大數據基礎:Spark工作原理及基礎概念
一、Spark 介紹及生態
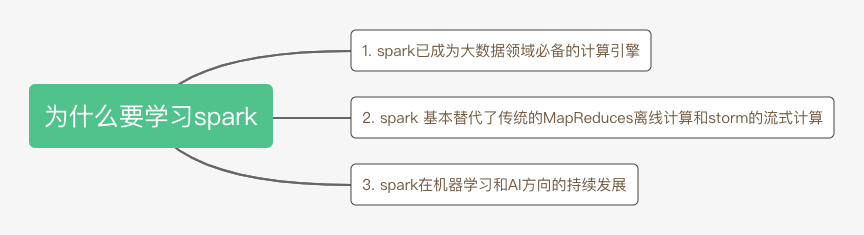
Spark是UC Berkeley AMP Lab開源的通用分布式并行計算框架,目前已成為Apache軟件基金會的頂級開源項目。至于為什么我們要學習Spark,可以總結為下面三點:
1. Spark相對于hadoop的優勢
(1)高性能
Spark具有hadoop MR所有的優點,hadoop MR每次計算的中間結果都會存儲到HDFS的磁盤上,而Spark的中間結果可以保存在內存,在內存中進行數據處理。
(2)高容錯
- 基于“血統”(Lineage)的數據恢復:spark引入了彈性分布式數據集RDD的抽象,它是分布在一組節點中的只讀的數據的集合,這些集合是彈性的且是相互依賴的,如果數據集中的一部分的數據發生丟失可以根據“血統”關系進行重建。
- CheckPoint容錯:RDD計算時可以通過checkpoint進行容錯,checkpoint有兩種檢測方式:通過冗余數據和日志記錄更新操作。在RDD中的doCheckPoint方法相當于通過冗余數據來緩存數據,而“血統”是通過粗粒度的記錄更新操作來實現容錯的。CheckPoint容錯是對血統檢測進行的容錯輔助,避免“血統”(Lineage)過長造成的容錯成本過高。
(3)spark的通用性
spark 是一個通用的大數據計算框架,相對于hadoop它提供了更豐富的使用場景。
spark相對于hadoop map reduce兩種操作還提供了更為豐富的操作,分為action(collect,reduce,save…)和transformations(map,union,join,filter…),同時在各節點的通信模型中相對于hadoop的shuffle操作還有分區,控制中間結果存儲,物化視圖等。
2. spark 生態介紹
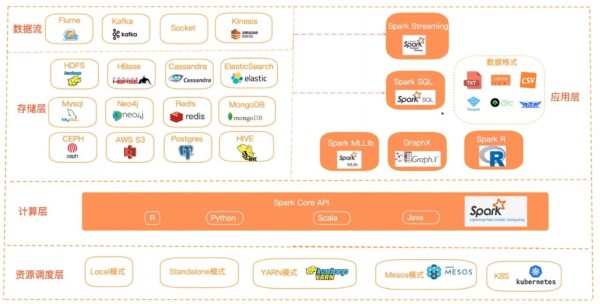
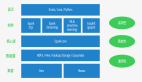
Spark支持多種編程語言,包括Java、Python、R和Scala。在計算資源調度層支持local模式,standalone模式,yarn模式以及k8s等。
同時spark有多組件的支持應用場景,在spark core的基礎上提供了spark Streaming,spark SQL,spark Mllib,spark R,GraphX等組件。
