跟隨杠精的視角一起來了解Redis的主從復制
本文轉載自微信公眾號「SH的全棧筆記」,作者SH 。轉載本文請聯系SH的全棧筆記公眾號。
雖然說單機的Redis性能很好,也有完備的持久化機制,那如果你的業務體量真的很大,超過了單機能夠承載的上限了怎么辦?不做任何處理的話Redis掛了怎么辦?帶著這個問題開始我們今天的主題-「Redis高可用」,由于篇幅原因,本章就只聊聊主從復制。
為啥要先從主從復制開始聊,是因為「主從復制」可以說是整個Redis高可用實現的基石,你可以先有這么一個概念,至于具體為什么是基石,這個后面聊到Sentinel和Redis集群的時候會說到。
首先我們需要知道,對于我們開發人員來說,為什么需要「主從架構」?一個Redis實例難道不行嗎?
其實除了開篇提到的負載超過了Redis單機能夠處理的上限,還有一種情況Redis也無法保證自身的高可用性。那就是即便Redis能夠扛住所有流量,但是如果這個Redis進程所在的機器掛了呢?請求會直接調轉槍口,大量的流量會瞬間把你的DB打掛,然后你就可以背個P0,打包回家了。
而且,假設你對Redis的需求真的超過了單機的容量,你怎么辦?搞多臺獨立的Redis實例嗎?那如果用戶緩存的數據這一次存在了實例一,下一次如果用戶又訪問到了實例二,難道又要去走一遍DB嗎?除非你能夠維護好用戶和Redis實例的對應關系(但是通常這樣的邏輯比較復雜),否則部署多個Redis實例也就失去了它的意義,沒有辦法做到橫向擴展了。
那換成主從架構就能解決這個問題嗎?
我們可以從一個圖來直觀的了解一下。
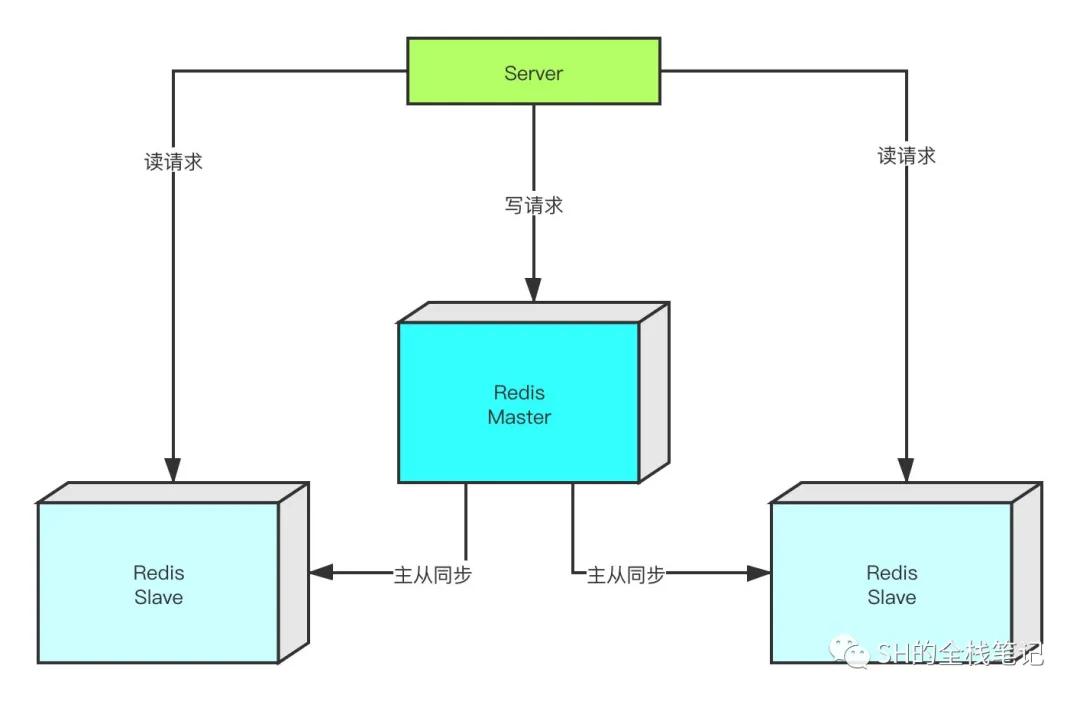
Redis主從復制
在主從同步中,我們將節點的角色劃分為master和slave,形成「一主多從」。slave對外提供讀操作,而master負責寫操作,形成一個讀寫分離的架構,這樣一來就能夠承載更多的業務請求。
在多數的業務場景下,對于Redis的「讀操作」都要多于「寫操作」,所以當讀請求量特別大的時候,我們可以通過增加slave節點來使Redis扛住更多的流量。
你這不行啊老弟,你往master寫數據,那我要是連接到slave上去了,不就拿不到之前的數據了?
