的并發執行過程。
?? 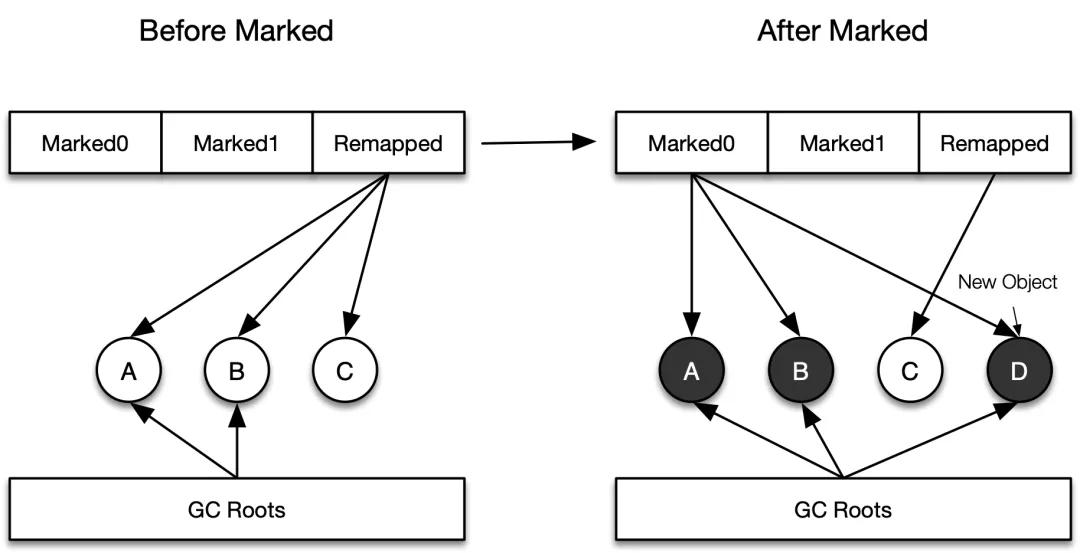
第一次執行并發標記前,整個內存空間的地址視圖被設置為 Remapped,并發標記結束后,對象的地址視圖要么是 Marked0,要么是 Remapped。
- 如果地址視圖是 Marked0,說明對象是在標記階段被標記或者是新創建的;如上圖所示 A、B 對象均可以通過 GC Roots 訪問到,屬于活躍的對象,對象 D 在并發期間被創建,也屬于活躍對象,均被映射到 Marked0 地址視圖;
- 如果地址視圖是 Remapped,說明對象在標記階段既不能通過根集合訪問到(直接或間接訪問),也沒有應用線程訪問它,所以是不活躍的,即對象所使用的內存可以被回收。上圖中的對象 C 不能從 GC Roots 訪問,屬于不活躍對象,地址視圖還是 Remapped,表示為垃圾對象。
在并發標記期間,如果應用線程訪問對象且對象的地址視圖是 Remapped,說明對象是前一階段分配的,只要把該對象的視圖從 Remapped 調整為 Marked0 就能防止對象漏標。
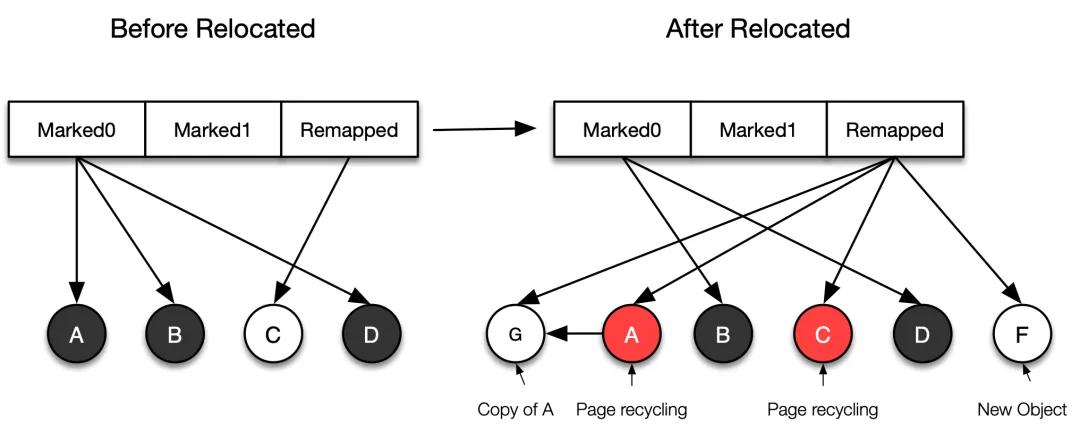
標記階段結束后,所有活躍對象的地址會被存儲在一個「對象活躍信息表」的集合中,然后進入并發轉移(Relocated)階段。轉移階段轉移線程會從「對象活躍信息表」中把活躍對象轉移到新的內存中,并回收對象轉移前的內存空間(注意:如果頁面不需要轉移,那么頁面里面的對象也就不需要轉移)。并發轉移結束后,對象的地址視圖要么是 Remapped,要么是 Marked0。
- 如果地址視圖是 Marked0,說明該對象在垃圾回收的標記階段已經被標記,但是在轉移階段未被轉移(如下圖中的 B 和 D);
- 如果地址視圖是 Remapped,說明對象在并發轉移階段被轉移或者被訪問過(如下圖中的 G 和 F,C 因為不活躍可能就直接被回收了)。
