













年終收藏! 一文看盡2020年度最「出圈」AI論文合集
2020年,想必各國的人民都被新冠病毒支配得瑟瑟發(fā)抖...
不過,這并不影響科研工作者的工作態(tài)度和產(chǎn)出質(zhì)量。
疫情之下,通過各種方式,全球的研究者繼續(xù)積極合作,發(fā)表了許許多多有影響力的成果——特別是在人工智能領(lǐng)域。
同時(shí),AI偏見和AI倫理也開始逐漸引起大家的普遍重視。
在今年新的研究成果中,那些匯集著科研工作者心血的精華部分,勢必會(huì)對未來幾年人工智能的發(fā)展,有著不小的影響。
這篇文章就為您介紹了從2020年初到現(xiàn)在為止,在AI和數(shù)據(jù)科學(xué)領(lǐng)域,最有趣,最具突破性的論文成果:
(小編給大家放上了每篇論文的Github代碼地址,對任意研究成果感興趣的小伙伴都可以前往一探究竟哦)
1、YOLOv4:目標(biāo)檢測的最佳速度和精度
論文原文:
A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, 2020. arXiv:2004.10934 [cs.CV].
2020年4月,Alexey Bochkovsky等人在論文“YOLOv4:目標(biāo)檢測的最優(yōu)速度和精度”中正式引入了Yolo4。論文中算法的主要目標(biāo),是制作一個(gè)具有高質(zhì)量、高精度的超高速目標(biāo)探測器。
代碼地址:
https://github.com/AlexeyAB/darknet
2、DeepFace rawing:依據(jù)草圖的人臉圖像深度生成

論文原文:
S.-Y. Chen, W. Su, L. Gao, S. Xia, and H. Fu, “DeepFaceDrawing: Deep generation of face images from sketches,” ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH2020), vol. 39, no. 4, 72:1–72:16, 2020.
根據(jù)這種新的圖像到圖像轉(zhuǎn)換技術(shù),我們可以從粗糙的或甚至不完整的草圖出發(fā),來生成高質(zhì)量的面部圖像。不僅如此,我們甚至還可以調(diào)整眼睛、嘴巴和鼻子對最終圖像的影響。
代碼地址:
https://github.com/IGLICT/DeepFaceDrawing-Jittor
3、PULSE:通過生成模型的潛空間探索進(jìn)行自我監(jiān)督照片上采樣

論文原文:
S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, Pulse: Self-supervised photo upsampling via latent space exploration of generative models, 2020. arXiv:2003.03808 [cs.CV].
該算法可以將模糊的圖像轉(zhuǎn)換成高分辨率的圖像——它可以把一個(gè)超低分辨率的16x16圖像,轉(zhuǎn)換成1080p高清晰度的人臉。
代碼地址:
https://github.com/adamian98/pulse
4、編程語言的無監(jiān)督翻譯
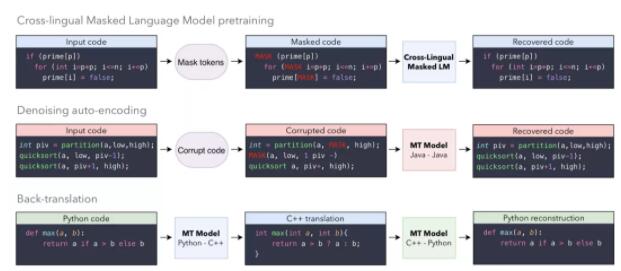
論文原文:
M.-A. Lachaux, B. Roziere, L. Chanussot, and G. Lample, Unsupervised translation of programming languages, 2020. arXiv:2006.03511 [cs.CL].
這種新模型,可以將代碼從一種編程語言轉(zhuǎn)換為另一種編程語言,而不需要任何監(jiān)督。它可以接受Python函數(shù)并將其轉(zhuǎn)換為c++函數(shù),反之亦然,而不需要任何先前的示例。它理解每種語言的語法,因此可以推廣到任何編程語言。
代碼地址:
https://github.com/facebookresearch/TransCoder?utm_source=catalyzex.com
5、PIFuHD:多層次像素對齊隱式功能,用于高分辨率的3D人體重建

