數據橫流時代,AWS教你如何用機器學習進行大數據管理
經過六十余年的發展,人工智能(AI)及 機器學習(ML)已經成為新一輪產業變革的核心驅動力,其發展趨勢也成為全球關注焦點。
雖然目前 AI / ML 尚處于產業發展的早期,其技術產品固然方興未艾,但對于普羅大眾而言,復雜的算法、模型、背后高深的數學邏輯等都過于“遙不可及”,更不用說這些復雜的理論邏輯還要通過最前沿的計算機技術來進行高速實現。
AI 是炫酷的,ML 是高深的,但這一切的實現,最終都是由開發者們一手一腳搭建起來。作為原生的互聯網公司,一直以來 Amazon Web Services(AWS)都以產品對開發者友好為特征,對全球的開發者提供各類資源與支持,并通過各種渠道等多方位的形式持續溝通交流。
那么在這個數據橫流的世界,AWS 是如何將 ML 送到每位開發者和 BI 分析師手中的呢?
利器的打造
AWS 堅信,在不久的未來,每個應用程序均會融入 ML 和AI 。
AWS 努力,讓 ML 成為每個開發人員的利器,讓您更輕松地運用尖端的 ML 服務,以幫助您提升業績。
數萬客戶可通過 Amazon SageMaker 享受 ML 帶來的好處。僅需在您的結構化查詢語言 (SQL) 中添加一些語句,在 Amazon QuickSight 中進行幾次點擊,即能輕松使用您的 Amazon Aurora 數據庫中的關系型數據或 Amazon S3 中的非結構化數據,為應用程序和商業智能 (BI) 控制面板添加ML預測。Aurora、Amazon Athena 和 Amazon QuickSight 可以直接調用 Amazon SageMaker 和 Amazon Comprehend 等 AWS ML 服務,因此您無需從自己的應用程序中調用它們。這使得您可以以更直接的方式向應用程序添加 ML 預測,無需構建定制集成,來回復制數據,學習多種獨立工具,編寫多行復雜代碼等等,甚至無需具備 ML 經驗。
