誰還不懂分布式系統性能調優,請把這篇文章甩給他~
作者簡介:陶輝,畢業于西安交通大學計算機科學與技術專業,目前在杭州智鏈達數據有限公司擔任 CTO 兼聯合創始人,專注于用互聯網技術幫助建筑行業實現轉型升級,曾先后在華為、騰訊、思科、阿里巴巴等公司從事分布式系統下的數據處理工作,騰訊云最有價值專家TVP。對 Linux 下的高性能服務器開發、大規模分布式系統的設計有著豐富經驗。著有《深入理解 Nginx:模塊開發與架構解析》一書。
本次分享分成4塊:
基礎資源優化。不管是X86、ARM,還是 Linux、Windows,不管是腳本語言還是C語言,這種優化都有效的,相對來說收益比較大、比較普惠一些,我把它列為基礎資源優化。
網絡效率優化。這包含三個層面3層,一是系統層,二是應用層,三是傳輸效率的優化。
降低請求時延。怎么用緩存等,我們關注用戶的體驗,能讓單次請求的速度更快一些。
吞吐量。提升系統并發,從吞吐量來說怎么提升系統的并發。
一、基礎資源優化
基礎資源的優化,在我看來核心是提升資源的利用率,資源我們分為四塊:

- CPU 緩存。CPU 的緩存共分為3級,CPU訪問緩存的時延應該在 10 納秒左右,一級緩存可能只有 1 納秒左右。這個時候我們非常關注怎么讓 CPU 緩存命中率提升,它是一個普惠的優化方式。
- 內存。內存有百納秒級別的速度,當你的頻率非常高的時候也不是那么快,所以會有很多的內存池,比如說 C,JVM、Python、Golang、lua 等都有自己的內存池,這些內存池的怎么提升分配速度、減少碎片、提升內存的利用率。
- 磁盤。磁盤有兩類,一類是HDD,機械硬盤的尋址在七八毫秒,它的磁頭旋轉速度是比較慢的,以往的很多軟件技術都在優化這方面,特別是 PageCache 磁盤高速緩存的使用,包括電梯調度算法、零拷貝,或者 Direct IO 等等都是圍繞著機械磁盤來做;另外一類SSD,SSD跟機械硬盤完全是另一種方式,包括編程方式、優化方式都跟傳統的方法不一樣。所以這里簡單總結一下,以 PageCache 作為切入點,包括命中率、IO調度算法。
- 調度。分布式系統中有很多的請求,這些請求如何切換,無論是多進程、多線程,還是協程,怎么樣能讓它的調度性能更高、效率更高,數據的同步更快?

CPU
CPU 緩存的話題比較多,這里舉個例子,我相信各位都用過 Nginx,Nginx 有兩個哈希表,一個是域名哈希表,如果只是用普通的3級域名,可能觸碰不到它的上界,但是如果有4級、5級或者是更多級的域名,可能就會超過64字節,這時你要調大哈希表的 bucket_size。
再舉個例子,Nginx 最強大的地方在于它的變量,任何功能都能夠通過變量實現。變量也是存在哈希表中。當這個變量比較大的時候,一樣也要調整到 64 字節。
那么,為什么是初始的 64 字節?比如想調到 100 字節可不可以,不可以的。要調到 128 字節或者是是 64 字節的整數倍。
為什么會這樣?關于 CPU 緩存,我這里舉一個例子。大概在2005年,CPU 的頻率大概升到 3Ghz~4Ghz 后就不再提升,因為單個 CPU 的發熱量太大,所以只能橫向發展。
多個 CPU 有一個好處就是真正并發。操作系統中的并發是通過時間片切換完成的,微觀上不是真正的并發。而多核 CPU 的并發有一個問題,當兩個 CPU 同時訪問了兩個進程或線程,這兩個數據同時落到了一個 64 字節之內,CPU 的緩存不是一個字節拉的,而是一批拉的,每一批 64 字節。
為了解決這個問題,Java 中有一個常見的詞叫填充法,我剛剛講的 Nginx 也是填充法,用不了這么多字節,但要填這么多,使得微觀上真正并發。因為 CPU 要保證一致性,如果數據沒有一致性就沒有高性能和正確性可言。CPU 的緩存對很多代碼都有影響,并不是只對寫中間件的人有影響,對應用層的開發人員也是有影響的。

