













圖文詳解:Kafka到底有哪些秘密讓我對它情有獨鐘呢?
前言
好了,開始進入正題。今天給大家帶來的的是關于我們的老朋友Kafka的來世今生。
隨著對實時性的要求越來越高,那么在龐大的數據的傳輸過程中怎么能保證數據的快速傳遞呢,由此,消息隊列產生了。
“消息”是在兩臺計算機間傳送的數據單位。消息可以非常簡單,例如只包含文本字符串;也可以更復雜,可能包含嵌入對象。
消息被發送到隊列中。“消息隊列”是在消息的傳輸過程中保存消息的容器。Kafka是一個分布式消息隊列對我們來說掌握它是必不可少的。
本文對 Kafka 的基本組件的實現細節及其基本應用進行了詳細介紹,同時,也熬了幾天夜畫了圖解,希望能讓大家對 Kafka 核心知識的有了更深刻的理解,最后也總結了 Kafka 在實際業務中的應用。跟著小羽一起再來熟悉一下這些屬于Kafka的小秘密吧:
Kafka 概念
Kafka 是一種高吞吐量、分布式、基于發布/訂閱的消息系統,最初由 LinkedIn 公司開發,使用Scala 語言編寫,目前是 Apache 的開源項目。
Kafka 主要組件
- broker:Kafka 服務器,負責消息存儲和轉發
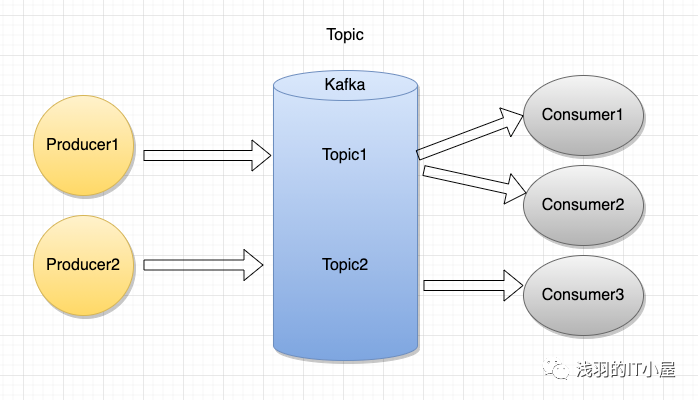
- topic:消息類別,Kafka 按照 topic 來分類消息
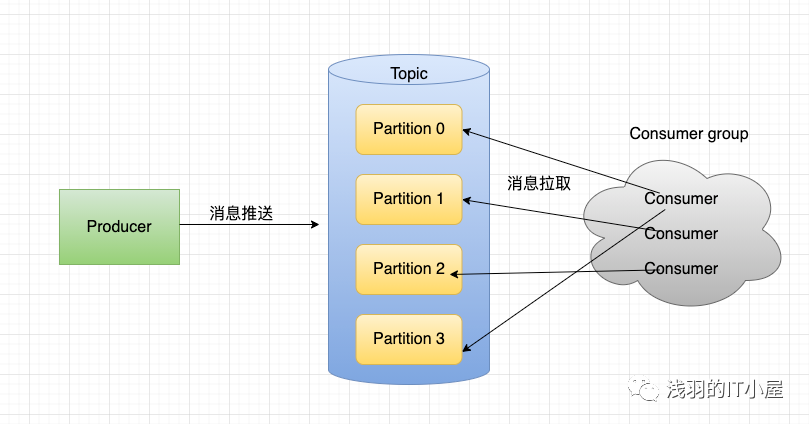
partition:topic 的分區,一個 topic 可以包含多個 partition,topic 消息保存在各個 partition 上
offset:消息在日志中的位置,可以理解是消息在 partition 上的偏移量,也是代表該消息的唯一序號
- Producer:消息生產者
- Consumer:消息消費者
- Consumer Group:消費者分組,每個 Consumer 必須屬于一個 group
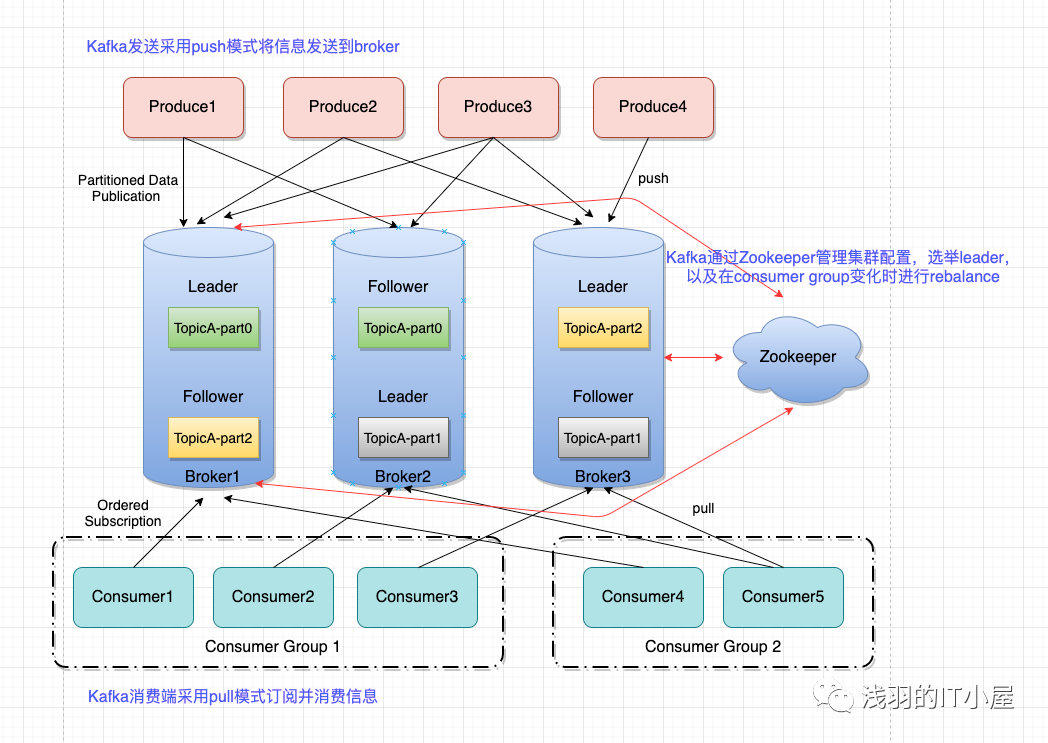
- Zookeeper:保存著集群 broker、topic、partition 等 meta 數據;另外,還負責 broker 故障發現,partition leader 選舉,負載均衡等功能
Kafka 優點
- 解耦:消息系統在處理過程中間插入了一個隱含的、基于數據的接口層,兩邊的處理過程都要實現這一接口。這允許你獨立的擴展或修改兩邊的處理過程,只要確保它們遵守同樣的接口約束。
