數據太多而無法使用?快試試這個Kaggle大數據集高效訪問教程
大規模數據集
對數據科學家和Kaggler來說,數據永遠不嫌多。
我敢肯定,你在解決某些問題時,一定報怨過沒有足夠的數據,但偶爾也會抱怨數據量太多難以處理。本文探討的問題就是對超大規模數據集的處理。
在數據過多的情況下,最常見的解決方案是根據RAM采樣適量數據,但這卻浪費了未使用的數據,甚至可能導致信息缺失問題。針對這些問題,研究人員提出多種不同的非子采樣方法。需要注意的時,某一方法是無法解決所有問題的,因此在不同情況下要根據具體需求選擇恰當的解決方案。
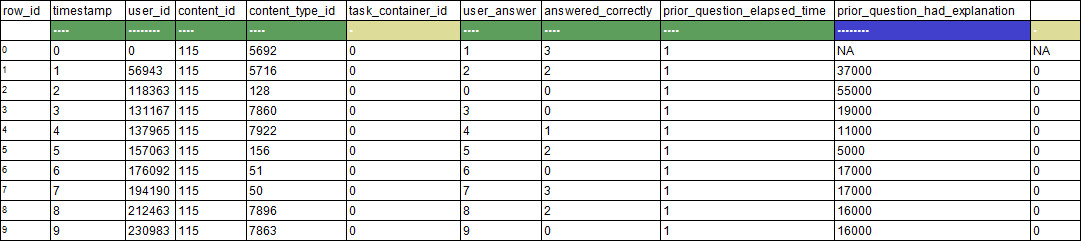
本文將對一些相關技術進行描述和總結。由于Riiid! Answer Correctness Prediction數據集由10列,超1億行的數據組成,在Kaggle Notebook中使用pd.read_csv方法讀取會導致內存不足,因此本文將該數據集做為典型示例。
不同安裝包讀取數據的方式有所不同,Notebook中可用方法包括(默認為Pandas,按字母表排序):
- Pandas
- Dask
- Datatable
- Rapids
除了從csv文件讀取數據外,還可以將數據集轉換為占有更少磁盤空間、更少內存、讀取速度快的其他格式。Notebook可處理的文件類型包括(默認csv,按字母表排序):
- csv
- feather
- hdf5
- jay
- parquet
- pickle
請注意,在實際操作中不單單是讀取數據這么簡單,還要同時考慮數據的下游任務和應用流程,綜合衡量以確定讀取方法。本文對此不做過多介紹,讀者可自行查閱相關資料。
同時,你還會發現,對于不同數據集或不同環境,最有效的方法往往是不同的,也就是所,沒有哪一種方法就是萬能的。
后續會陸續添加新的數據讀取方法。
方法
我們首先使用Notebook默認的pandas方法,如前文所述,這樣的讀取因內存不足失敗。
- import pandas as pd
- import dask.dataframe as dd
- # confirming the default pandas doesn't work (running thebelow code should result in a memory error)
- # data = pd.read_csv("../input/riiid-test-answer-prediction/train.csv")
Pandas介紹
Pandas是最常用的數據集讀取方法,也是Kaggle的默認方法。Pandas功能豐富、使用靈活,可以很好的讀取和處理數據。
使用pandas讀取大型數據集的挑戰之一是其保守性,同時推斷數據集列的數據類型會導致pandas dataframe占用大量非必要內存。因此,在數據讀取時,可以基于先驗知識或樣品檢查預定義列數據的最佳數據類型,避免內存損耗。
RiiiD競賽官方提供的數據集讀取方法就是如此。
幫助文檔: https://pandas.pydata.org/docs/
- %%time
- dtypes = {
- "row_id": "int64",
- "timestamp": "int64",
- "user_id": "int32",
- "content_id": "int16",
- "content_type_id": "boolean",
- "task_container_id": "int16",
- "user_answer": "int8",
- "answered_correctly": "int8",
- "prior_question_elapsed_time": "float32",
- "prior_question_had_explanation": "boolean"}
- data = pd.read_csv("../input/riiid-test-answer-prediction/train.csv", dtype=dtypes)
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 8min 11s, sys: 10.8 s, total: 8min 22s
- Wall time: 8min 22s

Dask介紹
Dask提供并行處理框架對pandas工作流進行擴展,其與Spark具有諸多相似之處。
幫助文檔:https://docs.dask.org/en/latest/
- %%time
- dtypes = {
- "row_id": "int64",
- "timestamp": "int64",
- "user_id": "int32",
- "content_id": "int16",
- "content_type_id": "boolean",
- "task_container_id": "int16",
- "user_answer": "int8",
- "answered_correctly": "int8",
- "prior_question_elapsed_time": "float32",
- "prior_question_had_explanation": "boolean"}
- data = dd.read_csv("../input/riiid-test-answer-prediction/train.csv", dtype=dtypes).compute()
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 9min 24s, sys: 28.8 s, total: 9min 52s
- Wall time: 7min 41s
- data.head()

