大數據學習:ZooKeeper工作原理
在大數據生態當中,分布式集群當中的一個重要組件,就是Zookeeper,作為集群運行的重要管理者,正如其名字“動物園管理員”所示,負責集群運行的諸多事宜。今天的大數據學習分享,我們就來具體講講,ZooKeeper工作原理。

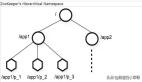
在Zookeeper的工作流程當中,各個節點當中,主要涉及到三個角色和四種狀態,這也是構成Zookeeper體系架構的重要組成部分。
ZooKeeper角色和狀態
角色:Leader,Follower,Observer。
狀態:Leading,Following,Observing,Looking。
Looking:當前Server不知道Leader是誰,正在搜尋。
Leading:當前Server即為選舉出來的Leader。
Following:Leader已經選舉出來,當前Server與之同步。
Observing:Observer的行為在大多數情況下與Follower完全一致,但是他們不參加選舉和投票,而僅僅接受(observing)選舉和投票的結果。
Zookeeper工作流程
Leader Election
當Leader崩潰或者Leader失去大多數的Follower,這時候ZK進入恢復模式,恢復模式需要重新選舉出一個新的Leader,讓所有的Server都恢復到一個正確的狀態。
Zk的選舉算法有兩種:一種是基于Basic paxos實現的,另外一種是基于Fast paxos算法實現的。
系統默認的選舉算法為Fast paxos。
Fast paxos流程是在選舉過程中,某Server首先向所有Server提議自己要成為Leader,當其它Server收到提議以后,解決epoch和zxid的沖突,并接受對方的提議,然后向對方發送接受提議完成的消息,重復這個流程,最后一定能選舉出Leader。
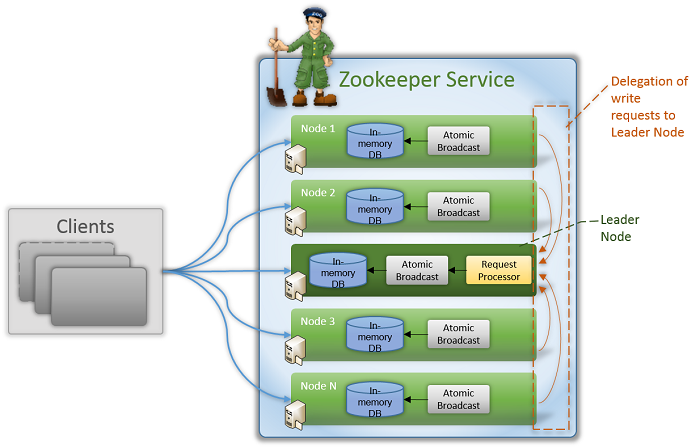
Leader工作流程
Leader主要有三個功能:
恢復數據;
維持與Follower的心跳,接收Follower請求并判斷Follower的請求消息類型;
Follower的消息類型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根據不同的消息類型,進行不同的處理。
Follower主要有四個功能:
向Leader發送請求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
接收Leader消息并進行處理;
接收Client的請求,如果為寫請求,發送給Leader進行投票;
返回Client結果。
Follower的消息循環處理如下幾種來自Leader的消息:
PING消息:心跳消息
PROPOSAL消息:Leader發起的提案,要求Follower投票
COMMIT消息:服務器端最新一次提案的信息
UPTODATE消息:表明同步完成
REVALIDATE消息:根據Leader的REVALIDATE結果,關閉待revalidate的session還是允許其接受消息
SYNC消息:返回SYNC結果到客戶端,這個消息最初由客戶端發起,用來強制得到最新的更新。
Zab協議(ZooKeeper Atomic Broadcast protocol)
Zookeeper的核心是原子廣播,這個機制保證了各個Server之間的同步。Zab協議有兩種模式,它們分別是恢復模式(Recovery選主)和廣播模式(Broadcast同步)。
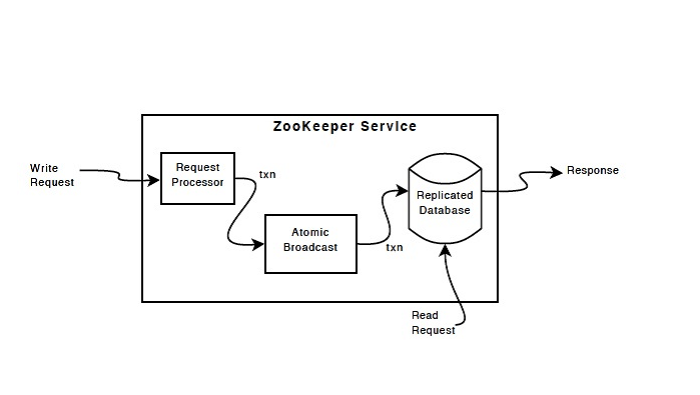
當服務啟動或者在領導者崩潰后,Zab就進入了恢復模式,當領導者被選舉出來,且大多數Server完成了和Leader的狀態同步以后,恢復模式就結束了。狀態同步保證了Leader和Server具有相同的系統狀態。
為了保證事務的順序一致性,zookeeper采用了遞增的事務id號(zxid)來標識事務。所有的提議(proposal)都在被提出的時候加上了zxid。
實現中zxid是一個64位的數字,它高32位是epoch用來標識Leader關系是否改變,每次一個Leader被選出來,它都會有一個新的epoch,標識當前屬于那個Leader的統治時期。低32位用于遞增計數。