- 冗余:消息隊列把數據進行持久化直到它們已經被完全處理,通過這一方式規避了數據丟失風險。許多消息隊列所采用的"插入-獲取-刪除"范式中,在把一個消息從隊列中刪除之前,需要你的處理系統明確的指出該消息已經被處理完畢,從而確保你的數據被安全的保存直到你使用完畢。
- 擴展性:因為消息隊列解耦了你的處理過程,所以增大消息入隊和處理的頻率是很容易的,只要另外增加處理過程即可。不需要改變代碼、不需要調節參數。擴展就像調大電力按鈕一樣簡單。
- 靈活性 & 峰值處理能力:使用消息隊列能夠使關鍵組件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。
- 可恢復性:消息隊列降低了進程間的耦合度,所以即使一個處理消息的進程掛掉,加入隊列中的消息仍然可以在系統恢復后被處理。
- 順序保證:大部分消息隊列本來就是排序的,并且能保證數據會按照特定的順序來處理。Kafka保證一個Partition內的消息的有序性。
- 緩沖:消息隊列通過一個緩沖層來幫助任務最高效率的執行。寫入隊列的處理會盡可能的快速。該緩沖有助于控制和優化數據流經過系統的速度。
- 異步通信:消息隊列提供了異步處理機制,允許用戶把一個消息放入隊列,但并不立即處理它。想向隊列中放入多少消息就放多少,然后在需要的時候再去處理它們。
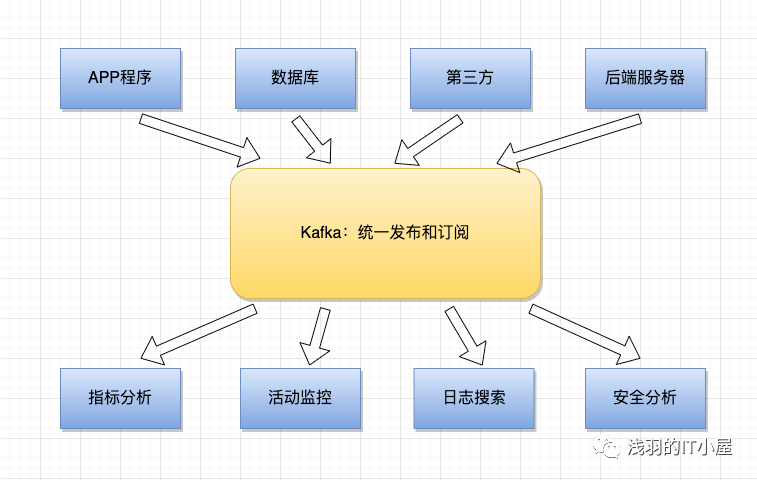
Kafka 應用場景
- 活動追蹤:跟蹤網站?用戶與前端應?用程序發?生的交互,如:網站PV/UV分析
- 傳遞消息:系統間異步的信息交互,如:營銷活動(注冊后發送券碼福利利)
- 日志收集:收集系統及應?用程序的度量量指標及?日志,如:應用監控和告警
- 提交日志:將數據庫的更更新發布到kafka上,如:交易統計
Kafka 數據存儲設計
partition 的數據文件
partition 中的每條 Message 包含三個屬性:offset,MessageSize,data,其中 offset 表 示 Message 在這個 partition 中的偏移量,offset 不是該 Message 在 partition 數據文件中的實際存儲位置,而是邏輯上一個值,它唯一確定了 partition 中的一條 Message,可以認為 offset 是 partition 中 Message 的 id;MessageSize 表示消息內容 data 的大小;data 為 Message 的具體內容。