spark Streaming用于實時流計算,spark SQL旨在將熟悉的SQL數據庫查詢與更復雜的基于算法的分析相結合,GraphX用于圖計算,spark Mllib用于機器學習,spark R用于對R語言的數據計算。
spark 支持多種的存儲介質,在存儲層spark支持從hdfs,hive,aws等讀入和寫出數據,也支持從hbase,es等大數據庫中讀入和寫出數據,同時也支持從mysql,pg等關系型數據庫中讀入寫出數據,在實時流計算在可以從flume,kafka等多種數據源獲取數據并執行流式計算。
在數據格式上spark也支持的非常豐富,比如常見的txt,json,csv等格式。同時也支持parquet,orc,avro等格式,這幾種格式在數據壓縮和海量數據查詢上優勢也較為明顯。
二、spark 原理及特點
1. spark core
Spark Core是Spark的核心,其包含如下幾個部分:
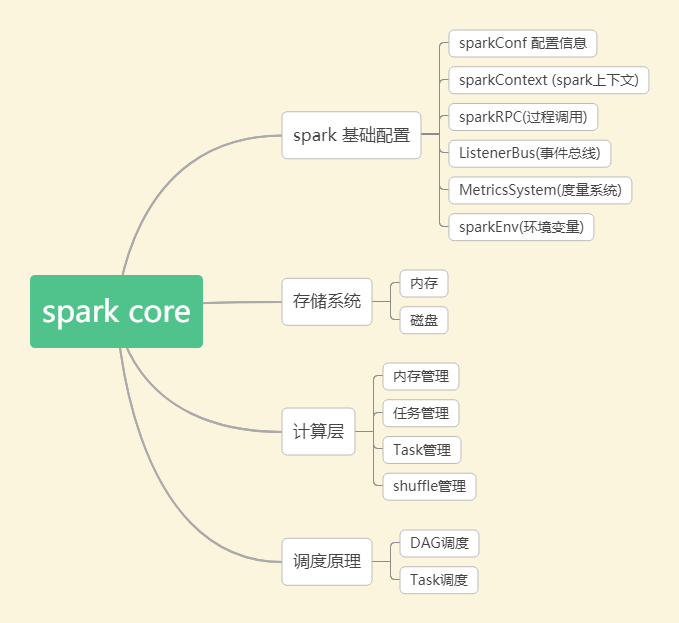
(1)spark 基礎配置
sparkContext是spark應用程序的入口,spark應用程序的提交和執行離不開sparkContext,它隱藏了網絡通信,分布式部署,消息通信,存儲體系,計算存儲等,開發人員只需要通過sparkContext等api進行開發即可。
sparkRpc 基于netty實現,分為異步和同步兩種方式。事件總線主要用于sparkContext組件間的交換,它屬于監聽者模式,采用異步調用。度量系統主要用于系統的運行監控。
(2)spark 存儲系統
它用于管理spark運行中依賴的數據存儲方式和存儲位置,spark的存儲系統優先考慮在各節點以內存的方式存儲數據,內存不足時將數據寫入磁盤中,這也是spark計算性能高的重要原因。
我們可以靈活的控制數據存儲在內存還是磁盤中,同時可以通過遠程網絡調用將結果輸出到遠程存儲中,比如hdfs,hbase等。
(3)spark 調度系統
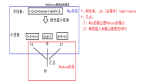
spark 調度系統主要由DAGScheduler和TaskScheduler組成。
DAGScheduler 主要是把一個Job根據RDD間的依賴關系,劃分為多個Stage,對于劃分后的每個Stage都抽象為一個或多個Task組成的任務集,并交給TaskScheduler來進行進一步的任務調度。而TaskScheduler 負責對每個具體的Task進行調度。