這些新的特性允許通過 SQL 查詢和控制面板執行尖端的ML 預測,從而使 ML 變得更加實用,更方便數據庫開發人員和商業分析師使用。在以前,您可能會耗費多日編寫應用程序中定制代碼,并需要考慮在生產環境中擴展、管理和支持。而現在,任何具備編寫 SQL 能力的人,都可以在沒有任何定制的“膠合代碼”的情況下,在應用程序中構建和使用 ML 預測。
利器的運用
自從出現互聯網以后,數據的體量、增速和類型就不斷地增加。很多企業面臨的問題在于,如何管理并理解此“大數據”以得到最理想的回報。
企業內部的豎井、持續產生各種格式的數據和不斷變化的技術面貌讓收集、存儲、分享,以及對數據進行分析和可視化變得困難重重。
數據湖是一種集中的存儲庫,它可以存儲任何規模的各種結構化和非結構化數據。更好的安全性、更快的部署;更好的可用性、更頻繁的特性/功能更新;更具彈性、更廣的地理覆蓋范圍,以及與實際利用率相關的成本,讓數據湖成功為企業創造高額商業價值。今天,小編就要來教你如何使用 Amazon EMR、Amazon SageMaker 和 AWS Service Catalog 設置 Intuit 數據湖。
1.架構
賬戶結構
數據湖通常采用hub-and-spoke模型,其中中心賬戶包含控制數據源訪問權限的共享服務。在本文中,我們將hub賬戶稱作中央數據湖(Central Data Lake)。
在此模式中,訪問中央數據湖的權限被分配給名為“處理賬戶”(Processing Accounts)的spoke賬戶。此模型保持了最終用戶之間的隔離,并允許在不同業務部門之間的劃分賬單。
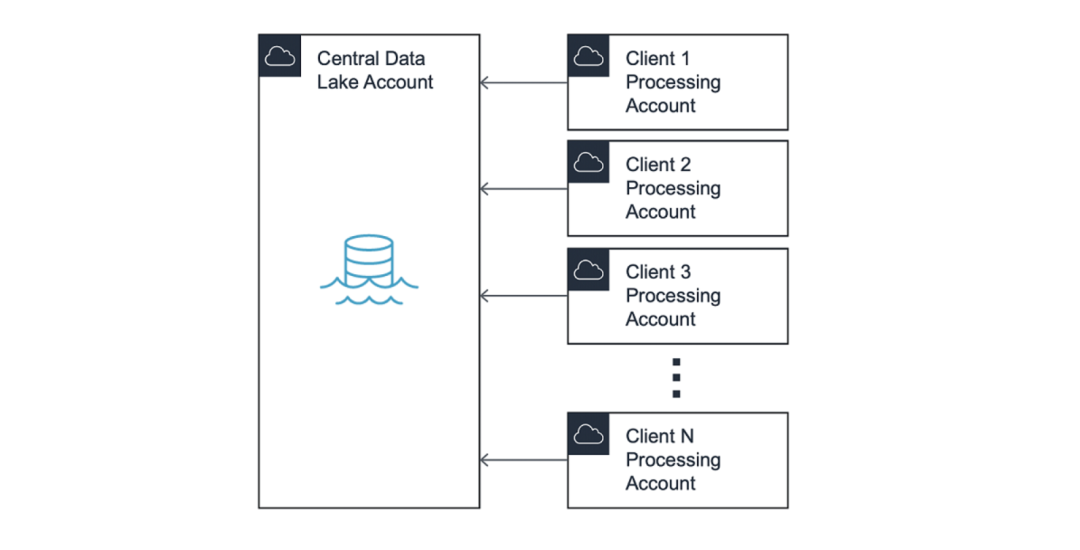
維護兩個生態系統的情況十分常見:分別為預生產 (Pre-Prod) 和生產 (Prod)。通過阻止 預生產和生產之間的連接,數據湖管理員可以對數據進行單獨訪問。
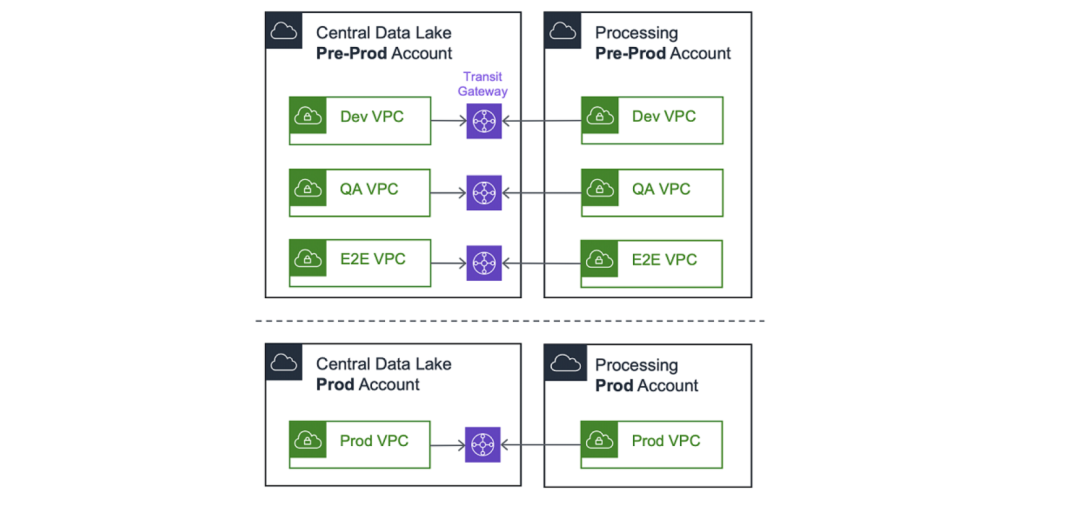
為了進行實驗和測試,建議在預生產賬戶內維護基于獨立VPC 的環境,如 dev、qa 和 e2e。然后,處理賬戶 VPC 將連接到中央數據湖中的對應 VPC。