?? 
在并發轉移階段,如果應用線程訪問的對象在對象活躍信息表中,且對象的地址視圖為 Marked0,說明對象是標記階段標記的活躍對象,所以需要轉移對象,對象轉移以后,對象的地址視圖從 Marked0 調整為 Remapped。
?? 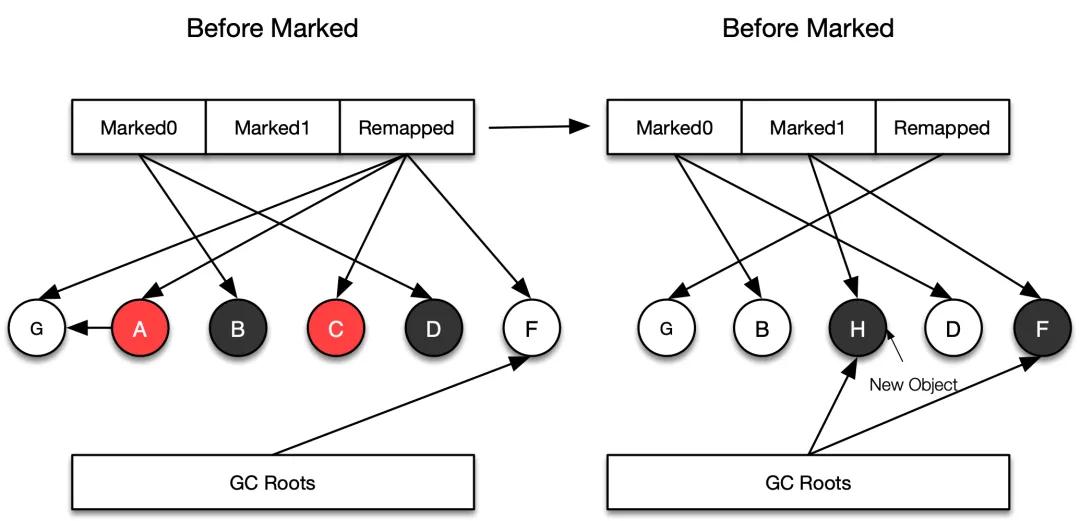
并發轉移結束后,會再次進入下一次的標記階段。新的標記階段為了區分「本次標記的活躍對象」和「上次標記的活躍對象」,使用了 Marked1 來標識本次并發標記的結果,即:用 Marked1 表示本次垃圾回收中識別的活躍對象(上圖中的 H 和 F),用 Marked0 表示前一次垃圾回收的標記階段被標記過的活躍對象,且該對象在轉移階段未被轉移,但是在本次垃圾回收中被識別為不活躍對象(上圖中的 B 和 D)。注意:在并發轉移完活躍對象之后,引用還指向對象轉移之前的地址,ZGC 通過「對象轉移地址信息表」存儲頁面對象轉移前和轉移后的地址,在新一輪垃圾回收啟動后,在標記時會執行重定位的操作。
ZGC 雖然是全程并發設計的,但也還是有若干個 STW 的階段的,包括并發標記中的初始化標記和結束標記階段,并發轉移中的初始轉移階段等。事實上,完全沒有 STW 的垃圾回收器是不存在的,即便是 Azul 的 PGC(原汁原味基于 Pauseless GC 算法實現),也是有非常短暫的 STW 階段,譬如 GC Roots 的掃描。
四、Shenandoah 垃圾回收器
Shenandoah GC 最早是由 Red Hat 公司發起的,后來被貢獻給了 OpenJDK,2014 年通過 JEP-189:A Low-Pause-Time Garbage Collector (Experimental)正式成為 OpenJDK 的開源項目,Shenandoah GC 出現的時間比 ZGC 要早很多,因此發展的成熟度和穩定性相較于 ZGC 來說更好一些,實現了包括括C1屏障、C2屏障、解釋器、對 JNI 臨界區域的支持等特性。