具體調度算法有FIFO,FAIR:
- FIFO調度:先進先出,這是Spark默認的調度模式。
- FAIR調度:支持將作業分組到池中,并為每個池設置不同的調度權重,任務可以按照權重來決定執行順序。
2. spark sql
spark sql提供了基于sql的數據處理方法,使得分布式的數據集處理變的更加簡單,這也是spark 廣泛使用的重要原因。
目前大數據相關計算引擎一個重要的評價指標就是:是否支持sql,這樣才會降低使用者的門檻。spark sql提供了兩種抽象的數據集合DataFrame和DataSet。
DataFrame 是spark Sql 對結構化數據的抽象,可以簡單的理解為spark中的表,相比較于RDD多了數據的表結構信息(schema).DataFrame = Data + schema
RDD是分布式對象集合,DataFrame是分布式Row的集合,提供了比RDD更豐富的算子,同時提升了數據的執行效率。
DataSet 是數據的分布式集合 ,它具有RDD強類型的優點 和Spark SQL優化后執行的優點。DataSet可以由jvm對象構建,然后使用map,filter,flatmap等操作函數操作。
3. spark streaming
這個模塊主要是對流數據的處理,支持流數據的可伸縮和容錯處理,可以與Flume和Kafka等已建立的數據源集成。Spark Streaming的實現,也使用RDD抽象的概念,使得在為流數據編寫應用程序時更為方便。
4. spark特點
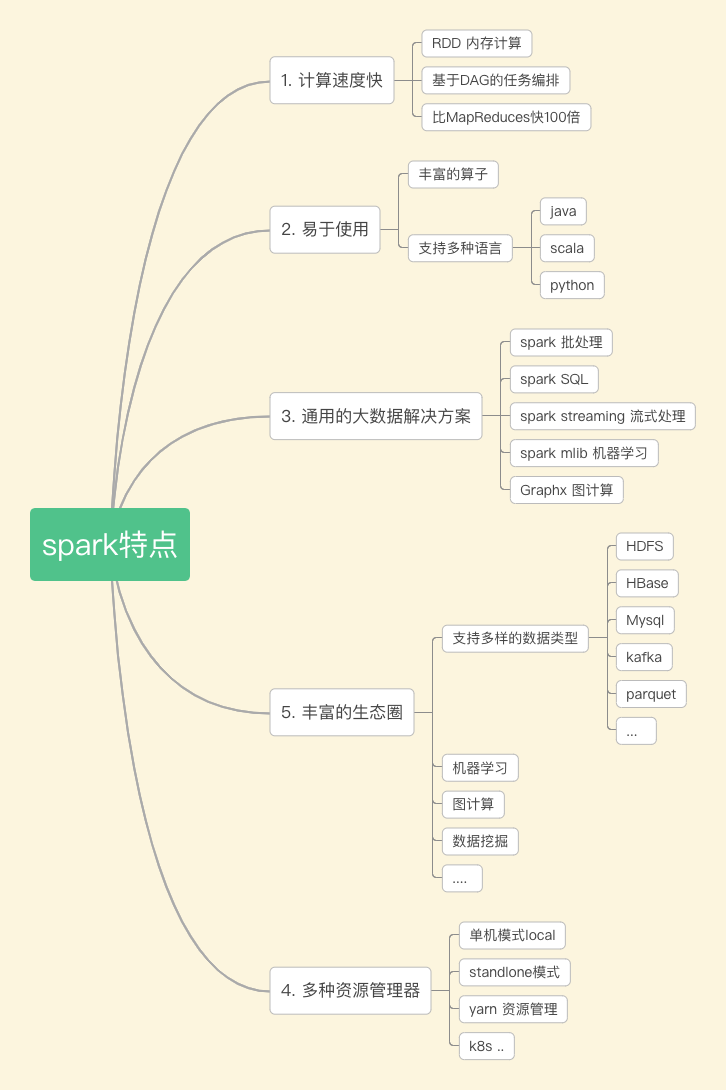
(1)spark 計算速度快
spark將每個任務構建成DAG進行計算,內部的計算過程通過彈性式分布式數據集RDD在內存在進行計算,相比于hadoop的mapreduce效率提升了100倍。
(2)易于使用
spark 提供了大量的算子,開發只需調用相關api進行實現無法關注底層的實現原理。
通用的大數據解決方案
相較于以前離線任務采用mapreduce實現,實時任務采用storm實現,目前這些都可以通過spark來實現,降低來開發的成本。同時spark 通過spark SQL降低了用戶的學習使用門檻,還提供了機器學習,圖計算引擎等。
(3)支持多種的資源管理模式
學習使用中可以采用local 模型進行任務的調試,在正式環境中又提供了standalone,yarn等模式,方便用戶選擇合適的資源管理模式進行適配。