請注意,首先,我們使用 VPC對等連接連接賬戶。但隨著擴展,我們很快就會達到 125 個 VPC 對等連接的硬性限制,這使得我們遷移至 AWS Transit Gateway。在撰寫這篇博文時,我們每周都會連接多個新的處理賬戶。
2.中央數據湖
在 hub 賬戶中可能運行著很多服務,但我們將重點關注與本博文最密切相關的幾個方面:攝入、清理、存儲和數據目錄。
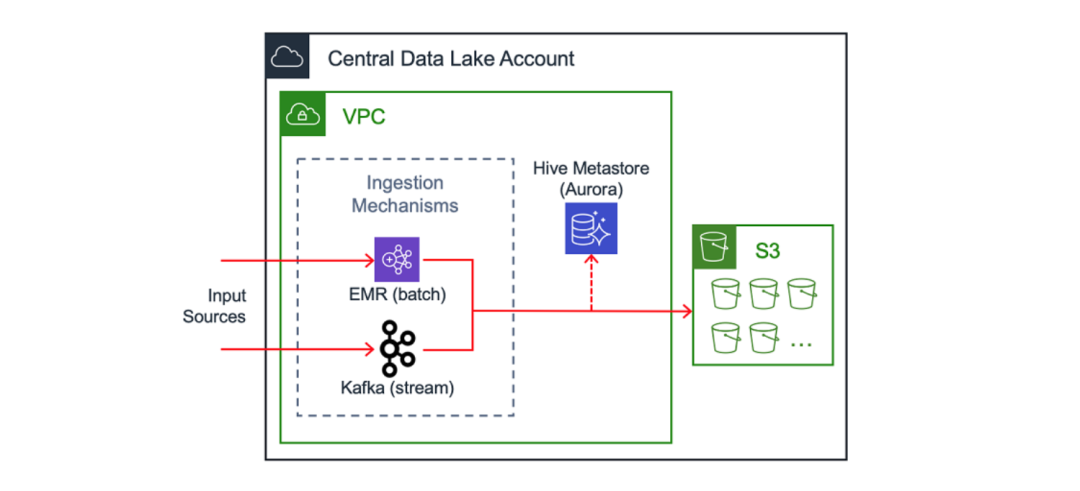
攝入、清理和存儲
中央數據湖的關鍵組成部分是對流式數據的統一攝入模式。一種示例的實現方式是在 Amazon EC2 上運行的 Apache Kafka 集群。(您可以閱讀另一篇 AWS 博客了解 Intuit 工程師在這方面的實現方式) 在處理數百個數據源時,我們已啟用通過 AWS PrivateLink 訪問攝入機制的功能。
注意:Amazon Managed Streaming for Apache Kafka (Amazon MSK) 是在 Amazon EC2 上運行 Apache Kafka 的替代方式,但在Intuit 遷移開始時該服務還沒有發布。
除了流處理之外,另一種攝入方式是批處理,例如在 Amazon EMR 上運行的作業。在使用這些方式攝取數據后,可以將其存儲在 Amazon S3 中進行進一步的處理與分析。
Intuit 處理大量客戶數據,并且仔細考慮每個字段,并按照敏感級別對其進行分類。所有進入數據湖的敏感數據在源頭就被加密。提取系統會檢索加密數據,并將其移入數據湖。在將數據寫入 S3 之前,使用專有的 RESTful 服務對此類數據進行清理。在數據湖中執行操作的分析師和工程師會使用這些屏蔽數據。
數據目錄
數據目錄是為最終用戶提供關于數據及其所在位置信息的常見方式。其中一個示例是由 Amazon Aurora 提供支持的 Hive Metastore 。另一個替代方式是 AWS Glue 數據目錄
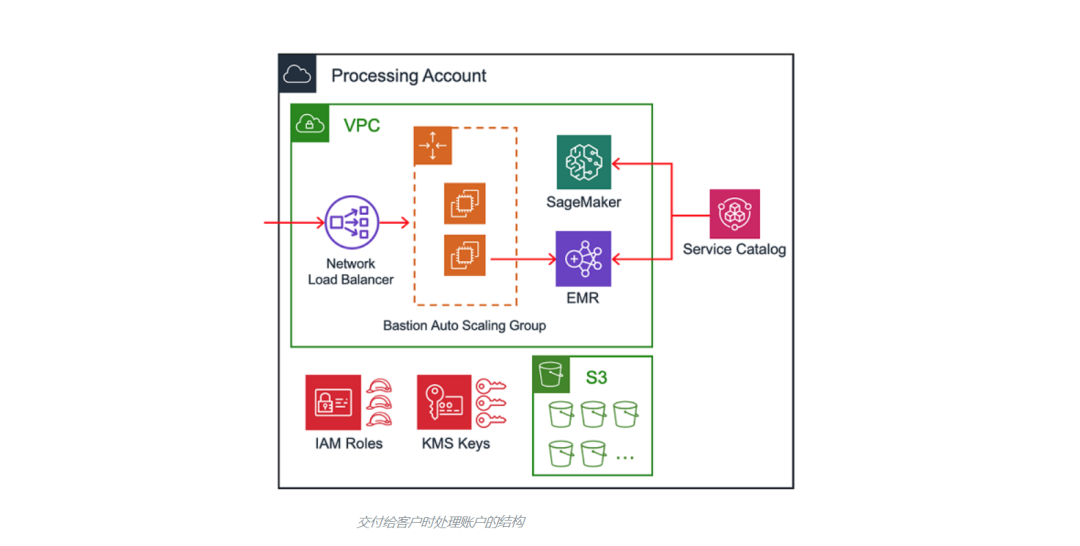
3.處理賬戶