Datatable介紹
受R語言data.table的啟發,python中提出Datatable,該包可快速讀取大型數據集,一般要比pandas快得多。值得注意的是,該包專門用于處理表格數據集,能夠快速讀取大規模的表格數據集。
幫助文檔:https://datatable.readthedocs.io/en/latest/index.html
- # datatable installation with internet
- # !pip install datatable==0.11.0 > /dev/null
- # datatable installation without internet!
- pip install ../input/python-datatable/datatable-0.11.0-cp37-cp37m-manylinux2010_x86_64.whl > /dev/null
- import datatable as dt
- %%time
- data = dt.fread("../input/riiid-test-answer-prediction/train.csv")
- print("Train size:", data.shape)Train size: (101230332, 10)
- CPU times: user 52.5 s, sys: 18.4 s, total: 1min 10s
- Wall time: 20.5 sdata.head()
Rapids介紹
Rapids提供了在GPU上處理數據的方法。通過將機器學習模型轉移到GPU,Rapids可以在一個或多個GPU上構建端到端的數據解決方案。
幫助文檔:https://docs.rapids.ai/
- # rapids installation (make sure to turn on GPU)
- import sys
- !cp ../input/rapids/rapids.0.15.0 /opt/conda/envs/rapids.tar.gz
- !cd /opt/conda/envs/ && tar -xzvf rapids.tar.gz > /dev/null
- sys.path = ["/opt/conda/envs/rapids/lib/python3.7/site-packages"] + sys.path
- sys.path = ["/opt/conda/envs/rapids/lib/python3.7"] + sys.path
- sys.path = ["/opt/conda/envs/rapids/lib"] + sys.path
- import cudf
- %%time
- data = cudf.read_csv("../input/riiid-test-answer-prediction/train.csv")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 4.58 s, sys: 3.31 s, total: 7.89 s
- Wall time: 30.7 s
- data.head()

文件格式
通常,我們會將數據集存儲為容易讀取、讀取速度快或存儲容量較小的格式。數據集存儲有各種不同的格式,但不是每一種都可以被處理,因此接下來,我們將介紹如何將這些數據集轉換為不同的格式。
- # data = dt.fread("../input/riiid-test-answer-prediction/train.csv").to_pandas()
- # writing dataset as csv
- # data.to_csv("riiid_train.csv", index=False)
- # writing dataset as hdf5
- # data.to_hdf("riiid_train.h5", "riiid_train")
- # writing dataset as feather
- # data.to_feather("riiid_train.feather")
- # writing dataset as parquet
- # data.to_parquet("riiid_train.parquet")
- # writing dataset as pickle
- # data.to_pickle("riiid_train.pkl.gzip")
- # writing dataset as jay
- # dt.Frame(data).to_jay("riiid_train.jay")
數據集的所有格式可從此處獲取,不包括競賽組提供的原始csv數據。
csv格式
大多數Kaggle數據集都提供了csv格式文件。該格式幾乎成為數據集的標準格式,而且所有方法都支持從csv讀取數據。
更多相關信息見: https://en.wikipedia.org/wiki/Comma-separated_values
- %%time
- dtypes = {
- "row_id": "int64",
- "timestamp": "int64",
- "user_id": "int32",
- "content_id": "int16",
- "content_type_id": "boolean",
- "task_container_id": "int16",
- "user_answer": "int8",
- "answered_correctly": "int8",
- "prior_question_elapsed_time": "float32",
- "prior_question_had_explanation": "boolean"}
- data = pd.read_csv("../input/riiid-test-answer-prediction/train.csv", dtype=dtypes)
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 8min 36s, sys: 11.3 s, total: 8min 48s
- Wall time: 8min 49s
feather格式
以feature(二進制)格式存儲數據對于pandas極其友好,該格式提供了更快的讀取速度。
了解更多信息:https://arrow.apache.org/docs/python/feather.html
- %%time
- data = pd.read_feather("../input/riiid-train-data-multiple-formats/riiid_train.feather")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 2.59 s, sys: 8.91 s, total: 11.5 s
- Wall time: 5.19 s
hdf5格式
HDF5是用于存儲、管理和處理大規模數據和復雜數據的高性能數據管理組件。
了解更多信息:https://www.hdfgroup.org/solutions/hdf5
- %%time
- data = pd.read_hdf("../input/riiid-train-data-multiple-formats/riiid_train.h5", "riiid_train")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 8.16 s, sys: 10.7 s, total: 18.9 s
- Wall time: 19.8 s
jay格式
Datatable支持.jay(二進制)格式,其在讀取jay格式數據時速度快得超乎想象。從下面的示例可以看到,該方法讀取整個riiid數據集用時甚至不到1秒!
了解更多信息:https://datatable.readthedocs.io/en/latest/api/frame/to_jay.html
- %%time
- data = dt.fread("../input/riiid-train-data-multiple-formats/riiid_train.jay")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 4.88 ms, sys: 7.35 ms, total: 12.2 ms
- Wall time: 38 ms
parquet格式
在Hadoop生態系統中,parquet是tabular的主要文件格式,同時還支持Spark。經過近年的發展,該數據格式更加成熟,高效易用,pandas目前也支持了該數據格式。
- %%time
- data = pd.read_parquet("../input/riiid-train-data-multiple-formats/riiid_train.parquet")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 29.9 s, sys: 20.5 s, total: 50.4 s
- Wall time: 27.3 s
pickle格式
Python對象可以以pickle格式存儲,pandas內置支持pickle對象的讀取和寫入。
了解更多信息:https://docs.python.org/3/library/pickle.html
- %%time
- data = pd.read_pickle("../input/riiid-train-data-multiple-formats/riiid_train.pkl.gzip")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 5.65 s, sys: 7.08 s, total: 12.7 s
- Wall time: 15 s
不同方法各有千秋
每種方法都有自己的優缺點,例如:
- Pandas在處理大規模數據時對RAM的需求增加
- Dask有時很慢,尤其是在無法并行化的情況下
- Datatable沒有豐富的數據處理功能
- Rapids只適用于GPU
因此,希望讀者掌握不同的方法,并根據實際需求選擇最恰當的方法。我始終相信,研究不是技術驅動的,技術方法只是手段,要有好主意、新想法、改進技術才能推動數據科學的研究與發展。
在經過大量研究后,我確信不同數據集具有不同的適用方法,因此要多嘗試,千萬不要試圖一招半式闖江湖。
在不斷更新的開源軟件包和活躍的社區支持下,數據科學必將持續蓬勃發展。
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。