(4)社區支持
spark 生態圈豐富,迭代更新快,成為大數據領域必備的計算引擎。
三、spark 運行模式及集群角色
1. spark運行模式

2. spark集群角色
下圖是spark的集群角色圖,主要有集群管理節點cluster manager,工作節點worker,執行器executor,驅動器driver和應用程序application 五部分組成,下面詳細說明每部分的特點。
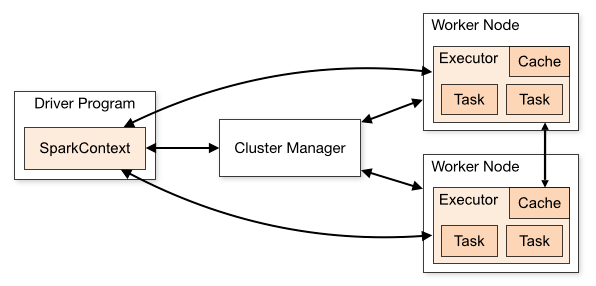
(1)Cluster Manager
集群管理器,它存在于Master進程中,主要用來對應用程序申請的資源進行管理,根據其部署模式的不同,可以分為local,standalone,yarn,mesos等模式。
(2)worker
worker是spark的工作節點,用于執行任務的提交,主要工作職責有下面四點:
- worker節點通過注冊機向cluster manager匯報自身的cpu,內存等信息。
- worker 節點在spark master作用下創建并啟用executor,executor是真正的計算單元。
- spark master將任務Task分配給worker節點上的executor并執行運用。
- worker節點同步資源信息和executor狀態信息給cluster manager。
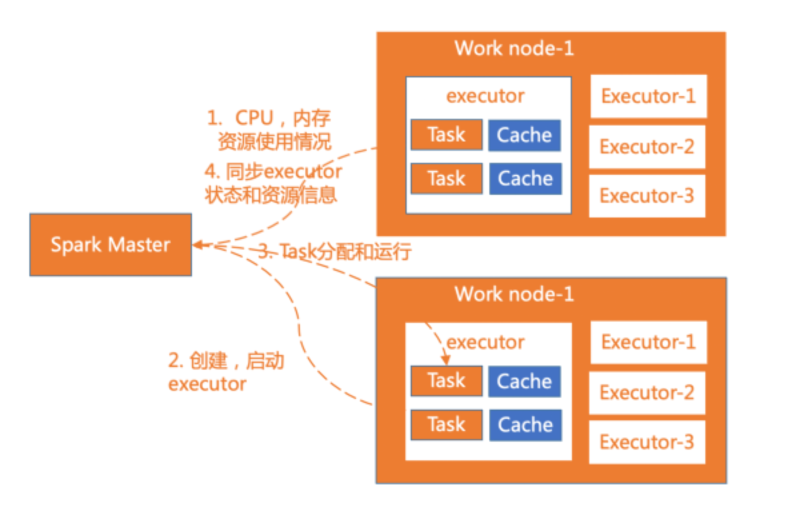
在yarn 模式下運行worker節點一般指的是NodeManager節點,standalone模式下運行一般指的是slave節點。
(3)executor
executor 是真正執行計算任務的組件,它是application運行在worker上的一個進程。這個進程負責Task的運行,它能夠將數據保存在內存或磁盤存儲中,也能夠將結果數據返回給Driver。
(4)Application
application是Spark API 編程的應用程序,它包括實現Driver功能的代碼和在程序中各個executor上要執行的代碼,一個application由多個job組成。其中應用程序的入口為用戶所定義的main方法。
(5)Driver