內存
關于內存池這一方面,我想起3年前我給華為做的一場內訓。當時有一個同學問我,Nginx 要不要換成谷歌的 TCMalloc?(TCMalloc 是 Google 開發的一個內存池。)
應用程序每次要分配內存,操作系統內核提供系統調用,叫 brk 和 mmap。這些系統調用的效率不高,因為有內核態到用戶態的切換,那么怎么辦?
C程序有一個C庫,Linux 默認叫 Ptmalloc2。 默認分配一個字節會給你預分配 64MB 字節,當你分配第二個字節的時候還從這個池子里面找,釋放后會回到這個內存池。這個池子有很多的問題,比如說 Ptmalloc 非常通用的內存池,考慮的是效率特別高,比如說A線程釋放的,B線程還能直接拿來用,這肯定有一個并發問題,肯定要加鎖,一加鎖性能就不高,像 tcmalloc和 Ptmalloc 默認了這個,什么也不改。
而谷歌的 TCMalloc 分為小內存、中內存和大內存,小于256KB字節的就是小內存,小內存不考慮共享,所以不用加鎖,速度很快;對于中內存和大內存速度反而不如 Ptmalloc。如果我們做服務器的開發,特別是 Nginx 簡單的服務器的開發,如果是做動態服務器,經常會分配幾MB內存,但是對于只有負載均衡、簡單 lua 腳本操作情況下根本不可能分配大內存,所以 TCmalloc 就非常的適合它。
這里我只是介紹了C庫的內存池,其實上面還有很多的內存池,比如說 Nginx 對共享內存中有內存池 slab,這個 slab 在 openresty,是復用的,對于普通的儲存里也有一個內存池,還有連接內存池和請求內存池。
如果是其他的語言,比如說 lua 虛擬機,它有自己的lua,還有自己的內存池。Java 有 JVM 內存池,golang 也有自己的內存池,像 golang 是基于 tcmalloc 改過垃圾回收機制。這是我希望能夠引起大家注意的,主要是靠線下大家學習。
磁盤
磁盤,我想圍繞著 PageCache。PageCache,傳統的機械硬盤,你想讓它并發,它并發不了,它只蒙在那里轉,所以你要通過調度算法,讓它盡量往一個方向轉。讀的話,會考慮 PageCache 不停的緩存命中。
比如說零拷貝,零拷貝是不是一直有效呢?比如做視頻的直播或者 CDN,這個文件很大,再次命中的概率不高,Pagecache 及其有限,如果文件這么大,因為有很多并發的線路正在同時獲取不同的文件,所以命中的概率很低。

如果進到 PageCache 中會怎樣?
- 很難再次命中,PageCache 也給它進行了降低性能。
- 因為 PageCache 是 least used,只要你現在進來一個東西,一定要出去,出去的東西,本來是很有機會被再次訪問到的小塊資源和文件,所以就失去了再次命中的機會,所以才會有直接IO和異步IO,Linux 的作者認為接口設計很糟糕,但是這個東西是很有用的,并不是一點用也沒有。