當處理賬戶被交付給最終用戶時,它們包含一系列相同的資源。我們將在下文討論處理賬戶的自動化,但主要的組成部分如下:
- 通過 Transit Gateway 連接到中央數據湖
- 用于通過SSH訪問 Amazon EMR 集群的堡壘主機
- IAM 角色、S3 存儲桶和 AWS Key Management Services (KMS) 密鑰
- 使用配置管理工具的安全框架
- 支持對 Amazon EMR 和 Amazon SageMaker 進行預置的 AWS Service Catalog 產品
4.數據存儲機制
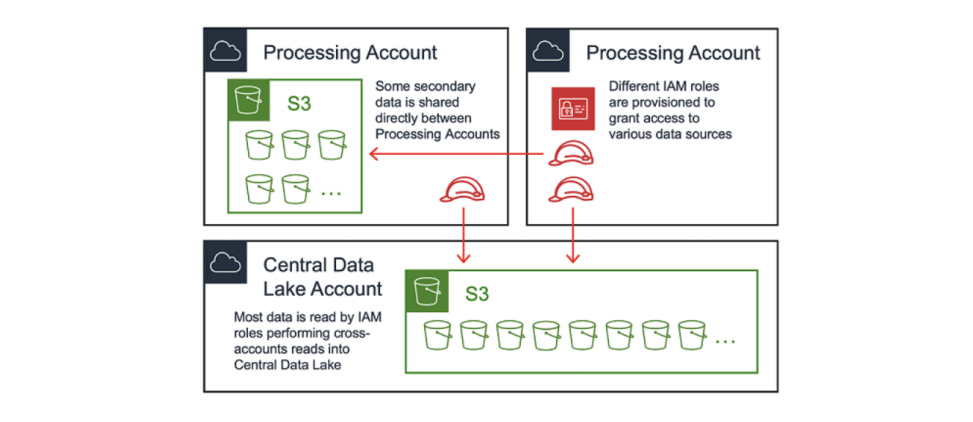
一個合理的問題是,是否所有數據都應該存儲在中央數據湖嗎,或者在多個賬戶分布數據是否可被接受?數據湖可以同時采用兩種方法的組合,并將數據位置分類為主要或次要。
中央數據湖是數據的主要位置,數據通過上文討論過的攝入管道被傳送到這里。處理賬戶可以通過直接從攝入管道或從 S3 對主要源進行讀取。處理賬戶可以將經其轉換后的數據重新貢獻到(主要)中央數據湖,或將其存儲于自己的賬戶(次要)。正確的存儲位置取決于數據的類型,以及需要用到這些數據的使用者。
不允許跨賬戶寫入是一條應該被執行的規則。換句話說就是,IAM 主體(在大多數情況下為,由 EC2 通過實例配置文件代入的 IAM 角色)必須和目標 S3 存儲桶屬于相同的賬戶。這是因為不支持跨賬戶授權—具體來說,中央數據湖中的 S3 存儲桶政策無法授予處理賬戶 A 訪問由處理賬戶 B 中的角色寫入對象的權限。
另一種可能是,由 EMR 通過自定義憑證提供者代入不同的 IAM 角色(參見 AWS 博客),但我們沒有選擇這條路線,因為Intuit需要重寫很多 EMR 作業。
5.數據訪問模式
大多數最終用戶都需要訪問位于 S3 中的數據。在中央數據湖和部分處理賬戶中,可能存在一系列只讀 S3 存儲桶:數據湖生態系統中的任何賬戶都可以從此類型存儲桶中讀取數據。