數據文件分段 segment
partition 物理上由多個 segment 文件組成,每個 segment 大小相等,順序讀寫。每個 segment數據文件以該段中最小的 offset 命名,文件擴展名為.log。這樣在查找指定 offset 的 Message 的時候,用二分查找就可以定位到該 Message 在哪個 segment 數據文件中。
數據文件索引
Kafka 為每個分段后的數據文件建立了索引文件,文件名與數據文件的名字是一樣的,只是文件擴展名為.index。index 文件中并沒有為數據文件中的每條 Message 建立索引,而是采用了稀疏存儲的方式,每隔一定字節的數據建立一條索引。這樣避免了索引文件占用過多的空間,從而可以將索引文件保留在內存中。

Zookeeper 在 kafka 的作用
無論是 kafka 集群,還是 producer 和 consumer 都依賴于 zookeeper 來保證系統可用性集群保存一些meta信息。
Kafka 使用 zookeeper 作為其分布式協調框架,很好的將消息生產、消息存儲、消息消費的過程結合在一起。
同時借助 zookeeper,kafka 能夠生產者、消費者和 broker 在內的所以組件在無狀態的情況下,建立起生產者和消費者的訂閱關系,并實現生產者與消費者的負載均衡。
生產者設計
負載均衡
由于消息 topic 由多個 partition 組成,且 partition 會均衡分布到不同 broker 上,因此,為了有效利用 broker 集群的性能,提高消息的吞吐量,producer 可以通過隨機或者 hash 等方式,將消息平均發送到多個 partition 上,以實現負載均衡。
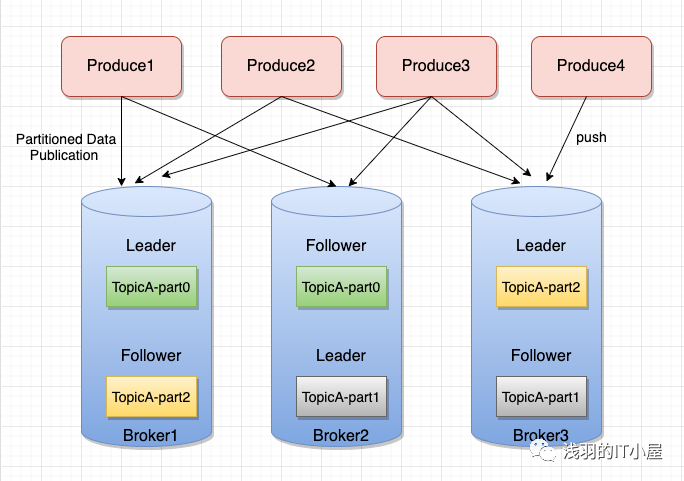
批量發送
是提高消息吞吐量重要的方式,Producer 端可以在內存中合并多條消息后,以一次請求的方式發送了批量的消息給 broker,從而大大減少 broker 存儲消息的 IO 操作次數。但也一定程度上影響了消息的實時性,相當于以時延代價,換取更好的吞吐量。
壓縮
Kafka支持以集合(batch)為單位發送消息,在此基礎上,Kafka還支持對消息集合進行壓縮,Producer 端可以通過 GZIP 或 Snappy 格式對消息集合進行壓縮。Producer 端進行壓縮之后,在Consumer 端需進行解壓。壓縮的好處就是減少傳輸的數據量,減輕對網絡傳輸的壓力,在對大數據處理上,瓶頸往往體現在網絡上而不是 CPU(壓縮和解壓會耗掉部分 CPU 資源)。