驅動器節點,它是一個運行Application中main函數并創建SparkContext的進程。application通過Driver 和Cluster Manager及executor進行通訊。它可以運行在application節點上,也可以由application提交給Cluster Manager,再由Cluster Manager安排worker進行運行。
Driver節點也負責提交Job,并將Job轉化為Task,在各個Executor進程間協調Task的調度。
(6)sparkContext
sparkContext是整個spark應用程序最關鍵的一個對象,是Spark所有功能的主要入口點。核心作用是初始化spark應用程序所需要的組件,同時還負責向master程序進行注冊等。
3. spark其它核心概念
(1)RDD
它是Spark中最重要的一個概念,是彈性分布式數據集,是一種容錯的、可以被并行操作的元素集合,是Spark對所有數據處理的一種基本抽象。可以通過一系列的算子對rdd進行操作,主要分為Transformation和Action兩種操作。
- Transformation(轉換):是對已有的RDD進行換行生成新的RDD,對于轉換過程采用惰性計算機制,不會立即計算出結果。常用的方法有map,filter,flatmap等。
- Action(執行):對已有對RDD對數據執行計算產生結果,并將結果返回Driver或者寫入到外部存儲中。常用到方法有reduce,collect,saveAsTextFile等。
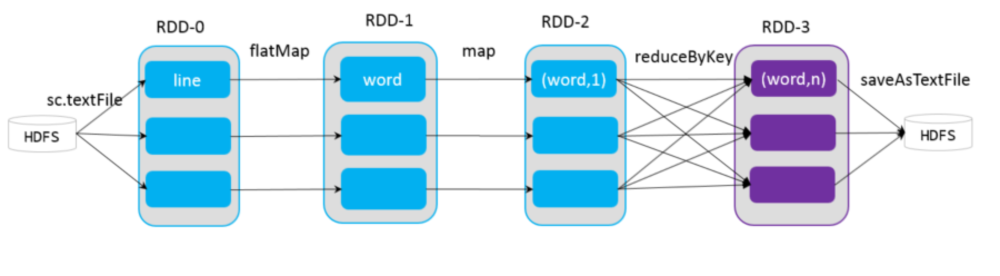
(2)DAG
DAG是一個有向無環圖,在Spark中, 使用 DAG 來描述我們的計算邏輯。主要分為DAG Scheduler 和Task Scheduler。
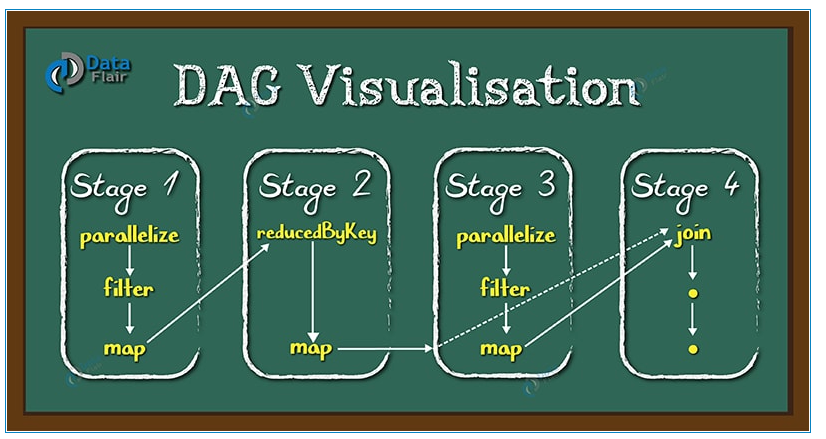
圖片出自:https://blog.csdn.net/newchitu/article/details/92796302
(3)DAG Scheduler
DAG Scheduler 是面向stage的高層級的調度器,DAG Scheduler把DAG拆分為多個Task,每組Task都是一個stage,解析時是以shuffle為邊界進行反向構建的,每當遇見一個shuffle,spark就會產生一個新的stage,接著以TaskSet的形式提交給底層的調度器(task scheduler),每個stage封裝成一個TaskSet。DAG Scheduler需要記錄RDD被存入磁盤物化等動作,同時會需要Task尋找最優等調度邏輯,以及監控因shuffle跨節點輸出導致的失敗。