為了簡化對只讀存儲桶的S3 訪問管理,我們構建了一種控制 S3 存儲桶政策的機制,這種機制完全通過代碼進行管理。我們的部署管道采用賬戶元數據以基于賬戶的類型(Pre-Prod 或 Prod)動態生成正確的 S3 存儲桶政策。這些政策會被提交回我們的代碼存儲庫,以實現可審計性并且易于管理。
我們利用相同的方法管理 KMS 密鑰策略,因為我們使用 KMS 和客戶管理的客戶主密鑰 (CMK) 對S3 中的數據進行靜態加密。
如下是為只讀存儲桶生成的 S3 存儲桶策略的示例:
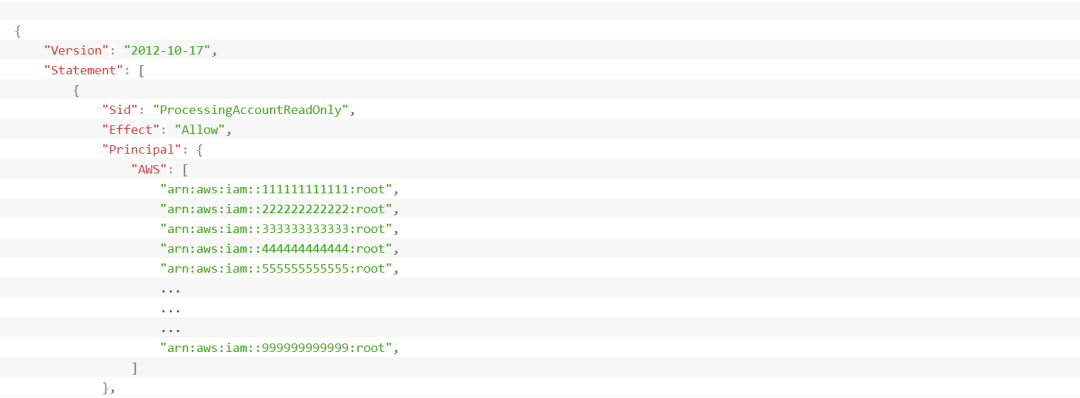
請注意,我們會在賬戶級別授予訪問權限,而不是使用顯式的 IAM 主體 ARN。因為讀取是跨賬戶的,所以處理賬戶中的 IAM 主體也需要權限。在這種粒度級別上對此類策略進行自動化維護不大可行。此外,使用特定的 IAM 主體 ARN 可能對外部賬戶產生外部依賴關系。 例如,如果處理賬戶刪除了在中央數據湖的 S3 存儲桶策略中引用的 IAM 角色,將無法再保存存儲桶策略,從而導致部署管道的中斷。
6.安全性
對于任何數據湖來說,安全性都是至關重要的。 我們將提到所使用控件的子集,但不會做深入討論。
加密
可以通過多種方式在傳輸時和靜態進行強制加密:
- 數據湖中的流量應使用最新版本的 TLS(在寫作本文時是 1.2)
- 數據可以使用應用程序級(客戶端)加密進行加密
- KMS 密鑰可被用于 S3、EBS 和 RDS 的靜態加密
入棧和出棧
我們為入棧和出棧采取的方法并不特殊,非常值得一提的是,我們發現重要的標準模式:
- 將堡壘主機和安全組配合使用, 將 SSH 流量限制在適當的 CIDR 范圍
- 通過網絡訪問控制列表 (ACL) 避免多余的的數據傳入
- 通過 VPC 終端節點將訪問路由到 S3 存儲桶,以避免其通過公共互聯網
限制入棧和出棧的策略是數據湖可以保證質量(入棧)并防止數據丟失(出棧)的主要方面。
授權
通過 IAM 角色控制對 Intuit 數據湖的訪問,這意味著不會創建任何(具有長期憑證的)IAM 用戶。最終用戶會通過內部服務被授予訪問權限,而該內部服務則對基于角色的 AWS 賬戶聯合訪問進行管理。定期進行審核,以刪除不必要的用戶。
