













訪問數組的任意位置元素的性能真的一樣?
在我們的觀念當中,數組成員訪問的時間復雜度是O(1),每個成員都可以一次定位,因此訪問時間應該是一樣的。
那如果我說,現在有一個一千萬元素的數組,那么訪問第一個元素與訪問最后一樣元素的時間是一樣的嗎?這個時候你會不會有所猶豫呢?
實際動手驗證
實踐是檢驗真理的唯一手段。空想沒用,我們動手實際測試一下。我們實現如下所示的代碼,在該代碼中我們創建一個全局的數組,數組的大小是一千萬個元素。然后分別對第一個元素和最后一個元素賦值,并在賦值前后記錄時間。
- #define BUF_SIZE 10000000 //一千萬個元素
- int test_array[BUF_SIZE] = {};
- int main( int argc, char* argv[] )
- {
- long time1;
- long time2;
- time1 = get_time(); //獲取時間,單位是納秒
- test_array[0] = 1; //訪問第一個元素
- time2 = get_time();
- printf("access first item time: %ld\n", time2-time1);
- time1 = get_time();
- test_array[BUF_SIZE-1] = 1; //訪問最后一個元素
- time2 = get_time();
- printf("access last item time: %ld\n", time2- time1);
- return(0);
- }
完成代碼后,我們編譯運行一下。為了得到穩定可靠的結果,我們多運行幾次。得到的結果如下所示。
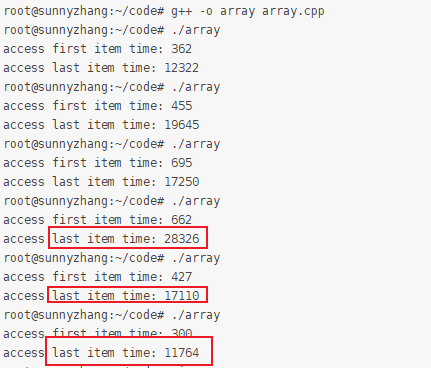
從測試結果可以看出,訪問最后一個元素的性能明顯要比訪問第一個元素慢得多,有幾十倍的性能差異!
原因分析
要想搞清楚上述問題的原因,需要更加深入的理解計算機的原理,包括可執行程序的內存布局、操作系統進程的原理以及硬件層面的一些知識。接下來我們將逐步介紹相關內容,抽絲剝繭,搞清楚為什么有如此明顯的性能差異。
我們知道用戶態的程序都是運行在虛擬空間的,每個程序都有自己4GB的虛擬空間。這個虛擬空間又稱為虛擬內存。程序的虛擬內存并不是即刻分配的,而是按需分配。也就是說,只有在用戶訪問該部分內存的數據的時候,操作系統才會分配對應的物理內存,然后將數據加載到內存中。顯然,這種從硬盤再讀取數據的速度肯定要比直接訪問內存慢的多。
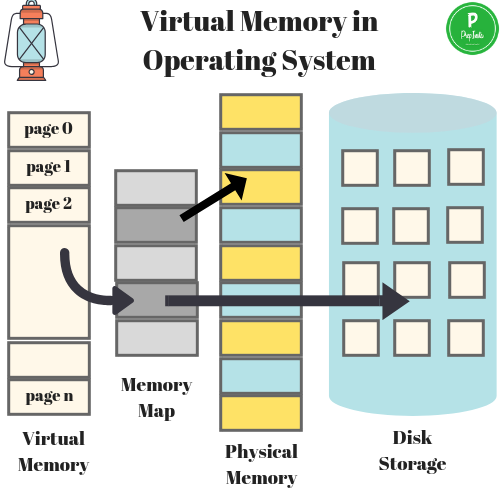
現代的CPU為了提高系統采用了多級緩存和流水線技術。CPU會根據程序的指令運行情況將部分數據或者指令預加載到緩存當中,這樣接下來就可以直接從從緩存讀取數據了。
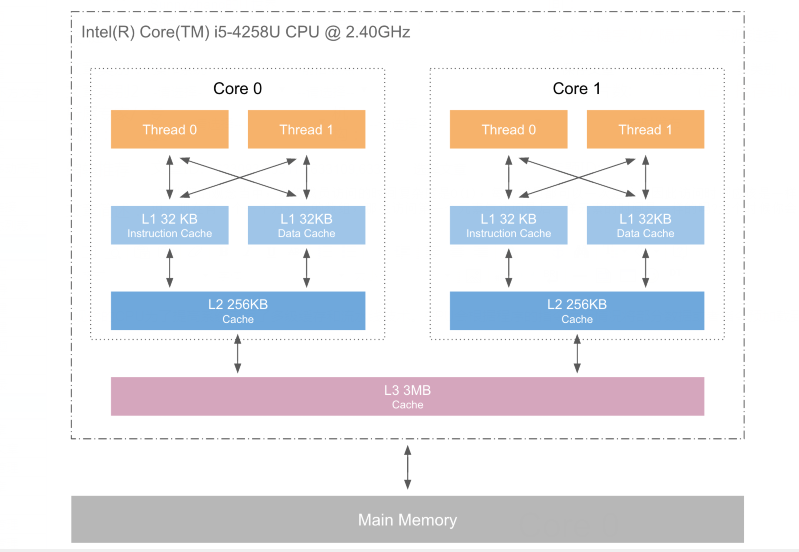
根據存儲性能金字塔的數據,從緩存讀取數據的性能是從內存讀取性能的10倍以上。因此,如果代碼沒有規律,CPU無法預取數據和指令,那么程序的運行效率肯定會很低。
扯了這么遠,讓我們回到題目本身。由于這里數組比較大,因此當訪問第一個元素的時候,第一千萬個元素肯定是沒有被預讀的,之后訪問該數據大概率會發生缺頁中斷。所以,訪問第一個元素和最后一個元素在性能上是有差異的。
進一步的驗證
有了上面的分析,我們可以再做進一步的驗證。比如我們可以連續兩次訪問最后一個元素,看看兩者的區別。
- int main( int argc, char* argv[] )
- {
- long time1;
- long time2;
- time1 = get_time();
- test_array[0] = 1;
- time2 = get_time();
- printf("access first item time: %ld\n", time2-time1);
- time1 = get_time();
- test_array[BUF_SIZE-1] = 1; // 第一次訪問最后一個元素
- time2 = get_time();
- printf("access last item time: %ld\n", time2- time1);
- time1 = get_time();
- test_array[BUF_SIZE-1] = 1; // 第二次訪問最后一個元素
- time2 = get_time();
- printf("access last item time: %ld\n", time2- time1);
- return(0);
- }
修改完代碼之后,執行該程序。同樣,我們多次執行該程序,確保結果穩定。通過下面執行結果可以看到,在第二次執行是其時間與訪問第一個元素相當,已經沒有那么明顯的差異了。
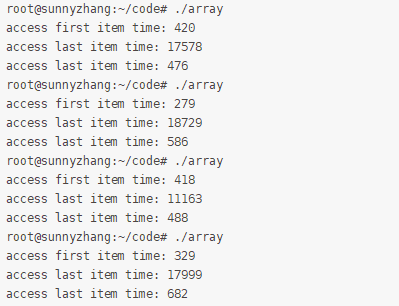
通過上面的學習,大家是不是覺得深入學習計算機原理層面的重要性了。關于更多計算機深層次的內容,我們后面會繼續分享給大家。













