













數據科學很性感?不,其實它非常枯燥!
大數據文摘出品
來源:medium
編譯:睡不著的iris
很多人把數據科學(或者機器學習)工作描繪的令人向往,激勵自己和別人加入其行列。大家把數據科學想得非常完美,事實上它容易讓人感到“枯燥”。一旦感到枯燥,你就容易焦慮。如此,導致數據科學工作的離職率非常高。
本文作者將告訴大家自己如何應對“數據科學中那些枯燥的工作”。
希望能夠對你有所幫助,讓你對數據科學有一個正確的認識,讓你在決定走上數據科學的征途時,好好享受這場漫長的游戲!
第一課
我的表弟Shawn是個年輕英俊的小伙,最近他來了加拿大攻讀計算機碩士學位。和很多學生一樣,Shawn對機器學習充滿熱情。他希望過2年畢業的時候,可以成為一名數據科學家,或從事其他與機器學習有關的工作。
身為Shawn的表哥,我也關心Shawn是否成功,我決定以自己數據科學生涯的教訓,給他提供最謹慎的建議。《哈佛商業評論》雜志將數據科學稱為“21世紀最性感的工作”,但它和其他職業一樣會讓人覺得枯燥,甚至使人心力交瘁,你還會屢屢受挫。
即便這些話會讓Shawn感到失望,我還是有義務把事實告訴他。希望他對自己選擇的職業道路有充分的了解。更重要的是,我不希望凌晨3點會接到我媽和叔叔的電話,告訴我作為家庭一員,有義務花耐心去好好指導晚輩。
Shawn十分聰明、積極進取且富有好奇心,他讓我詳細地給他說說,數據科學到底多枯燥。因此,我寫了這篇帖子。
一些背景說明
首先,為了便于理解本文,我先介紹下自己是怎么進入數據科學行業(具體可以看我的領英)。作為一名數據科學經理,我不僅負責領導團隊為財富100企業部署機器學習系統,還要管理客戶關系,自己也會承擔一部分的技術工作。
更重要的概率是:機器學習系統應是用于解決特定業務領域問題的一整套方案,除去機器學習組件,還要處理其他與人或系統相關事情。
部署系統意味著解決方案對實際業務運營有效。舉例來說,搭建實驗環境用于訓練和驗證機器學習模型稱不上是部署,但如果搭建一個每月郵件發送產品服務的推薦引擎可以算是部署。相比較構建一個好的機器學習模型,部署機器學習系統需要攻克更多的難題。若是感興趣,可以點擊此處詳細了解。
所以,我不會介紹如何在谷歌或其他高科技公司,從一名初級開發人員成長為技術經理。雖然這些公司在機器學習頗有成就,但他們只能代表“前1%”的公司。因為其他財富100企業在技術成熟度、技術采用的速度以及投資工具和工程人才儲備方面都相對滯后。
AI學術讓我們仔細看看
不少年輕數據科學家花費很多時間思考如何構建完美的機器學習模型,或者采用豐富多彩的視化手段向大家展示具有突破性的商業洞察。當然,這些確實算一部分工作。
然而,隨著數據科學被廣泛使用,企業更關注其實際的應用價值。企業想要部署越來越多的機器學習系統,但他們不關注系統使用了多少新的模型或者酷炫的儀表板。因此,數據科學家需要處理一堆與機器學習無關的工作,從此工作就變得枯燥起來。
數據科學有多枯燥?看看我周一到周五做點什么就知道了。接下來,我把日常工作進行分類闡述,從期望和現實兩方面對比說明,并分享我的應對策略。
下面列舉的案例都源自過往實驗和團隊項目,我將以“我們”的口吻來敘述。雖然這些案例可能并不詳盡,但也足以論證我的觀點。
設計(占5-10%時間)
在設計階段,我們發揮各自最“高”智慧來解決問題和提出卓越的想法。這些想法可以包括新的模型體系結構、數據特性和系統設計等。但很快,我們就陷入低谷,受時間因素或受其他重要事情影響,我們只能采用最簡單(通常也是最無聊)的解決方案。
期望:
我們的想法將被收錄于著名的機器學習雜志,如NIPS、谷歌AI項目(Google AI Research)等,還幻想贏得下一屆諾貝爾獎。
現實:
部署后一切正常運行。不錯的白板繪圖會拍照記錄下來,作為參考框架。
應對策略:
- 不斷與外行朋友談論我們瘋狂的想法,他們會十分誠實(甚至是粗魯)地勸我打消那些瘋狂、愚蠢的念頭;
- 把看似瘋狂的好想法作為附帶項目;
- 結果發現,大部分瘋狂的想法不起作用,或者只是比簡單方法稍微好一點點。
所以,遵循簡單原則(KISS,Keep-It-Simple-Stupid),讓我如釋重負。
編程(占20-70%時間,取決于你的開發角色)
此處不必多講,想象你戴上耳機,喝一個口咖啡,拉伸你的手指,坐在在電腦屏幕前,敲打出一行行漂亮的代碼后,坐等奇跡發生。