和 ZGC 一樣,Shenandoah GC 也聚焦在解決 G1 中產生最長暫停時間的「并行復制」問題,通過與 ZGC 不一樣的方式,實現了「并發復制」,在 Shenandoah GC 中也未區別年輕代與老年代。ZGC實現并發復制的關鍵是:讀屏障 + 基于著色指針(Color Pointers)的多視圖映射,而 Shenandoah GC 實現并發復制的關鍵是:讀寫屏障 + 轉發指針(brook Pointers),轉發指針(brook Pointers)的原理將在下面詳細介紹,其過程可以參考論文:Trading Data Space for Reduced Time and Code Space in Real-Time Garbage Collection on Stock Hardware。
Shenandoah GC 的 回收周期和 ZGC 非常類似,大致也可以分為并發標記和并發復制兩個階段,在并發標記階段,也是通過 讀屏障+ SATB 來實現的,并發復制階段也分為并發轉移和并發重定位兩個子階段。
算法設計
并發標記階段的 SATB 在這里就不詳細介紹了,這里主要看一下 Shenandoah GC 是如何實現并發復制的。
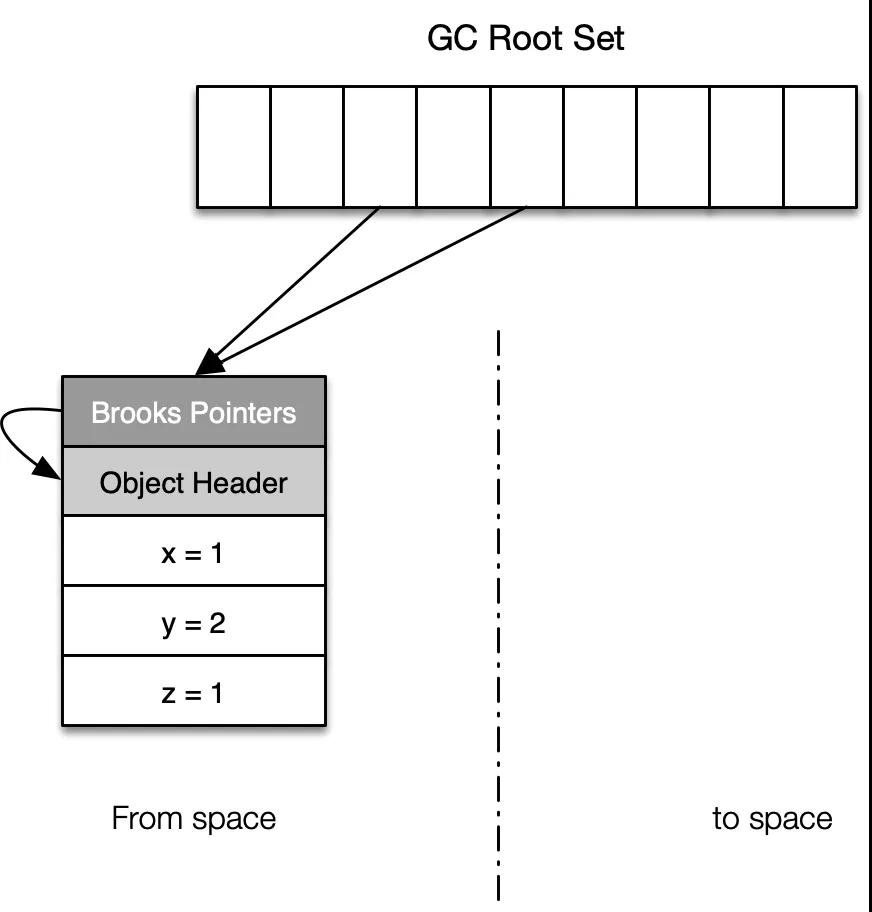
Shenandoah GC 將堆分成大量同樣大小的分區(Region) ,分區大小從 256KB 到 32MB不等。在進行垃圾回收時,也只是會回收部分堆區域。上面提到,Shenandoah GC 實現高效讀屏障的關鍵是增加了 轉發指針(brook Pointers)這個結構,這是對象頭上增加的一個額外的數據,在讀寫屏障觸發時時可以通過 brook Pointer 直接訪問對象。轉發指針要么指向對象本身,要么指向對象副本所在的空間,如下圖所示:
?? 