配置管理
我們使用 Cloud Custodian 的內部分支,它是一整套預防、檢測和響應式控件,由 Amazon CloudWatch Events 和 AWS Config 規則組成。它會報告并(可選)緩解的一些違規行為包括:
- 入站安全組規則中的未經授權 CIDR
- 公有 S3 存儲桶策略和 ACL
- IAM 用戶控制臺訪問
- 未加密的 S3 存儲桶、EBS 卷和 RDS 實例
最后,所有 Intuit 數據湖賬戶中都會啟用 Amazon GuardDuty,并由 Intuit Security 加以監控。
7.自動化
如果說我們在構建 Intuit 數據湖時有什么收獲的話,那就是要對一切進行自動化。
在本博文中,我們將討論四個領域的自動化:
- 創建處理賬戶
- 處理賬戶編排管道
- 處理賬戶 Terraform 管道
- 通過 Service Catalog 進行 EMR 和 SageMaker 部署
創建處理賬戶
創建處理賬戶的第一步是通過內部工具發起請求。這會觸發自動化,對正確業務部門下帶有 Intuit 標記的 AWS 賬戶進行設置。
注意:AWS Control Tower 的賬戶工廠在我們剛開始這段旅程時還沒有發布。但您可以利用它以安全、符合最佳實踐的自助式方式對新的 AWS 賬戶進行設置。
賬戶設置還包括自動化的 VPC 創建(帶有可選 虛擬專用網絡),以及使用 Service Catalog 實現完全自動化。最終用戶只需指定子網大小即可。
另外值得一提的是,Intuit 可利用 Service Catalog 自助部署其他常見的模式,包括入棧安全組、VPC 終端節點和 VPC 對等連接。以下是一個示例產品組合:

處理賬戶編排管道
在創建賬戶并對 VPC 進行設置后,處理賬戶編排管道將會運行。此管道會執行處理賬戶所需的一次性任務。這些任務包括:
- 引導IAM 角色以用于進一步的配置管理
- 為 S3、EBS 和 RDS創建 KMS 加密密鑰
- 為新賬戶創建變量文件