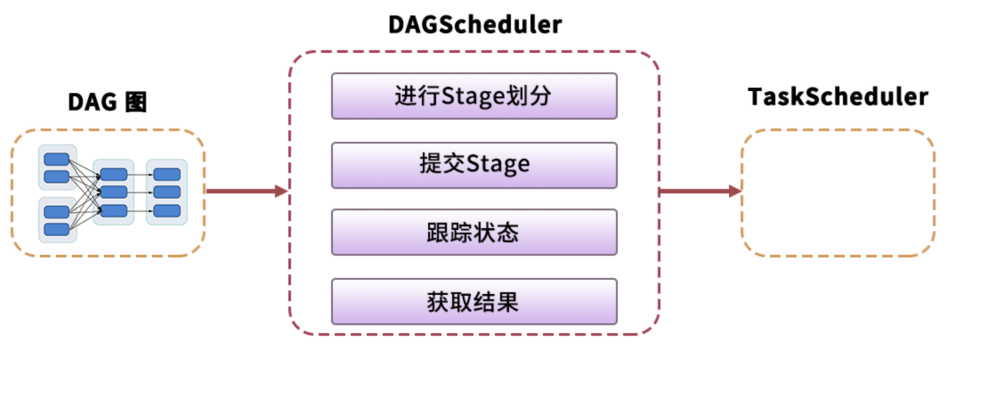
(4)Task Scheduler
Task Scheduler 負責每一個具體任務的執行。它的主要職責包括
- 任務集的調度管理;
- 狀態結果跟蹤;
- 物理資源調度管理;
- 任務執行;
- 獲取結果。
(5)Job
job是有多個stage構建的并行的計算任務,job是由spark的action操作來觸發的,在spark中一個job包含多個RDD以及作用在RDD的各種操作算子。
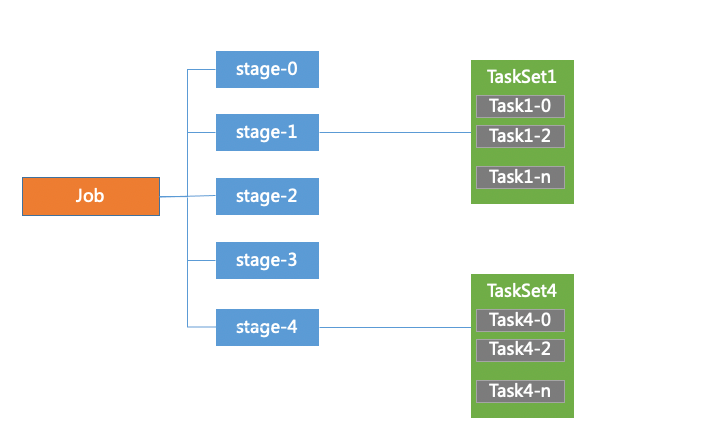
(6)stage
DAG Scheduler會把DAG切割成多個相互依賴的Stage,劃分Stage的一個依據是RDD間的寬窄依賴。
在對Job中的所有操作劃分Stage時,一般會按照倒序進行,即從Action開始,遇到窄依賴操作,則劃分到同一個執行階段,遇到寬依賴操作,則劃分一個新的執行階段,且新的階段為之前階段的parent,然后依次類推遞歸執行。
child Stage需要等待所有的parent Stage執行完之后才可以執行,這時Stage之間根據依賴關系構成了一個大粒度的DAG。在一個Stage內,所有的操作以串行的Pipeline的方式,由一組Task完成計算。
(7)TaskSet Task
TaskSet 可以理解為一種任務,對應一個stage,是Task組成的任務集。一個TaskSet中的所有Task沒有shuffle依賴可以并行計算。
Task是spark中最獨立的計算單元,由Driver Manager發送到executer執行,通常情況一個task處理spark RDD一個partition。Task分為ShuffleMapTask和ResultTask兩種,位于最后一個Stage的Task為ResultTask,其他階段的屬于ShuffleMapTask。
四、spark作業運行流程
1. spark作業運行流程
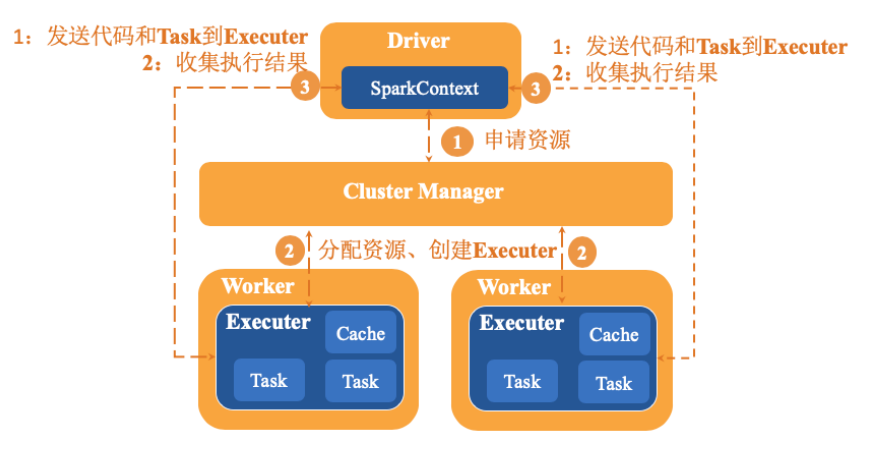
spark應用程序以進程集合為單位在分布式集群上運行,通過driver程序的main方法創建sparkContext的對象與集群進行交互。具體運行流程如下:
- sparkContext向cluster Manager申請CPU,內存等計算資源。