Shenandoah GC 使用寫屏障+轉發指針完成了并發復制,其過程可以用下面的偽代碼表示:
上面并發轉移的詳細過程如下:首先判斷待轉移對象是否在待回收集合中(這個集合根據標記階段的結果生成),同時轉移指針是否指向了自己,如果沒有在待收回集合,則不用轉移,如果對象的轉移指針已經指向了其他地址,說明已經轉移過了,也不用轉移;然后進行對象復制;對象復制結束后,會通過 CAS 的方式更新轉移指針的值,使其指向新的復制對象所在的堆空間地址,如果 CAS 失敗,會多次重試。
Shenandoah GC 使用讀屏障+轉發指針保證轉移過程中或轉移結束后,應用線程可以讀取到真實的引用地址,保證了數據的一致性,因為如果不這樣做,可能會導致一些線程使用舊對象,而另一些線程使用新對象。
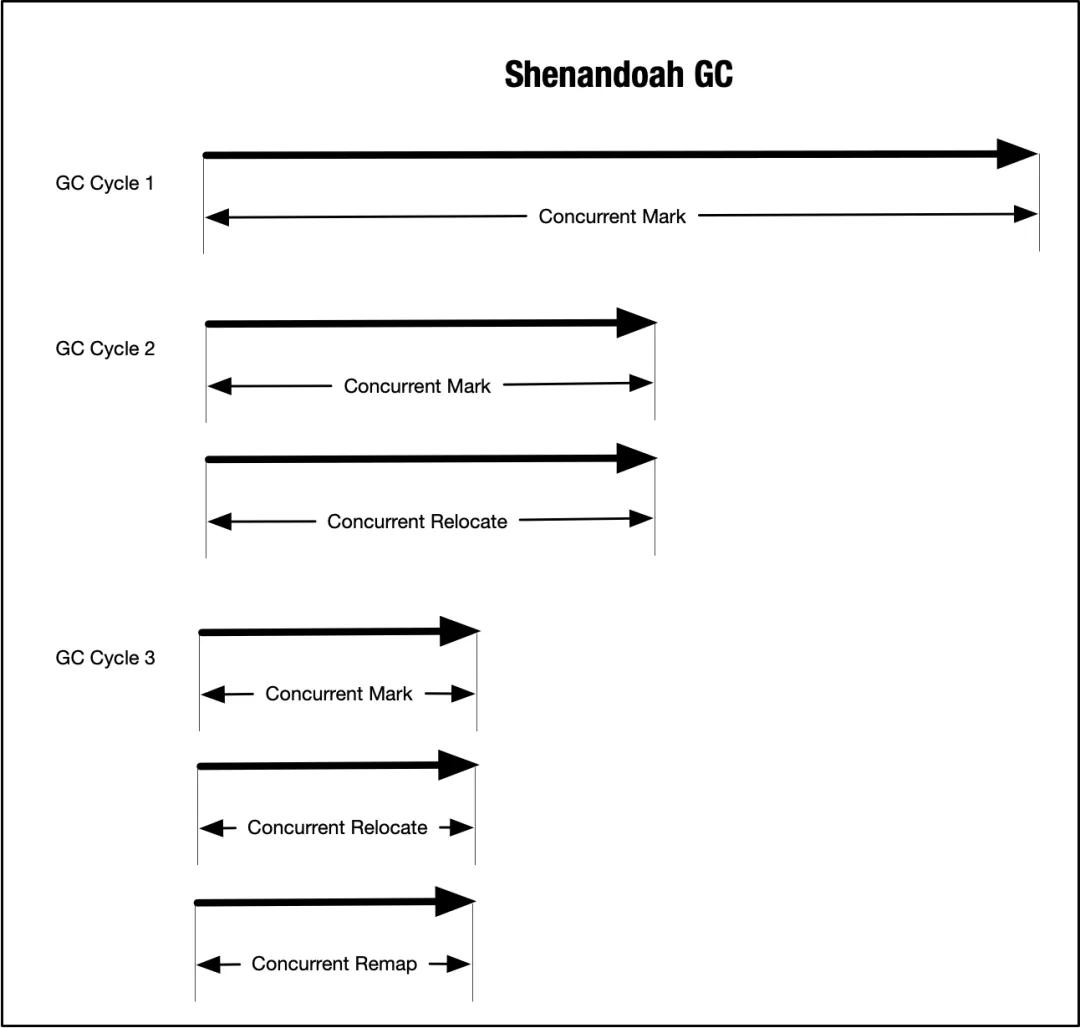
需要注意的是,在 ZGC 中并發重定位和并發標記階段是重合的,而在 Shenandoah GC 在某些情況下,可能會把并發標記、并發轉移和并發重定位合并到同一個并發階段內完成,這種回收方式在 Shenandoah GC 中被稱為遍歷回收,細節請參考相關資料。如下圖所示,第1個回收周期會進行并發標記,第2回收周期會進行并發標記和并發轉移,第3個以后的回收周期會同時執行并發標記、并發轉移和并發重定位。
?? 
算法實現
我們來看一下并發復制的具體過程。
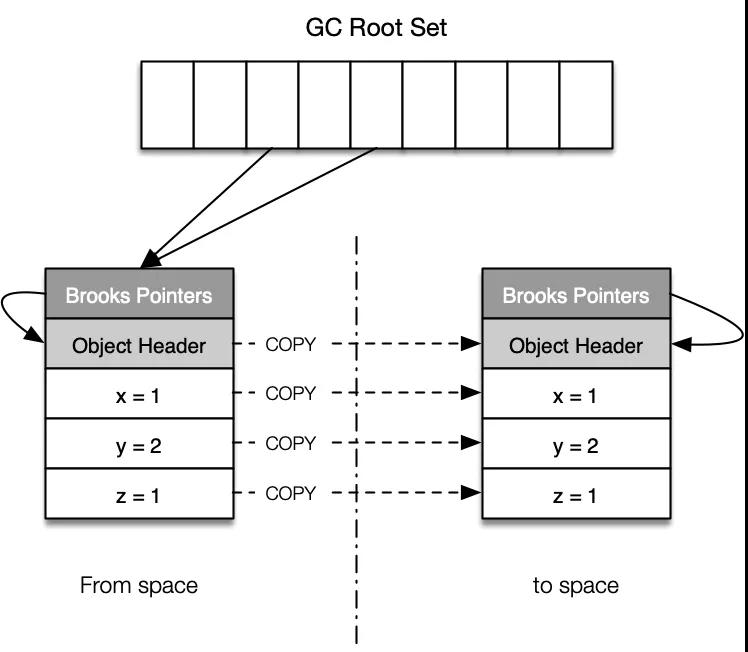
步驟1:將對象從 From 復制到 to 空間,同時將新對象的轉移指針指向新對象自己。
?? 