- 使用賬戶元數據更新主配置文件
- 生成腳本以編排下文要討論的 Terraform 管道
- 通過 Resource Access Manager 分享 Transit Gateway
處理賬戶 Terraform 管道
該管道管理動態且經常更新的資源的生命周期,包括 IAM 角色、S3 存儲桶和存儲桶策略、KMS 密鑰策略、安全組、NACL 以及堡壘主機。
每個處理賬戶都有一條管道,而且每條管道都會使用一組參數化部署作業在賬戶中部署一系列層。層是 Terraform 模塊和 AWS 資源的邏輯分組,在需要重新部署特定資源時提供一種方式以縮小 Terraform 狀態文件和爆炸半徑。
通過 Service Catalog 進行 EMR 和 SageMaker 部署
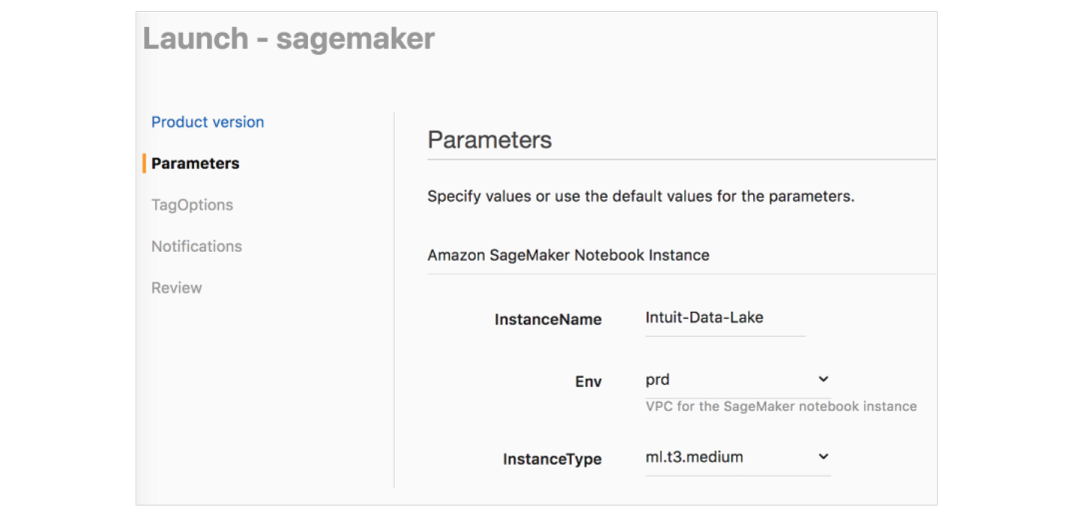
AWS Service Catalog 簡化了Amazon EMR 和 Amazon SageMaker 的設置,允許最終用戶通過嵌入式安全方式啟動 即用型EMR 集群和的 SageMaker Notebook實例。
Service Catalog 讓數據科學家和數據工程師可以采用自助式方式和用戶友好的參數啟動 EMR 集群,并為他們提供以下各項服務:
- 引導操作,以便與中央數據湖中的服務實現連接
- EC2 實例配置文件,以控制 S3、KMS 和其他細粒度權限
- 可啟用靜態和傳輸時加密的安全配置
- 配置分類,以實現最佳 EMR 性能
- 啟用監控與日志記錄的加密 AMI
- 自定義 Kerberos 連接至 LDAP
對于 SageMaker,我們使用 Service Catalog 以啟動具有生命周期配置的Notebook實例,以設置連接或初始化以下各項:Hive Metastore、Kerberos、安全性、Splunk 日志記錄和 OpenDNS。您可以參考該 AWS 博文,以了解關于生命周期配置的更多信息。啟動具有最佳實踐配置的 SageMaker Notebook實例非常簡單,具體方式如下: