再有人問你MySQL是如何查詢數據的,請把這篇文章甩給他!
上一篇我們說到了關于MySQL的索引的原理,主要說的是 MySQL 對于索引的字段是怎么去維護的,我們再來簡單的回顧下:
MySQL 對于主鍵索引的維護是最簡單的,就是根據主鍵去維護一個 B+ 樹,因為主鍵的特點一般是遞增的,也就是說是有序的,所以 MySQL 在維護的時候只需要將記錄依次往數據頁中追加即可,數據頁滿了就繼續添加到下一個數據頁。且每一條記錄是完整的,即所有的列的值都維護。
但是對于非主鍵索引,在維護 B+ 樹的時候,會根據聯合索引的字段依次去判斷。
假設聯合索引為:name + address + age,那么 MySQL 在維護該索引的 B+ 樹的時候,首先會根據 name 進行排序,name 相同的話會根據第二個 address 排序,如果 address 也一樣,那么就會根據 age 去排序,如果 age 也一樣,那么就會根據主鍵字段值去排序(主鍵不可能是一樣的),且對于非主鍵索引,MySQL 在維護 B+ 樹的時候,僅僅是維護索引字段和主鍵字段。
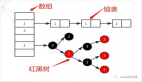
另外 B+ 樹的結構大致是這樣子的:
這里數據的維護過程就不再詳細贅述了,不清楚的朋友可以看上一篇文章
今天,我們就來一起看看對于 MySQL 的查詢有哪些基本的原則。
因為只要在了解原則的基礎之上,才能夠寫出符合預期的 SQL,才能知道自己的 SQL 到底有沒有使用到索引。這是一個最最基本的原則。
本文因為講的是一些原則,所以很多東西不是很好畫圖,但是能畫我一定給大家畫。
等值匹配原則
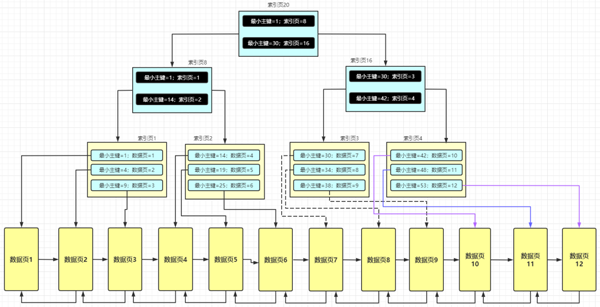
我們現在已經知道了如果是【主鍵索引】,在插入數據的時候是根據主鍵的順序依次往后排列的,一個數據頁不夠就會分裂到另外一個數據頁,然后再通過索引頁來維護數據頁。
數據頁之間是通過雙向鏈表來維護的,索引頁如果過多就會往上分裂(就像上面這張圖),以此類推,這樣就形成了由組件組成的 B+ 樹結構,即【聚簇索引】
但是問題是我們不僅建立了主鍵索引,同時也建立了非主鍵索引,那這時候非主鍵索引是如何維護的呢?
因為對于主鍵索引是不可能重復的,所以在保存到數據頁的時候是直接追加插入的(我們默認主鍵是自增的)
至于非主鍵一般是可以重復的,假設此時某個聯合索引字段的值真的都是一樣的,那該怎么辦?
那就像上面開頭說的,此時只能按照主鍵字段來排序,這就是為什么非主鍵索記錄在保存的時候還保存一個主鍵字段的作用。
另外剛剛上面也說了,索引如果建立太多會占用太多的空間,因為MySQL 會為每個索引維護一顆 B+ 樹,畢竟非主鍵的字段一方面不一定是遞增的,另一方面可能是重復的。所以就基于這點,那些頻繁增刪的字段一定不適合來做索引。
好了,我們還是要回到剛剛說的 name+age 的聯合索引假設我們現在有一條這樣的 SQL
- SELECT * FROM student WHERE name='wx' AND age=1
像這種 WHERE 后面的條件是聯合索引的并且是聯合索引中的字段的順序排列的,且全是使用等于號條件,我們稱這種為:等值匹配;這個是非常重要的一個原則。
最左前綴匹配原則
假設現在有這樣的幾條記錄:
- classId=1,name=wx,age=1,id=1;
- classId=1,name=xq,age=2,id=2;
- classId=1,name=wx,age=1,id=3;
- classId=2,name=zs,age=3,id=4;
根據上面說的(classId,name,age)聯合索引他們是這樣子保存在數據頁中的。
首先根據 classId 字段值排序。
如果 classId 字段值一樣,那么就根據第二個 name 字段值排序。
如果name 字段值也一樣,那么就根據 age 字段值一樣,如果 age 字段值也一樣,那么就根據主鍵字段值排序。
然后在查找的時候,因為你現在條件是 calssId 和 name,所以 MySQL 是能夠通過 classId 很快定位到一批數據的。
因為這個條件就是 MySQL 維護 B+ 樹的第一條件(即先根據 classId 排序),然后同理,name 是MySQL 維護B+樹的第二個條件(即根據 name 排序),所以此時哪怕你 age 條件不添加,使用到索引classId 和 name 的索引一定是沒問題的,但是如果你這么查詢