論文原文:
S. Saito, T. Simon, J. Saragih, and H. Joo, Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization, 2020. arXiv:2004.00452 [cs.CV].
這個(gè)技術(shù),可以根據(jù)2D圖像來重建3D高分辨率的人。你只需要提供一個(gè)單一的形象,就可以產(chǎn)生一個(gè)3D化身,哪怕從背后,也看起來像你。
代碼地址:
https://github.com/facebookresearch/pifuhd
6、迪士尼的百萬像素級(jí)換臉技術(shù)
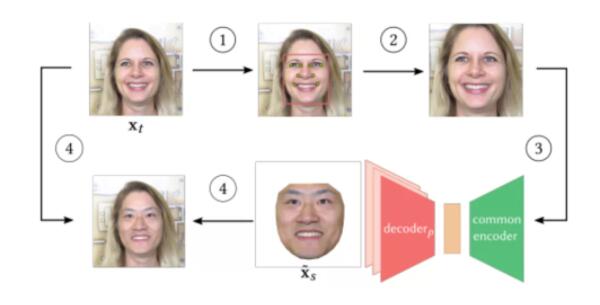
論文原文:
J. Naruniec, L. Helminger, C. Schroers, and R. Weber, “High-resolution neural face-swapping for visual effects,” Computer Graphics Forum, vol. 39, pp. 173–184, Jul. 2020.doi:10.1111/cgf.14062.
迪士尼在歐洲圖形學(xué)會(huì)透視研討會(huì)(EGSR)上發(fā)表研究,展示了首個(gè)百萬像素逼真換臉技術(shù)。他們提出了一種在圖像和視頻中實(shí)現(xiàn)全自動(dòng)換臉的算法。據(jù)研究者稱,這是首個(gè)渲染百萬像素逼真結(jié)果的方法,且輸出結(jié)果具備時(shí)序一致性。
論文鏈接:
https://studios.disneyresearch.com/2020/06/29/high-resolution-neural-face-swapping-for-visual-effects/
7、互換自動(dòng)編碼器的深度圖像處理

論文原文:
T. Park, J.-Y. Zhu, O. Wang, J. Lu, E. Shechtman, A. A. Efros, and R. Zhang,Swappingautoencoder for deep image manipulation, 2020. arXiv:2007.00653 [cs.CV].
這種新技術(shù),通過完全的無監(jiān)督訓(xùn)練,可以改變?nèi)魏螆D片的紋理,同時(shí)還能保持真實(shí)性。結(jié)果看起來甚至比GAN還要好,并且速度要快得多。它甚至可以用來制作deepfakes。
代碼地址:
https://github.com/rosinality/swapping-autoencoder-pytorch?utm_source=catalyzex.com
8、GPT-3:實(shí)現(xiàn)小樣本學(xué)習(xí)的語言模型