關于磁盤高速的緩存,還有很多可以分享的。
比如說SDD,SDD在我看來是另外一個物種。平時大家都認為“SDD 比機械硬盤的 IOPS 高,Latency 低,Thoughtput 更高,即總的吞吐量更高”絕對不是簡簡單單這么一點東西。
我舉個例子:第一,SSD有個問題叫寫入放大。
大家都知道 Kafka,Kafka 性能為什么這么好?一個特點就是削峰填谷,它要把數據持久化。既然是寫硬盤性能為什么能這么好?因為它充分利用了磁盤的旋轉速度,消息隊列先天性是時序隊列,一定不停的往一個文件后面追加,所以磁盤利用率非常高,只要放很多塊機械磁盤,性能還可以繼續提升。
如果換了SSD,還有這樣的好處嗎?SSD 本來就是快很多,但再采用這種方式就有問題,因為它有寫入放大問題,什么叫寫入放大?比如說我們本來是寫日志文件,都往后面追加一些字節,但是 SSD 不行,SSD有一個頁面,是它的基本單位,它是按頁面來的。
比如說現在的頁面上已經有了一個字節,現在還想寫第二個字節,它會把整個頁面讀到緩存區中,然后給它加進去,最后再寫到一個新的沒有人寫過的頁面,所以有很大的放大作用。每寫一個字節,可能給我寫了幾K,它最怕的是 inplace 這種原地寫入,那像 Kafka 再采用的方式會有問題。
第二,耗損平衡。
SSD的壽命不好,什么壽命短呢?因為它不能清除,每一個存儲單元清除的次數是有限制的。如果一個硬盤有一個數據特別熱,比如說就是放操作系統的,經常讀寫,讀著就壞了,這個是大家受不了的,其他地方都好。所以搞了一個GC,不停給你移,這邊是熱數據的,這邊是冷數據的,我給你移過去,移過去之后大家就平衡,這塊磁盤就不會那么快壞。
但這個機制就有問題,給應用程序帶來了挑戰。如果應用程序按照傳統的方式去寫,不停大量的寫入操作進去,就會不停觸發機制,當他的GC趕上過米的時候,又變成阻塞了,性能又下去了。
其實 SSD 有很多和 HDD 不一樣的地方,比如說機械硬盤的時候,絕對不會考慮多開幾個線程,讓速度變快,因為硬盤就在那里轉,多開線程最終還是排隊的,但是SSD不一樣,你多開幾個,它就是那么快,因為它先天可以做并發。
比如說 SSD 做隨機讀寫也做得特別好,我們在機械硬盤上盡量減少數據讀寫的,但到SSD就可以讀寫。

再回到高并發,為什么高并發要使用協程,為什么比多線程要快效率要高?在我看來有兩個原因:
1、每一個協程消耗的內存非常低。每一個線程有多高嗎?給你搞了一個堆內存池,你說一個字節搞一個內存池,線程都有棧,棧什么時候會溢出呢?棧到底有多大呢?一般是2MB到8MB,這么大的線程,可以想象有多少的內存?
如果幾十G的內存上并發10000個線程,內存都不夠,其他業務就做不了了。
最大的問題是同時處理一個請求消耗的內存不能多,而協程就能做到。基本上協程幾KB到十幾KB就可以處理一個請求。所以可以輕松通過十幾G的內存并發到幾萬個、十幾萬個請求。
2、切換成本低。在線程上做切換時有一個內核態到用戶態的切換,而且要做大量的拷貝。在協程的話,因為是全棧用戶態,切技能器,或者是不切技能器,直接調度到代碼里面切一下就可以了,所以相對來說成本也是很低的。

最后再總結一下,對于 CPU 這方面,有一個特別有效的工具。有時候說優化性能,要找到瓶頸,越是瓶頸的地方進行優化才最有價值。怎么找瓶頸呢?我推薦火焰圖。你要自己去打點和寫日志很容易遺漏,你不用裝任何的東西,只需要裝一個 Linux perf+FlumeGraph 兩個軟件就可以。
它分了兩種,on CPU 和 off CPU。onCPU 它是以暖色調為主,看消耗了多少個CPU,因為把所有的函數都考慮到;而offCPU是冷色調,看每一個函數要進程或者是線程進入 sleep 的時間有多長?這兩個圖有一個好處,它是一個SVG的矢量圖,所以可以跟各種正則表達式匹配,也可以點擊放大,而且它會把同一個調用棧中的相同函數進行合并,很容易比出來哪一個函數消耗的時間最長。
二、網絡效率優化
網絡效率優化,主要是編解碼和改進傳輸方式。
編解碼有三部分:

- 系統層傳輸效率。系統層主要是TCP協議,它的優化包括三次握手建鏈優化,四次握手關閉優化。主要根據你的網絡環境,丟包率高不高,時延長不長;如果丟包率非常好,重試的次數很多都可以進行調整。還有緩沖區優化,以及擁塞控制。
- 應用層編碼效率。
- 應用層傳輸效率。
應用層的話,主要看 HTTP 協議。