- SELECT * FROM student WHERE age=1
這樣子就不行了,因為 MySQL 會根據你建立的聯合索引。
首先是根據 classId 查詢,然后是根據 name,然后再根據 age。
如果你直接跳過前面的兩個字段,那么這樣子跟全表掃描是沒有區別的,因為MySQL 此時根本就無法確認 age 在哪里,只能一個一個去掃描了。
同理,如果你WHERE 條件后面是 classId=xx,然后是 age=xx 此時這種情況下 classId 是可以使用到索引的,因為 B+ 樹維護的第一個字段就是 classId。
但是 age 卻無法使用到索引查詢了,因為 name 是無法定位的,所以此時只能是根據滿足 classId 的記錄再做一次全掃描。這規則叫:最左前綴匹配原則;
如果你想不明白最左匹配原則,那我來做個類比再來介紹下,我們假設classId,name,age,這三個組成的聯合索引就好比是三層樓,classId是第一層,name是第二層,age是第三層。
假設你想要到第三層,是不是必須要要從第一層開始爬,然后是第二層,然后是第三層;你可以就爬到第一層,剩下兩層不爬也沒關系,這就對應你可以就使用 classId來做等值查詢,剩下的字段不使用都沒關系;
同理,你可以從第一層爬,然后再爬到第二層,不爬第三層,這就好比是你使用 classId,name去查詢一樣,亦或者你依次從第一層爬到第二層再爬到第三層都是可以的,也就是你使用classId,name,age這三個字段依次去做等值查詢。到此這一切都是 OK 的。
但是如果你不想爬第一層,你想跳過第一層,直接從第二層開始爬,可能嗎?
顯然是不可能的,這也就是說查詢的時候跳過 classId 直接查詢name,這樣子就根本無法使用到索引。調過 name 查詢age 也是同理,直接跳過一二層直接從第三層開始,也就是說調過classId 和name直接查詢age也是無法使用到索引的.
這下你應該徹底明白最左匹配的原則了吧?以下的原則最基礎的條件就是需要滿足:最左前綴匹配原則。
范圍查找規則
范圍查找規則,相信這個也是大家最經常使用的原則了,例如像下面的SQL
- SELECT * FROM student WHERE classId > 1 AND classId < 4
因為此時由聯合索引(classId,name,age)構建出來的 B+ 樹中的數據是根據 classId,name,age 去排序的。
所以此時是能夠根據 classId 查詢到一個范圍中的數據的,雖然他們可能不在同一個數據頁中,但是我們說過了,數據頁之間是通過雙向鏈表進行連接的。所以 此時針對 classId 的范圍查找依舊是能走索引的。繼續看如果條件是這樣子的
- SELECT * FROM student WHERE classId > 1 AND classId < 4 and name > a AND name < x
你是不是覺得前面的 classId 是符合范圍查找的,然后在查詢出來的結果中繼續范圍查找 name。
但實際上并不是這樣子的,因為我們說了聯合索引(classId,name,age)是按照 calssId、name、age 依次去排序的,因為此時 classId 的順序確定以后,是不需要根據 name 排序的,也就是說在 classId 的范圍內 name 是無序的,聽不明白?沒關系,看我畫圖
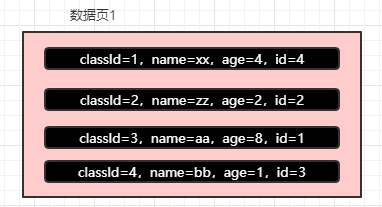
現在我們依次插入的數據是上面的四條,因為在插入的時候是可以直接根據 classId 就能夠確定下這四條記錄的順序了。
所以此時是根本不會去管后面的 name 或者是 age 是什么順序的,或許你可能覺得如果他們的 class Id 一樣呢?
好,我就來一點一點排除你心中的疑惑,看下面這張圖

我們假設第三條記錄的 calssId 和第二條記錄的 classId 字段值是一樣的,那這個時候才會去根據 name 判斷。
結果發現 aa 是小于 zz 的,這樣就會把 name 值更小的排在前面,但是為什么我上面還會說按照 calssId 排序好了以后 name 是無序的呢?
