













7種機器學習算法的7個關鍵點
借助各種庫和框架,我們僅需一行代碼即可實現機器學習算法。有些更進一步,使您可以立即實現和比較多種算法。
易用性具有一些缺點。我們可能會忽略這些算法背后的關鍵概念或想法,而這些概念或想法對于全面了解它們至關重要。
在這篇文章中,我將提到有關7種機器學習算法的7個關鍵點。我想指出的是,這不會完全解釋這些算法,因此,如果您對它們有基本的了解,那就更好了。
開始吧。
1. 支持向量機(SVM)
關鍵點:C參數
SVM創建一個決策邊界,以區分兩個或多個類。
軟裕量支持向量機嘗試解決具有以下目標的優化問題:
- 增加決策邊界與類(或支持向量)的距離
- 最大化在訓練集中正確分類的點數
這兩個目標之間顯然需要權衡取舍。決策邊界可能必須非常接近某一特定類才能正確標記所有數據點。但是,在這種情況下,由于決策邊界對噪聲和自變量的微小變化過于敏感,因此新觀測值的準確性可能會降低。
另一方面,可能會為每個類別設置盡可能大的決策邊界,但要付出一些錯誤分類的例外的代價。這種權衡由c參數控制。
C參數為每個錯誤分類的數據點增加了懲罰。如果c小,則對錯誤分類的點的懲罰較低,因此以較大數量的錯誤分類為代價選擇了具有較大余量的決策邊界。
如果c大,由于高罰分,SVM會嘗試最大程度地減少誤分類示例的數量,從而導致決策邊界的邊距較小。對于所有錯誤分類的示例,懲罰都不相同。它與到決策邊界的距離成正比。
2. 決策樹
關鍵點:信息獲取
選擇要分割的特征時,決策樹算法會嘗試實現:
- 更具預測性
- 雜質少
- 較低的熵
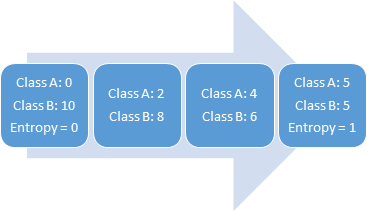
熵是不確定性或隨機性的量度。變量具有的隨機性越多,熵就越高。具有均勻分布的變量具有最高的熵。例如,擲骰子有6個概率相等的可能結果,因此它具有均勻的分布和較高的熵。
> Entropy vs Randomness
選擇導致更多純節點的拆分。所有這些都表明"信息增益",基本上是分裂前后的熵之差。
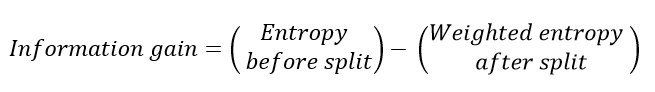
3. 隨機森林
關鍵點:自舉和功能隨機性
隨機森林是許多決策樹的集合。隨機森林的成功很大程度上取決于使用不相關的決策樹。如果我們使用相同或非常相似的樹,則總體結果將與單個決策樹的結果相差無幾。隨機森林通過自舉和特征隨機性來實現具有不相關的決策樹。
自舉是從訓練數據中隨機選擇樣本進行替換。它們稱為引導程序樣本。
通過為隨機森林中的每個決策樹隨機選擇特征來實現特征隨機性。可以通過max_features參數控制用于隨機森林中每棵樹的特征數量。

> Feature randomness
4. 梯度提升決策樹
關鍵點:學習率和n_estimators
GBDT是決策樹與boosting方法的結合體,意味著決策樹是順序連接的。
學習率和n_estimator是用于梯度提升決策樹的兩個關鍵超參數。
學習率僅表示模型學習的速度。學習速度較慢的優點是模型變得更健壯和更通用。但是,學習緩慢需要付出一定的代價。訓練模型需要更多時間,這將我們帶到另一個重要的超參數。
n_estimator參數是模型中使用的樹數。如果學習率低,我們需要更多的樹來訓練模型。但是,我們在選擇樹數時需要非常小心。使用過多樹木會產生過度擬合的高風險。
5. 樸素貝葉斯分類器
關鍵點:樸素假設有什么好處?
樸素貝葉斯(Naive Bayes)是一種用于分類的監督式機器學習算法,因此任務是在給定要素值的情況下找到觀測的類別。樸素貝葉斯分類器在給定一組特征值(即p(yi | x1,x2,…,xn))的情況下計算類的概率。
樸素貝葉斯假設要素彼此獨立,要素之間沒有關聯。但是,現實生活中并非如此。特征不相關的這種天真假設是將該算法稱為"天真"的原因。
與復雜算法相比,所有功能都是獨立的這一假設使其變得非常快。在某些情況下,速度比精度更高。
它適用于高維數據,例如文本分類,電子郵件垃圾郵件檢測。
6. K最近鄰居
關鍵點:何時使用和不使用
K近鄰(kNN)是一種受監督的機器學習算法,可用于解決分類和回歸任務。kNN的主要原理是,數據點的值由其周圍的數據點確定。
隨著數據點數量的增加,kNN算法變得非常慢,因為模型需要存儲所有數據點以便計算它們之間的距離。這個原因也使該算法的存儲效率不高。
另一個缺點是kNN對異常值敏感,因為異常值會影響最近的點(即使距離太遠)。
在積極方面:
- 簡單易懂
- 不做任何假設,因此可以在非線性任務中實施。
- 在多個類別的分類上效果很好
- 適用于分類和回歸任務
7. K-Means聚類
關鍵點:何時使用和不使用
K-均值聚類旨在將數據劃分為k個聚類,以使同一聚類中的數據點相似,而不同聚類中的數據點相距更遠。
K-均值算法無法猜測數據中存在多少個簇。群集的數量必須預先確定,這可能是一項艱巨的任務。
該算法隨著樣本數量的增加而減慢速度,因為在每個步驟中,它都會訪問所有數據點并計算距離。
K均值只能繪制線性邊界。如果存在將數據中的組分開的非線性結構,則k均值將不是一個很好的選擇。
在積極方面:
- 容易解釋
- 比較快
- 可擴展用于大型數據集
- 能夠以智能方式選擇初始質心的位置,從而加快收斂速度
- 保證融合
我們已經介紹了有關每種算法的一些關鍵概念。給出的要點和注釋絕對不是算法的完整說明。但是,了解實現這些算法時必須有所作為當然很重要。