1996年是HTTP1.0,1999年是HTTP1.1,我們現在主要使用的是1.0和1.1,2015年是HTTP2,他們都是跑在TLS和TCP上,為什么呢?因為能夠簡化開發效率。
TCP 實現了有序字節流,TLS 也要基于有序字節流,如果沒有有序字節流,現在也玩不轉。比如在 QUIC 中要重新實現這點。HTTP2,有了有序字節流,很多問題不用考慮,不管文件有多大,只要正常傳輸就好。
這就帶來了一個問題,在一個有序的字節流上,放了一個無序的東西(HTTP 是多并發的,并發肯定是無序的)。無序的東西承載在有序的字節流上,帶來的問題就是隊頭阻塞。它有多個stream,只要出現一個 stream,TCP 就有可能丟包,后面的 stream 都玩不轉了,所以只能通過 UDP 來解決。
UDP 解決以后,出現了一個 QUIC 層,這個 QUIC 層是獨立的一層,把 TCP 層的很多事(丟包、重傳、擁塞控制)都做了,TLS 也需重新寫,把 HTTP2 中的 stream 也封裝也放到了里面。
HTTP3 到底有什么好處呢?1.多路復用;2.連接遷移;3.QPACK編碼;4.丟包重傳。

我舉個例子,比如說抓一個 HTTP3 的包就知道,抓包看完最上面是 UDP Header,UDP Header 就是一個4元組:源IP、目的IP、源端口、目的端口。接下來是 Packet Header,Packet Header 中有一個整數,叫 connection_id,為什么有 connection_id?
以前一個連接是如何定義的呢?四元組(源IP、目的IP、源端口、目的端口),只要四元組改了就需要重連。
在 IOT 時代,各種高速移動的設備會經常切換,比如經常切換的 5G 基站,或是切到一個 WIFI,這時IP地址肯定會發生變化,需要重新建立連接。重建連接的成本太高了,怎么樣不重新建立連接呢?從 Packet Header 中,定義了一個 connection_id 的整數。
只要這個整數不變,這個連接就可以復用,TLS 握手也不用做了。為什么可以這樣做呢?其實很簡單,這些東西是加密到 HTTP3,如果能夠解密的話,安全性是沒有問題的。Packet Header 中,這就叫連接遷移,就是我們說的 Connection Migration,連接遷移,這是 HTTP3 的第一個用處。
HTTP3 的第二個用處多路復用。多路復用是到 QUIC Frame Header,Packet Header中定義了連接是無序的字節流連接,只管你不丟包,要是丟包了,我們有一個ID,能找到重發。
但順序亂了,我是不管的,管順序亂不亂是在 QUIC Frame Header,他做了一個東西,他重新定了叫 QUIC stream 的概念,就像跟 TCP 連接是一樣的,這里做出來一個TCP 連接,跟 TCP 連接用起來是一模一樣的。
大家都知道 TCP 三次握手時在同步 Sequence,SYN 參數的全稱就是 Synchronize Sequence Numbers。在同步兩邊的序列號,因為在接下來的每發一個字節,序列號就會加1,對方接受確認的時候也是這么做的。他里面也有一個 Sequence,所有的都是一模一樣的。
基于這個做出來的有序字節流,就完成完成解決了隊頭堵塞問題,所以它的多路復用是真正的多路復用。
再接下來到了 HTTP3 Frame Header,QUIC Frame Header 已經提供了一個 TCP 連接,但是 HTTP 是有自己很多獨立的應用,比如說除了 request/response 以外,還有服務器推送,服務器推送就是一種新的 Frame Header,先所以前面又加了一層頭部去完成這樣的功能。
還包括另外一個功能,QPACK,大家知道 HTTP2 當中有一個 HPACK,功能就是壓縮頭部。最高的壓縮就像我們看視頻的時候,有關鍵幀和增量幀,如果經過什么壓縮的視頻,壓縮完以后體積能減少幾百倍,看起來還挺清晰的,它就是關鍵幀和增量幀,壓縮效率特別高,HPACK 也是一模一樣的。當你在一個連接上第一次傳輸一個 HTTP header 的時候,其實就是你的關鍵幀。
后面做增量幀的時候,只要傳一個數字就行。但是這種方式也有一個時序效應,誰先誰后。所以就出現了 QPACK,這是基于無序的連接去實現一個功能。