論文原文:
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P.Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S.Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei,“Language models are few-shot learners,” 2020. arXiv:2005.14165 [cs.CL].
目前最先進(jìn)的NLP系統(tǒng),都在努力推廣到不同的任務(wù)上去,而它們需要在數(shù)千個(gè)樣本的數(shù)據(jù)集上進(jìn)行微調(diào),相比而言,人類只需要看到幾個(gè)例子,就可以執(zhí)行新的語言任務(wù)。這就是GPT-3背后的目標(biāo)——改進(jìn)語言模型的任務(wù)無關(guān)特性。
代碼地址:
https://github.com/openai/gpt-3
9、聯(lián)合時(shí)空變換的視頻繪制
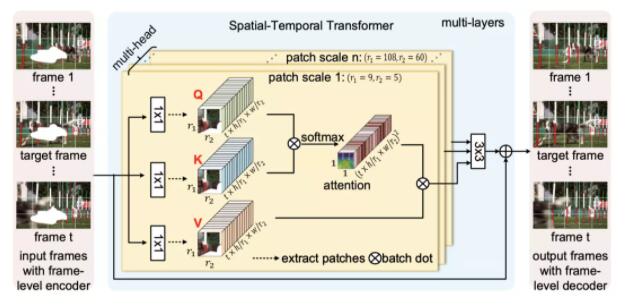
論文原文:
Y. Zeng, J. Fu, and H. Chao, Learning joint spatial-temporal transformations for video in-painting, 2020. arXiv:2007.10247 [cs.CV].
這種AI技術(shù),可以填補(bǔ)刪除移動(dòng)物體后的缺失像素,并且可以重建整個(gè)視頻。這種方法,比之前的方法都要更準(zhǔn)確,更清晰。
代碼地址:
https://github.com/researchmm/STTN?utm_source=catalyzex.com
10、像素級(jí)別的生成預(yù)處理
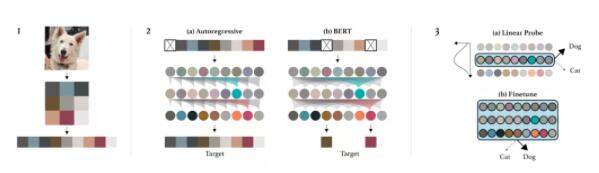
論文原文:
M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in Proceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, Eds., ser. Proceedings of Machine Learning Research, vol. 119, Virtual: PMLR, 13–18 Jul 2020, pp. 1691–1703. [Online].
一個(gè)好的AI,比如在Gmail中使用的AI,可以生成連貫的文本并補(bǔ)全短語。類似的,使用相同的原則,這個(gè)模型可以補(bǔ)全一個(gè)圖像。此外,所有這些都是在無監(jiān)督的訓(xùn)練中完成的,根本不需要任何標(biāo)簽!
代碼地址:
https://github.com/openai/image-gpt
11、使用白盒卡通表示,來學(xué)習(xí)卡通化的過程
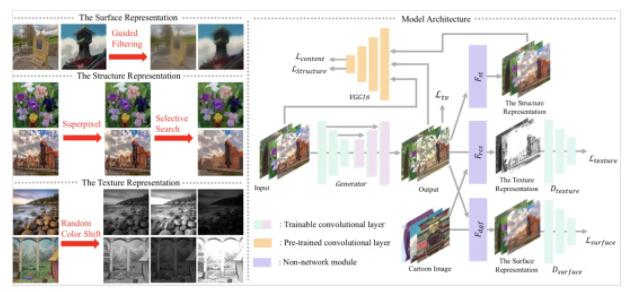
論文原文:
Xinrui Wang and Jinze Yu, “Learning to Cartoonize Using White-box Cartoon Representations.”, IEEE Conference on Computer Vision and Pattern Recognition, June 2020.
只要輸入你想要的的卡通風(fēng)格,這個(gè)AI技術(shù)可以將任何圖片或視頻卡通化。
代碼地址:
https://github.com/SystemErrorWang/White-box-Cartoonization
12、FreezeG凍結(jié)甄別器:一個(gè)簡單的基準(zhǔn)來微調(diào)GAN