那么如何區分消息是壓縮的還是未壓縮的呢,Kafka在消息頭部添加了一個描述壓縮屬性字節,這個字節的后兩位表示消息的壓縮采用的編碼,如果后兩位為0,則表示消息未被壓縮。
消費者設計
Consumer Group
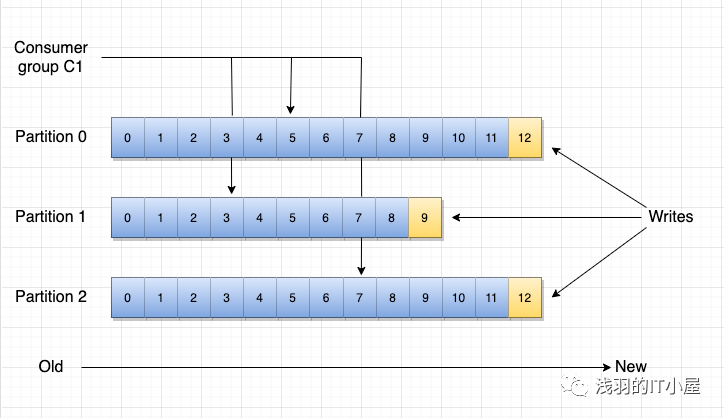
同一 Consumer Group 中的多個 Consumer 實例,不同時消費同一個 partition,等效于隊列模式。partition 內消息是有序的,Consumer 通過 pull 方式消費消息。Kafka 不刪除已消費的消息對于 partition,順序讀寫磁盤數據,以時間復雜度 O(1)方式提供消息持久化能力。
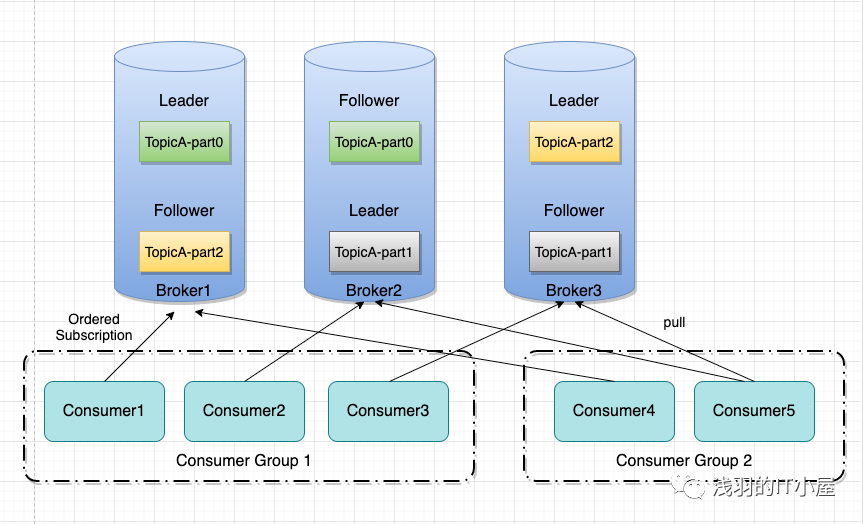
實踐應用
Kafka 作為消息系統
kafka 通過在主題中具有并行性概念 - 分區 - ,Kafka能夠在消費者流程池中提供訂購保證和負載平衡。這是通過將主題中的分區分配給使用者組中的使用者來實現的,以便每個分區僅由該組中的一個使用者使用。通過這樣做,我們確保使用者是該分區的唯一讀者并按順序使用數據。由于有許多分區,這仍然可以平衡許多消費者實例的負載。但請注意,消費者組中的消費者實例不能超過分區。
Kafka 作為存儲系統
Kafka是一個非常好的存儲系統。寫入Kafka的數據將寫入磁盤并進行復制以實現容錯。Kafka允許生產者等待確認,以便在完全復制之前寫入不被認為是完整的,并且即使寫入的服務器失敗也保證寫入仍然存在。
磁盤結構Kafka很好地使用了規模 - 無論服務器上有50 KB還是50 TB的持久數據,Kafka都會執行相同的操作。
由于認真對待存儲并允許客戶端控制其讀取位置,您可以將Kafka視為一種專用于高性能,低延遲提交日志存儲,復制和傳播的專用分布式文件系統。
Kafka 用于流處理
對于復雜的轉換,Kafka提供了完全集成的Streams API。這允許構建執行非平凡處理的應用程序,這些應用程序可以計算流的聚合或將流連接在一起。
此工具有助于解決此類應用程序面臨的難題:處理無序數據,在代碼更改時重新處理輸入,執行有狀態計算等。
流API構建在Kafka提供的核心原理上:它使用生產者和消費者API進行輸入,使用Kafka進行8有狀態存儲,并在流處理器實例之間使用相同的組機制來實現容錯*。


