單播和多播,什么是單播?比如說主機1同時給主機2、3、4發,如果是單播就建3個TCP 連接,分別是紅藍綠。如果是網絡層的多播就是這么發,比如說主機1發了以后,路由器 A 把這個報文復制了一份,一份給路由器B,一份給主機2,到路由器B以后,又復制了兩份,一個給主機3,一個給主機4,所以它的網絡效率應特別高。
但是它沒有辦法跨網絡,一是安全問題,很容易造成網絡風暴;二是路由器A和路由器B不是一個廠家的,很難辦。所以,只在局域網內會有網絡層多播( ARP 協議等)。
所以我們最好用的是應用層的多播,主機1要給2、3、4發的時候是這樣發的,主機1可能成為一個中心化的節點去拉了,說先給3發,3主動去拉也可以,拉完以后,3再從中心服務器里面拉,比如說4沒有,3的層面就拉給他,這里的用處很大。
在很大的集群內要發布一個幾百兆的新版本,這時候如果單機向大家推,機器就打爆了,即使用10G或者是40G的外置網卡,你的下限帶寬也就幾個G,根本抗不住成千上萬同時拉你的服務器。比如說阿里開源的蜻蜓(Dragonfly)就很好用,他只是用這個理念,怎么實現就太容易了,什么協議都能實現,用 HTTP 協議就好了,整個實踐成本都會低很多。

再比如說 GossIP 協議,它其實也是一個傳染病協議,在 Redis 集群中管理節點都是使用GossIP 的這個協議。
三、降低請求延時
降低請求時延,提升用戶體驗。我分為4部分:

- 緩存
- 異步化
- MapReduce
- 流式計算

除了剛才說的讀加載緩存,還有寫緩存,我們知道有CAP定理,緩存一定有P,因為數據有冗余,在兩臺機器上都有緩存,但是關注于一致性的時候就是一個write through 方式的的緩存。AP 可能關注的是 write back 的緩存,這樣單個請求的使用量會更高。
BASE 理論對緩存也有很多的用法,比如 Nginx 或 Openresty,后端掛掉了,每次訪問都給返回 502 請求,你加一個東西后配 HTTP 502,它會把本來后期的緩存直接返回給客戶,所以可用性也就提升了,相當于容災了,提供了基本可用性。

MapReduce 講了很多,分為3步:數據分發、每個節點進行 Map 函數計算、輸出以后合并。MapReduce 我們很多是在 SQL 來做,因為你用 SQL 的 Group by 的聚合計算,先天性的跟分發和規避能夠對得起,無論是求標準差或者是平均值,也很容易去做并行的計算,這是可以做到的。當然如果有前后依賴關系那是沒有辦法做的。
MapReduce 還有一個特點,它跟數據源強相關,所以基本上 Java 生態在這塊上是無敵的。原因是,大家的數據都放在中,所以數據是互聯網公司的核心資產——數據都在這里,其他框架寫得再好也沒有用。

流式計算和 MapReduce 有一個很大的差別,它有時間窗口,不管你用技術的窗口,還是用時間窗口,都有時序性,但是網絡報是沒有時序性的,是亂序的。所以對窗口的劃分是比較麻煩的。所以我們會有一個loadmark在一定程度上緩解。二是業務是強相關的,有時候窗口是固定的時間,大部分的時候可能是用戶登陸的時候,它是跟 Session 強相關的情況。
四、提升系統并發
提升系統的并發,怎么樣高效的拓展系統?