- cluster Manager分配應用程序執行所需要的資源,在worker節點創建executor。
- sparkContext將程序代碼和task任務發送到executor上進行執行,代碼可以是編譯成的jar包或者python文件等。接著sparkContext會收集結果到Driver端。
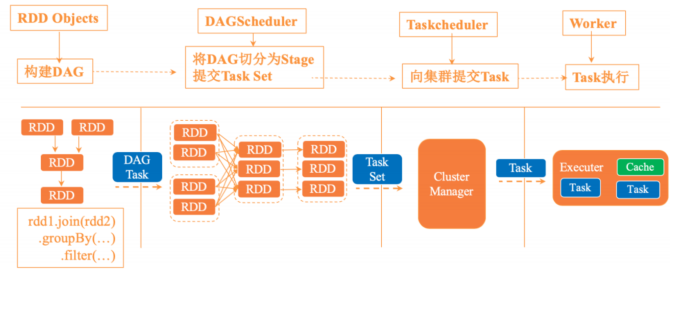
2. spark RDD迭代過程
- sparkContext創建RDD對象,計算RDD間的依賴關系,并組成一個DAG有向無環圖。
- DAGScheduler將DAG劃分為多個stage,并將stage對應的TaskSet提交到集群的管理中心,stage的劃分依據是RDD中的寬窄依賴,spark遇見寬依賴就會劃分為一個stage,每個stage中包含來一個或多個task任務,避免多個stage之間消息傳遞產生的系統開銷。
- taskScheduler 通過集群管理中心為每一個task申請資源并將task提交到worker的節點上進行執行。
- worker上的executor執行具體的任務。
3. yarn資源管理器介紹
spark 程序一般是運行在集群上的,spark on yarn是工作或生產上用的非常多的一種運行模式。
沒有yarn模式前,每個分布式框架都要跑在一個集群上面,比如說Hadoop要跑在一個集群上,Spark用集群的時候跑在standalone上。這樣的話整個集群的資源的利用率低,且管理起來比較麻煩。
yarn是分布式資源管理和任務管理管理,主要由ResourceManager,NodeManager和ApplicationMaster三個模塊組成。
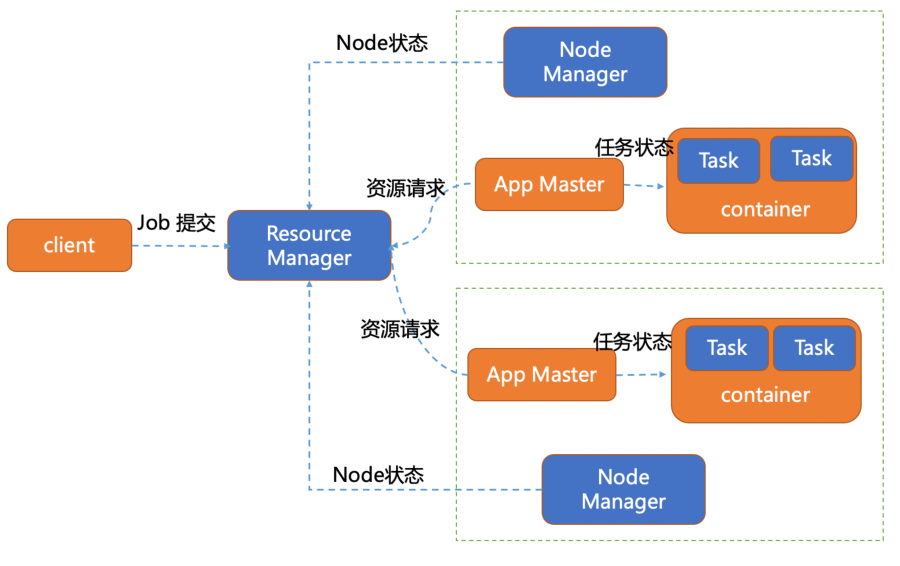
ResourceManager 主要負責集群的資源管理,監控和分配。對于所有的應用它有絕對的控制權和資源管理權限。
NodeManager 負責節點的維護,執行和監控task運行狀況。會通過心跳的方式向ResourceManager匯報自己的資源使用情況。
yarn資源管理器的每個節點都運行著一個NodeManager,是ResourceManager的代理。如果主節點的ResourceManager宕機后,會連接ResourceManager的備用節點。
ApplicationMaster 負責具體應用程序的調度和資源的協調,它會與ResourceManager協商進行資源申請。ResourceManager以container容器的形式將資源分配給application進行運行。同時負責任務的啟停。