我們的代碼分為5部分(此處用代碼行數占比說明):數據管道(50-70%),系統和集成(10-20%),機器學習模型(5-10%),調試和演示支持(5-10%)。其他同行基本也是這么認為的,這里有一幅大圖可以說明此:
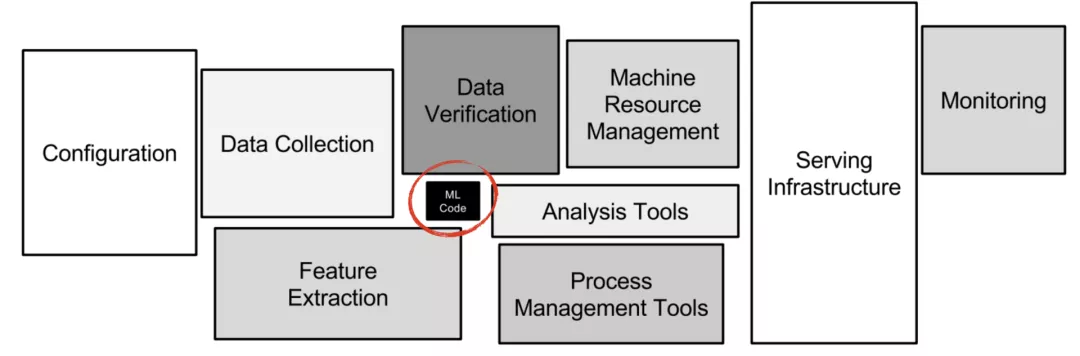
編寫模型的代碼占比(圖),此處有一篇來自谷歌團隊論述機器學習的隱性技術債的文章。
如你所見,我們大部分時間在處理與機器學習無關的事務。雖然機器學習組件非常重要,流行框架和編程語言(如Keras、XGBoost、Python的sklearn等)已經幫助我們減輕了許多繁雜的工作。為了達到目的,我們不需要很重的代碼庫,工作流已經是標準化和相對完善。雖說做底層優化不同,但其影響也就1%。
期望:大部分時間我們在開發和重塑機器學習組件,其他人關注剩余部分。
現實:沒人愿意
- 做自己不想做的事情;
- 把所有事都留給自己做;還有
- 花費大量不成比例的時間去優化已經足夠完善的工作流程。
應對策略:
我們依據各自的專業特長做設計決策,除了完成自己的開發工作,同時還會支持其他人。(例如,貢獻想法、親手寫代碼或者做質量評估)。我們互相學習,從而提升團隊水平。更重要的是,如此可以緩解這份“性感工作”所帶來的焦慮。
質量評估、調試和修復問題(起碼占65%時間)
在我看來,這所有技術工作里最沒勁、最痛苦的部分。部署機器學習系統也不例外。
一個機器學習系統有2類常見的bug:不好的結果和常見軟件問題。不好的結果可能是模型得分太低(例如:準確性和精準度)或難以解釋的預測結果(例如:基于業務經驗的預測概率呈現偏態分布)。代碼沒有問題,只是結果不具有解釋性或者不夠好。常見軟件問題則是諸如代碼無法運行,系統配置等。
期望:
我們用更聰明的方法構建一個優化的模型就可以解決結果不佳的問題。這個過程需要一些智慧,如果想法可以湊效,那還是非常令人欣慰的。
現實:在質量評估、調試和處理缺陷的過程中,我們有近70-90%時間在處理常見軟件問題。通常,我們構建端到端的訓練和驗證管道后,可以很快得到好結果。然而,實際我們更關注系統問題,模型則次之。
應對策略:我用GitHub的issue功能建立了一個游戲化的“獎杯板”。每次關閉問題卡片的時候,我都非常興奮。看到我們“征服”的問題,我會感到十分驕傲。當然,如果我點擊“啟動”一切都能夠奇跡般的正常運行,我會更加驕傲。雖然這一幕只在大學提交編程作業的時候出現過。我一生都記得那一刻的感覺。如果現實生活中再次發生,那可能是什么東西出錯了。
GitHub問題板截圖
救火(占10-50%時間)
再周全的時間計劃,總會發生一些讓你偏離正軌的意外。不僅是數據科學,對于任何交付團隊經理來說,這就是一場噩夢。具體來說,意外可以分為3類:
- 外部因素,如范圍變更、上游系統依賴和客戶抱怨;
- 內部團隊問題,如惱人的bug需要更多的時間解決、團隊成員離職但沒有做好交接、人力不足、個人沖突等;
- 以及自己的無知,包含一切五花八門的“其他”事情。
期望:
從頭到尾巡檢一遍,搞定后,迎接客戶、領導、團隊的擊掌慶祝和擁抱。
現實:
意料之外的事情總是在最不合時宜的時候發生。意外會有一些規律可循,但沒有解決問題的萬能良方,這讓人太心煩了。
應對策略:
- 遇到高技術問題或跨團隊協作,最好將時間周期延長至2到2.5倍,預留足夠的空間;
- 在團隊內部設立激進的里程碑;
- 在心里大罵來平衡情緒,時兒也口頭說說發泄;
- 深呼吸、保持微笑、學會傾聽;
- 和團隊一起探索所有可能的方案,依據可行性、所需投入、難易程度確定方案優先級;
- 都不能起作用,不要再等待了,尋找幫助!
- 繼續推進。以上都不能算是策略,但是在實踐過程中可以發揮作用。
總結
本文都在論述真實世界中,從事數據科學工作會遇到哪些困難。有志于從事機器學習工作的人需要知道除了構建模型,事實上還有很多其他要做的。與其他工作一樣,你最終都會感到枯燥、受挫。當然,這很正常。但更重要的是,你應該建立一套自己的應對策略,那你就可以長期在這個賽道上,享受沿途的小成就,奔向最終的勝利。
相關報道:https://towardsdatascience.com/data-science-is-boring-1d43473e353e
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】