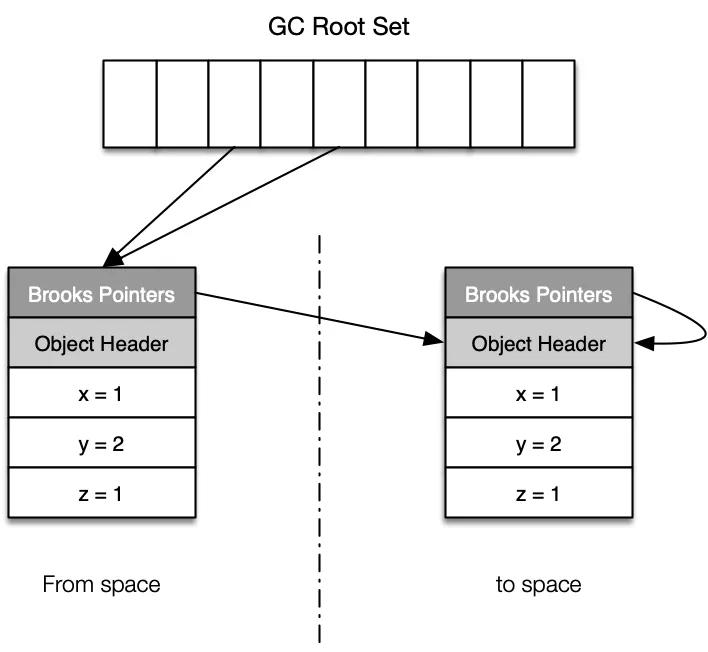
步驟2:將舊對象的轉移指針通過 CAS 的方式指向新對象。
?? 
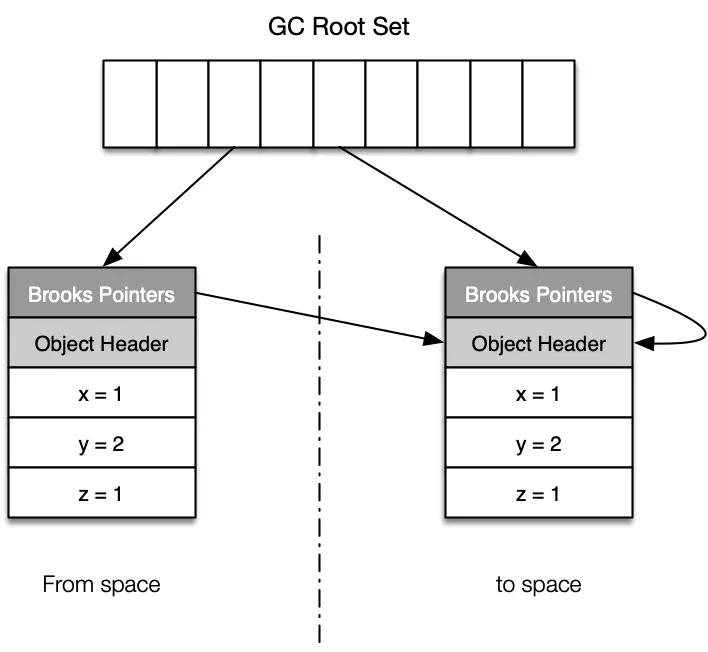
步驟3:將堆中其他指向舊對象的引用,更新為新對象的地址,如果在這個過程中有應用線程訪問到了舊對象,則會通過讀屏障的方式將新對象的地址返回給新的應用。
?? 
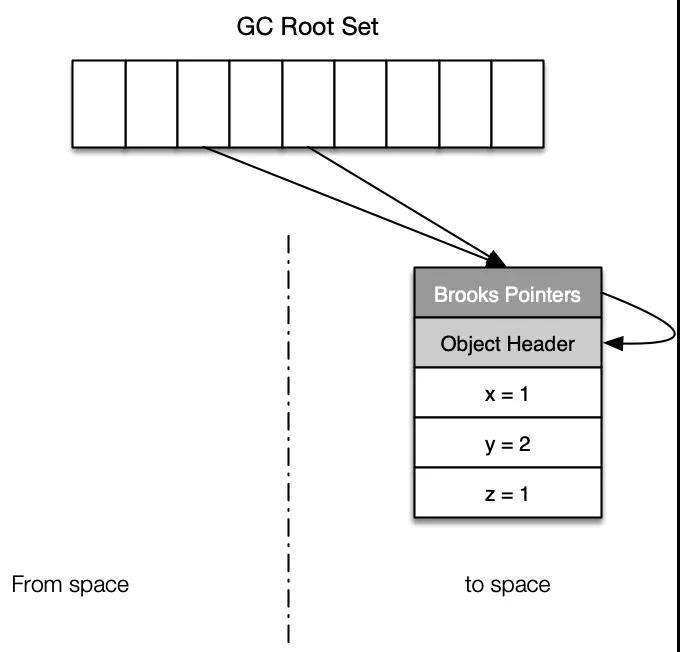
步驟4:所有的引用被更新,舊對象所在的分區可以被回收。
?? 