我這個小標題的不是寫了嗎?「主從復制」,slave會按照某種策略從master同步數據。Redis中我們可以通過slaveof命令讓一個Redis實例去復制(replicate)另外一臺Redis的狀態。被復制的Redis實例就是master節點,而執行slaveof命令的機器就是slave節點。
Redis的主從復制分為兩個步驟,分別是「同步」和「命令傳播」。
「同步操作」用于將Master節點內存狀態復制給Slave節點,而「命令傳播」則是在同步時,客戶端又執行了一些「寫」操作改變了服務器的狀態,此時master節點的狀態與同步操作執行的時候不一致了,所以需要命令傳播來使master和slave狀態重新一致。
同步的大致的流程如下:
- slave節點向master節點發送sync命令
- master收到sync命令之后會執行bgsave命令,Redis會fork出一個子進程在后臺生成RDB文件,同時將同步過程中的寫命令記錄到緩沖區中
- 文件生成后,master會把RDB文件發送給slave,從服務器接收到RDB文件會將其載入內存
- 然后master將記錄在緩沖區的所有寫命令發送給slave,slave對這些命令進行「重放」,將其數據庫的狀態更新至和master一致
為了讓大家更加清晰的認識到這個過程,我們通過圖再來了解一下。
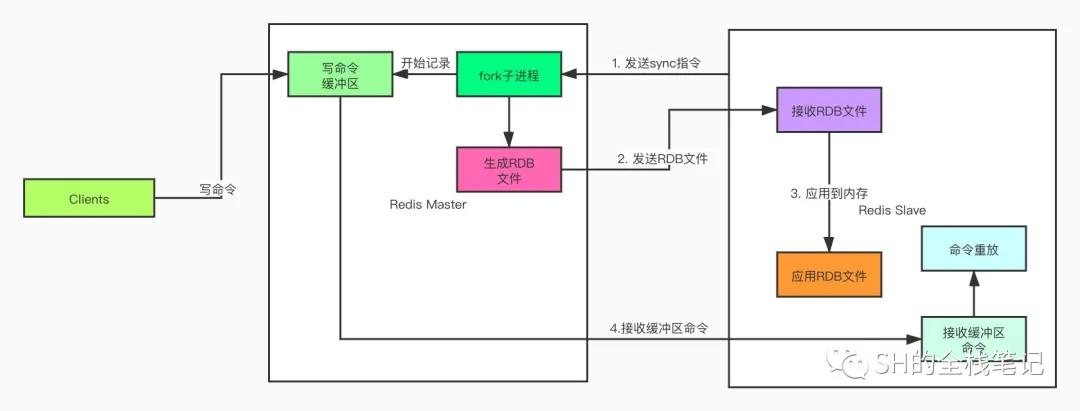
Redis主從復制
那如果同步完了之后slave又掛了咋辦?slave重啟之后很可能就又跟maste不一致了?