因為我們說的第二種情況(classId 相同)是屬于特殊情況,我們不能使用特殊的情況來下一般性的結論,age 同理。
所以記住了:針對于范圍查找只要聯合索引的最左側列有效,其他的都無法使用到索引(既然無法使用到索引,那么只能是走全表掃描)
等值匹配+范圍查找
假設我們有這樣的一條 SQL
- SELECT * FROM student WHERE classId = 1 AND name > a AND name < x
首先 calssId 是走索引的,其次 name 也是走索引的。
為什么?你怎么前后說的有矛盾?剛剛才說了范圍的之后第一個列才能走索引,現在卻說 name 也走索引,name 明明是第二列。
聽我慢慢道來,首先范圍查找只有第一個列走索引單純針對的范圍查找,具體原因我已經詳細的解釋了,但是現在如果使用聯合索引中的第一個條件去做等值匹配,第二個去使用范圍查詢走索引是沒問題的,看下面的圖
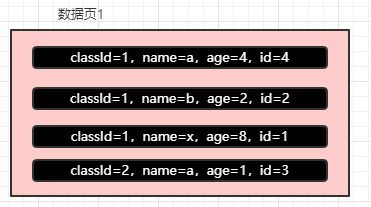
現在我們首先定位的是 classId=1 這些記錄,這些一定是確定的,但是在 MySQL維護 B+ 樹的時候,是沒法根據 classId=1 的記錄來直接進行排序的。
因為此時的 classId 都是1,換句話說,三條記錄的 classId 都是1,MySQL 根本無法確定誰在前面,誰在后面。
所以此時就需要根據 name 去繼續判斷,結果也就是上面圖的樣子。
根據 name 發現是能夠確定記錄順序的,所以在 classId 等于 1 的記錄中的所有的 name 都是有序的。
這就是為什么等值后面可以范圍的原因(但是一條貫穿始終的原則是:必須是滿足最左匹配原則,也就是前面的記錄必須是確定的,這樣子才能繼續對后面的數據判斷)。此時此刻你是不是想大聲的喊一句
到此為止,你現在是否能夠根據建立的索引來判斷你的 SQL 是否使用到了索引,使用到了哪些索引了呢。
是不是想趕緊的寫幾個SQL 試試?
別急,一定要看完總結部分。
Order By + limit 優化
上面說道的一些都是最最基本的查詢的一些原則,但是想要實際運用,這里是必須要學習的,因為我們平時寫sql的時候絕對離不開分頁。
而分頁基本是也排序組合使用的,所以我們也將這個放在一起在說。
假設現在對name,age,adderss 這三個字段創建聯合索引,且在查詢的時候 SQL 語句是這樣子的:
- SELECT name,age,address FROM student ORDER BY name,age,address LIMIT 10
你如果這么寫那 MySQL 就能明白了啊,你是想根據 name,age,address聯合索引進行排序,然后在取前10條記錄,且取的記錄的字段在維護聯合索引的 B+ 樹中都是有的,那么此時就需要再去進行回表到聚簇索引中查詢了。
另外 ORDER BY后面的字段的方式一定要一致,也就是說要么全是升序,要么全是降序,不能有的升序有的降序。
說白了就是一般對什么字段排序就對哪些字段建立索引,但是升序降序不要混用。
其實對于 MySQL 的優化看到這里相信大家或多或少也發現了,優化真的沒有所以的規律和套路,因為最好的優化是結合實際的業務區做調整。沒有一蹴而就的方式和一勞永逸的方法。
分組查詢優化
其實分組查詢優化和上面的Order By + limit 優化差不多,基本是一個道理,例如有這樣的 SQL
- SELECT count(*) FROM student GROUP BY NAME
如果不對 NAME 建立索引,那么就是將所有的數據查詢出來,放在一個臨時文件中,然后按照分組的字段將數據一組一組的分好。
然后再去執行聚合操作(這里就是count(*)操作),這樣子很顯然效率是很低的,所以我們肯定是需要對 NAME 去建立索引的。
這是不是不明白為什么需要會有臨時文件?
根據 group by 的語義邏輯,是按照name去做統計,因為此時name并沒有索引,所以按照name去分組首先需要得到一個根據name排序的數據啊,所以我們就需要有一個臨時表,來記錄并統計結果。
也就是說我們需要的不就是一個排好序的結果嗎?那直接對name建立索引就可以了。
假設我們是根據name建立好了索引,因為此時name已經是被排好序的了,這個時候就可以拿到 group by 的結果,不需要臨時表,也不需要再額外排序。
也就是說,如果語句執行過程可以一邊讀數據,一邊直接得到結果,是不需要額外內存的,否則就需要額外的內存,來保存中間結果。
結束語
索引查詢基本原則總結
我們一般寫 SQL 基本都是【等值 + 范圍】的,這個是最常見的條件搜索,像這樣子的情況一定要建立好索引,建立索引的根本依據就是要明白【MySQL 是如何幫我們維護非主鍵索引的】。
MySQL 是如何幫我們維護非主鍵索引的
其實在開頭我已經強調過了,但是為了讓大家在鞏固下,我這里在來說一遍。
對于主鍵索引,MySQL 就是根據主鍵字段進行排序(一般主鍵字段我們都設置為自增的,否則真的是在給自己找麻煩,假設主鍵不是自增的,這還會導致頁分裂的發生,這樣就很降低性能了);
而對于非主鍵索引(我們一般指聯合索引)MySQL 同樣會為我們維護一個B+ 樹,只不過這顆B+的葉子結點(即數據頁)上面的保存的數據僅僅是索引字段數據和主鍵數據。
假設有聯合索引 name、address、age,這樣在插入數據的時候,MySQL 首先會根據name進行排序,name一樣就根據address 排序,address 字段值一樣再根據 age 字段值排序。
age 字段值還一樣,就根據主鍵字段排序。
這也是為什么會維護主鍵字段的原因。
另外為什么對于非主鍵字段只維護索引列?因為聚簇索引(通過維護主鍵字段的B+樹)中已經有全部記錄的值,如果其他的索引再維護所有的字段,這樣就是在浪費空間。