container 是資源的抽象,它封裝著每個節點上的資源信息(cpu,內存,磁盤,網絡等),yarn將任務分配到container上運行,同時該任務只能使用container描述的資源,達到各個任務間資源的隔離。
4. spark程序在yarn上執行流程
spark on yarn分為兩種模式yarn-client模式,和yarn—cluster模式,一般線上采用的是yarn-cluster模式。
(1)yarn-client模式
driver在客戶端本地執行,這種模式可以使得spark application和客戶端進行交互,因為driver在客戶端可以通過webUI訪問driver的狀態。同時Driver會與yarn集群中的Executor進行大量的通信,會造成客戶機網卡流量的大量增加。
(2)yarn-cluster模式
Yarn-Cluster主要用于生產環境中,因為Driver運行在Yarn集群中某一臺NodeManager中,每次提交任務的Driver所在的機器都是隨機的,不會產生某一臺機器網卡流量激增的現象,缺點是任務提交后不能看到日志。只能通過yarn查看日志。
下圖是yarn-cluster運行模式:
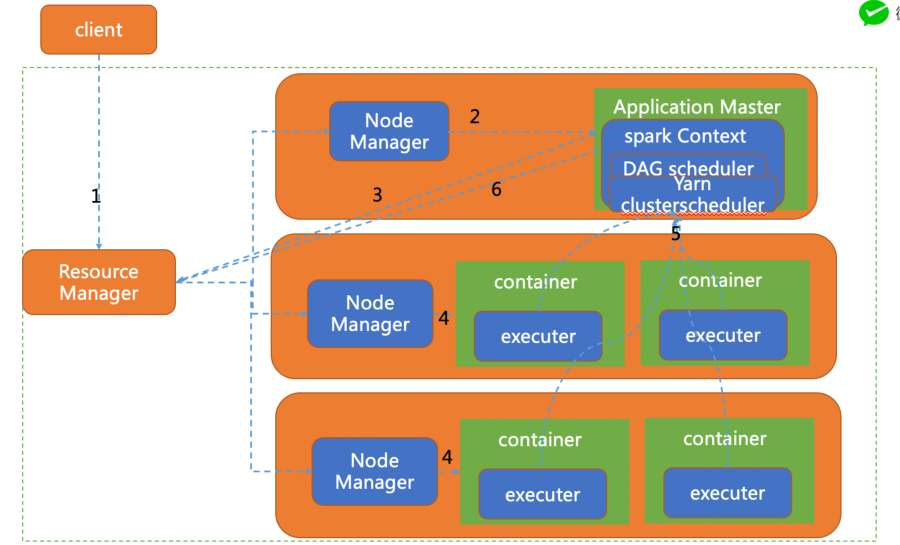
client 向yarn提交應用程序,包含ApplicationMaster程序、啟動ApplicationMaster的命令、需要在Executor中運行的程序等。
ApplicationMaster程序啟動ApplicationMaster的命令、需要在Executor中運行的程序等。
ApplicationMaster向ResourceManager注冊,這樣用戶可以直接通過ResourceManage查看應用程序的運行狀態。
ApplicationMaster申請到資源(也就是Container)后,便與對應的NodeManager通信,啟動Task。
Task向ApplicationMaster匯報運行的狀態和進度,以讓ApplicationMaster隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務。
應用程序運行完成后,ApplicationMaster向ResourceManager申請注銷并關閉自己。