的確是這樣,這就涉及到一個名詞叫「斷點續傳」了。上面討論的是slave第一次連接到master,會執行「全量復制」,而針對上面這種情況,Redis新老版本處理方式不一樣。
Redis2.8之前,當主從完成了同步之后,slave如果斷線重連,向master發送sync命令,master會將全量的數據再次同給slave。
但是我們會發現一個問題,就是大部分數據都是有序的,再次全量同步顯得沒有必要。而在 Redis2.8之后,為了解決這個問題,便使用了psync命令來代替sync。
簡單來說psync命令就是將slave斷線期間master接收到的寫命令全部發送給slave,slave重放之后狀態便與master一致了。
呵呵,就這?那你知道psync具體怎么實現的嗎?還是說就只會用用?
psync的實現依賴于主從雙方共同維護的offset偏移量。
每次master向slave進行「命令傳播」,傳播了多少個字節的數據,就將自己的offset加上傳播的字節數。而slave每次收到多少字節的數據,也會同樣的更新自己的offset。
基于offset,只需要簡單的比對就知道當前主從的狀態是否是一致的了,然后基于offset,將對應偏移量所對應的指令傳播給slave重放即可。所以即使同步的時候slave掛掉了,基于offset,也能達到斷點續傳的效果。
不是吧不是吧,那master也掛了呢?你slave重新啟動之后master的數據也更新了,按照你的說法,這兩永遠不可能達到數據一致了
這個問題Redis的確也有想到,實際上除了offset之外,slave斷線重連之后還會帶上上一個master的實例的runid,每個服務實例都有自己的唯一的runid,只要Redis服務重啟,其runid就會發生改變。
master收到這個runid之后會判斷是否與自己當前的runid一致,如果一致說明斷線之前還是與自己建立的連接,而如果不一致就說明slave斷線期間,master也發生了宕機,此時就需要將數據「全量同步」給slave了。
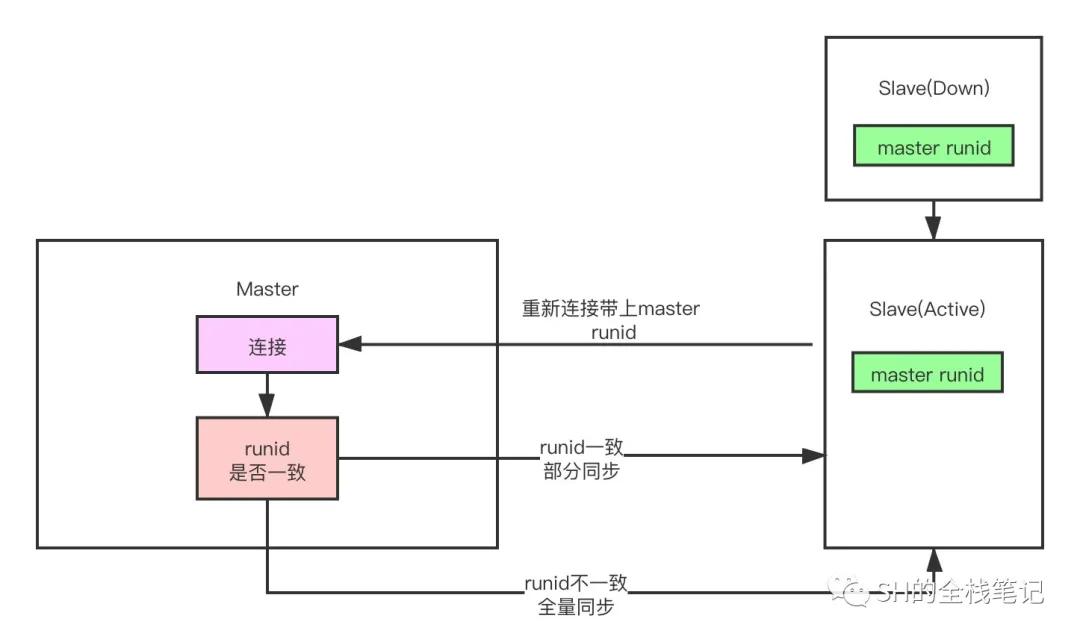
redis-runid
就算你能解決這個問題,但是你就維護了一個偏移量,偏移量對應的命令從哪兒來?天上掉下來嗎?我哪兒知道這些命令是啥?
的確,我們需要通過這個offset去拿到真正需要的數據—也就是指令,而Redis是通過「復制積壓緩沖區」來實現的。
名字高大上,實際上就是一隊列。就跟什么遞歸、輪詢、透傳一樣,聽著高大上,實際上簡單的一匹。言歸正傳,復制積壓緩沖區的默認大小為1M,Redis在進行「命令傳播」時,除了將寫命令發送給slave,還會將命令寫到「復制積壓緩沖區」內,并和當前的offset關聯起來。這樣一來就能夠通過offset獲取到對應的指令了。
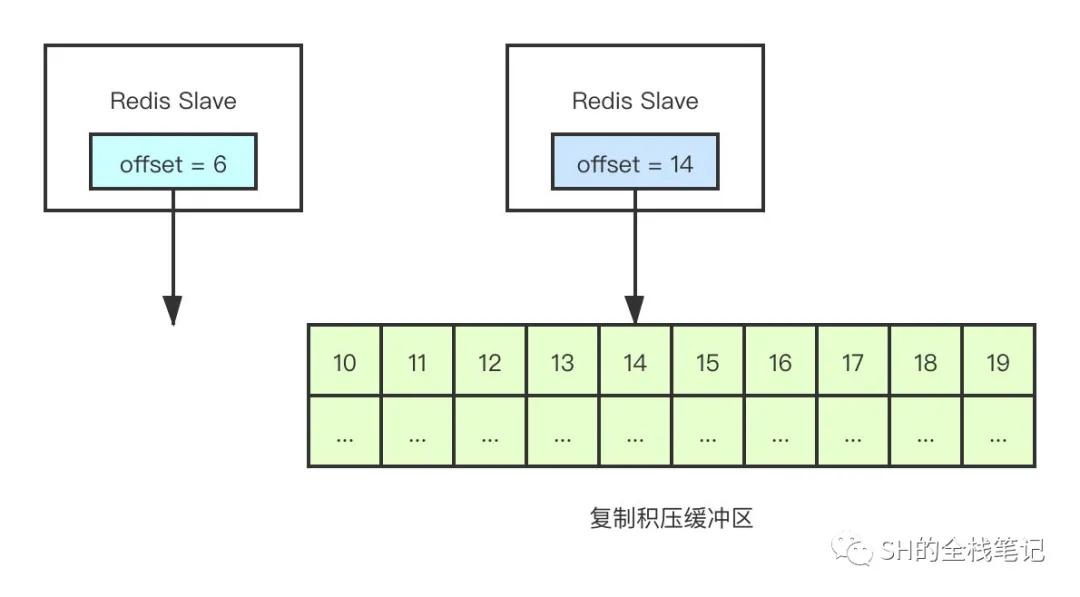
redis-backlog
但是由于緩沖區的大小有限,如果slave的斷線時間太久,復制積壓緩沖區內早些時候的指令就已經被新的指令覆蓋掉了,此處可以理解為一個隊列,早些時候入隊的元素已經被出隊了。
由于沒有相對應的offset了,也就無法獲取指令數據,此時Redis就會進行「全量同步」。當然,如果offset還存在于復制積壓緩沖區中,則按照對應的offset進行「部分同步」。
基于以上的全量、增量的主從復制,能夠在master出現故障的情況下,進行主從的切換,保證服務的正常運行。除此之外還能解決異常情況下數據丟失的問題。基于讀寫分離的策略還能夠提高整個Redis服務的并發量。
可別吹了,你說的這個什么「主從復制」就沒啥缺點嗎?
其實是有的,例如剛剛提到的主從的切換,如果不用現成的「HA」框架,這個過程需要程序員自己手動的完成,同時通知服務調用方Redis的IP發生了變化,這個過程可以說是十分的復雜,甚至還可能涉及到代碼配置的改動。而且之前的slave復制的可都是掛掉的master,還得去slave上更改其復制的主庫,就更加復雜了。
除此之外,雖然實現了讀寫分離,但是由于是「一主多從」的架構,集群的「讀請求」可以擴展,但是「寫請求」的并發是有上限的,那就是master能夠扛住的上限,這個沒有辦法擴展。