再次回顧一下 Shenandoah GC 里使用的各種屏障:讀對象時,會首先通過讀屏障來解析對象的真實地址,當需要更新對象(或對象的字段),則會觸發寫屏障,將對象從 From 空間復制到 to 空間。讀寫屏障在底層的應用,可以用下面的一個例子去理解。
Shenandoah GC 中讀寫屏障出現的位置:
一言以蔽之,Shenandoah GC 的并發復制是基于讀屏障+寫屏障共同實現的( ZGC 只使用了讀屏障)。Shenandoah GC 中所有的數據寫操作均會觸發寫屏障,包括對象寫、獲取鎖、hash code 的計算等,因此在具體實現時 Shenandoah GC 對寫屏障也有若干的優化(譬如從循環邏輯中移除寫屏障)。Shenandoah GC 還使用了一種稱之為「比較屏障」的機制來解決對象引用間的比較操作,特別是同一個對象分別處于 From 和 to 空間時的比較。此外,Shenandoah GC 里屏障也不需要特殊的硬件支持和操作系統支持。
Shenandoah GC 更適合用在大堆上,如果CPU資源有限,內存也不大,比如小于20GB,那么就沒有必要使用Shenandoah GC。Shenandoah GC 在降低了暫停時間的同時,也犧牲了一部分的吞吐,如果對吞吐有較高的要求,則還是建議使用傳統的基于 STW 的 GC 實現,譬如 Parallel 系列垃圾回收器。
五、總結與回顧
在這一篇文章中,我們看到了幾種比較前沿的垃圾回收器:G1/C4/ZGC/Shenandoah GC,在它們的諸多實現細節中,我們也可以看到 Java 垃圾回收器的一大技術趨勢:在大內存的前提下,通過并發的方式降低 GC 算法在標記和轉移對象時對應用程序的影響。CMS 做到了并發標記,G1降低了并發標記的成本,同時還通過并行復制的方式對部分堆內存進行了整理,ZGC、C4、Shenandoah GC 進一步降低了并發標記時的 STW 的時間,同時通過并發復制的方式將對象轉移時的暫停時間最小化。并發算法降低了應用暫停的時間,但與此同時我們也需要看到:并發算法可以正常執行的前提是「垃圾回收的速度大于對象的分配速度」,這也就意味著并發算法需要更大的堆空間,同時需要預留部分空間用來「喘息」。
在并發算法中,讀寫屏障和SATB是非常關鍵的,它們共同保證了并發操作時引用關系的正確性,相信通過對上述垃圾回收器的介紹,可以對這幾個概念理解得更加透徹。
參考資料
[1]http://dinfuehr.github.io/blog/a-first-look-into-zgc/
[2]https://rkennke.wordpress.com/2013/06/10/shenandoah-a-pauseless-gc-for-openjdk/
[3]https://shipilev.net/talks/devoxx-Nov2017-shenandoah.pd
[4]http://go.azul.com/continuously-concurrent-compacting-collector
[5]https://dl.acm.org/doi/10.1145/800055.802042
[6]http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.63.6386&rep=rep1&type=pdf
[7]https://www.infoq.com/articles/tuning-tips-G1-GC/
[8]https://developers.redhat.com/blog/2019/06/27/shenandoah-gc-in-jdk-13-part-1-load-reference-barriers/
【本文為51CTO專欄作者“阿里巴巴官方技術”原創稿件,轉載請聯系原作者】