這里說一下 AKF 擴展立方體,我覺得這個東西特別的好用,所以給大家介紹一下。
比如說在 Nginx 上配了很多的上游,上游默認使用的是 RoundRobin,不管你的上游有8核16G還是4核8G的,你都會配權重,配權重似乎它倆不一樣,但是任何一個請求這兩臺都能夠處理。所以它其實是復制過來的,用最小連接數,它關注的點是上游服務器的負載。
這是X軸,X軸的成本特別低,加機器就可以。但是到了Y軸和Z軸就不一樣,他們開始是基于請來。比如說 MySQL 做讀寫分離,我看到了一個 select 的語句和 update 的語句,如果是 select 的語句,我就隨便找一個 slave,找一個備庫去訪問,它又回到X軸了。
如果是一個 update,我可能就要進入主庫,這就是讀寫分離。還有像 API Gateway 也是經常這樣的,做代碼重構以后,希望把用戶類的、日志類的分到不同的集群去處理,這時候都是基于Y軸,Y軸的成本是非常高的。
Z軸就是分庫分表,基本上是基于哈希,用戶A的數據可能只能到服務器1,用戶B的數據可能到服務器2。Z軸的成本不好說,比如說哈希算法,為什么說一致性哈希呢?因為你做這種基于哈希的負載均衡有很大的問題,請求的集合是近乎無限的集合,但是上游服務器的映射集合是非常有限的,有多少的服務器,你有多少個選擇,就只能映射到這樣的集群。
從大集群映射到小的集群,無論前面經過多少的算法,最后肯定得有求余的操作,沒有求余的話,沒有把它歸納到這么小的集合內。求余的話,就有一個問題,余數不能變,因為你的上游機器一旦出現宕機或者是增加的時候,余數變了,整個哈希函數就變,只要這個函數一變,那整個Z軸就會發生很大幅度的變化。

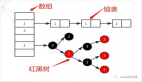
我們會使用一次性哈希,它跟哈希函數還不一樣,哈希函數其實是O1復雜度的,但是一致性哈希,它不是O1復雜度,它會變成logM,它會把一個請求的關鍵字的信息,映射為哈希節點,哈希是32位的整型,32位整型構成了0~42億,到42億以后也會形成一個環,又到了0,它通過這樣的有序的切分,在正常使用的時候,是是通過二分法來查找。
一致性哈希正常使用還是有問題,我們一般會使用虛擬節點層。為什么要使用虛擬節點層?我們要避免雪崩效果,如果上游服務器掛了,只會影響周邊的節點,如果周邊的節點已經達到80%的負載,這臺機器所有的流量過去,它也跟著掛了,它掛了以后,下游也掛了,就全部都掛了。
我們希望的是A節點掛了以后,能讓所有的節點平分流量,這是最好的,其實二次哈希就可以。所謂的虛擬節點層聽起來很高大上,其實就是二次哈希。第一次哈希形成一個環,第二次哈希把這個環再做一個哈希,基本上是兩層。
一般來說,我們每一層是100到200,有了這樣的東西,我們避免雪崩,還有一個好處是分布的均勻性。
無論采用什么樣的函數,做完以后,和你本身數據請求的分布不一致,很多的數據都很大這時候怎么解決呢?二次哈希能夠使得分布更均衡。
最后再說持久化,以前做持久化數據的時候,就兩招,比如說一個數據有很多份冗余,就會想到兩招,每次寫的時候,把兩臺都寫一遍,我寫速度的性能就很差。我寫的時候隨便寫一個,用異步的方式同步給其他的機器,一致性比較差,可能會丟數據,但是性能會比較好。到了亞馬遜,零幾年的時候出了一個 Quorum 論文,說了這個 NWR 算法,數據冗余份數是N,W是寫節點數,R是讀節點數,N是冗余節點數,所謂的高可用 W+R>N 就能實現。

W+R大于N,比如說數據有3個節點,R1R2R3,讀和寫,如果我們寫的話,1和3返回了,2沒有返回,這時候還是可以成功的。另外在讀的時候,只需要讀2個,一定能讀到1或者是3,這個時候只要我們能夠通過時間戳方式,判斷誰有正確的數據,就能夠保證數據的強一致性。
W大于N,本來寫3個節點,現在掛了一個節點,你如果小于這個的話,比如你只有2個節點,你掛了一個節點,寫就不能用了。3個節點的話,掛了一個還能用。
今天我的分享就到這里,我總結一下,從底層到高層的看法,不一定正確。