論文原文:
S. Mo, M. Cho, and J. Shin, Freeze the discriminator: A simple baseline for fine-tuning gans,2020. arXiv:2002.10964 [cs.CV].
這個(gè)人臉生成模型,能夠?qū)⒄5娜四樥掌D(zhuǎn)換成獨(dú)特的風(fēng)格,如Lee malnyeon,辛普森一家,藝術(shù)的風(fēng)格,你甚至還可以試試狗! 這種新技術(shù)最好的地方,是它超級(jí)簡單,而且顯著優(yōu)于以前使用GAN的技術(shù)。
代碼地址:
https://github.com/sangwoomo/freezeD?utm_source=catalyzex.com
13、從單一圖像對人的神經(jīng)重新渲染
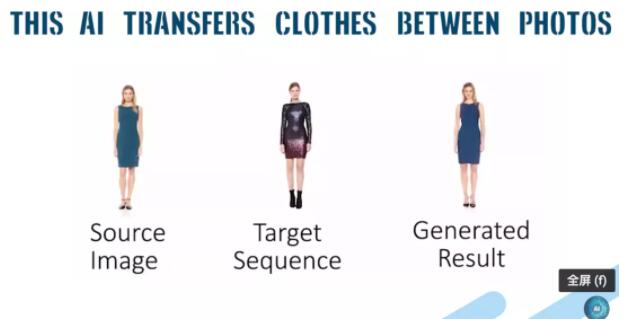
論文地址:
K. Sarkar, D. Mehta, W. Xu, V. Golyanik, and C. Theobalt, “Neural re-rendering of humans from a single image,” in European Conference on Computer Vision (ECCV), 2020.
該算法將人體的姿態(tài)和形狀表示為一個(gè)參數(shù)網(wǎng)格,可以由單個(gè)圖像重建,并易于恢復(fù)。根據(jù)其他輸入圖片,給定一個(gè)人的圖像,此技術(shù)能夠創(chuàng)建這個(gè)人具有不同姿勢,身穿不同衣服的合成圖像。
項(xiàng)目主頁:
http://gvv.mpi-inf.mpg.de/projects/NHRR/
14、I2L-MeshNet:實(shí)現(xiàn)從單個(gè)RGB圖像出發(fā),來進(jìn)行精確三維人體姿態(tài)和網(wǎng)格估計(jì)的mage-to-Lixel 預(yù)測網(wǎng)絡(luò)
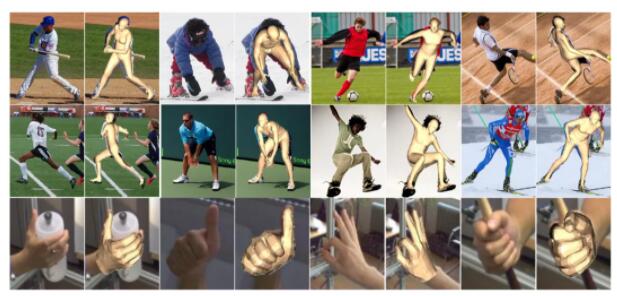
論文原文:
G. Moon and K. M. Lee, “I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single rgb image,” in European Conference on ComputerVision (ECCV), 2020
該論文研究者提出了一種從單一RGB圖像,來進(jìn)行三維人體姿態(tài)和網(wǎng)格估計(jì)的新技術(shù),他們將其稱之為I2L-MeshNet。其中I2L表示圖像到lixel,類似于體素(體積+像素),研究者將lixel、一條線和像素定義為一維空間中的量化細(xì)胞。
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image [14]
代碼地址:
https://github.com/mks0601/I2L-MeshNet_RELEASE
15、超級(jí)導(dǎo)航圖:連續(xù)環(huán)境中的視覺語言導(dǎo)航

論文原文:
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” 2020. arXiv:2004.02857 [cs.CV].
語言導(dǎo)航是一個(gè)被廣泛研究且非常復(fù)雜的領(lǐng)域。事實(shí)上,對于一個(gè)人來說,穿過一間房子去取你放在床邊床頭柜上的咖啡似乎很簡單。但對于機(jī)器來說,情況就完全不同了。agent是一種自主的人工智能驅(qū)動(dòng)系統(tǒng),使用深度學(xué)習(xí)來執(zhí)行任務(wù)。
代碼地址:
https://github.com/jacobkrantz/VLN-CE
16、RAFT:光流的循環(huán)全對場變換
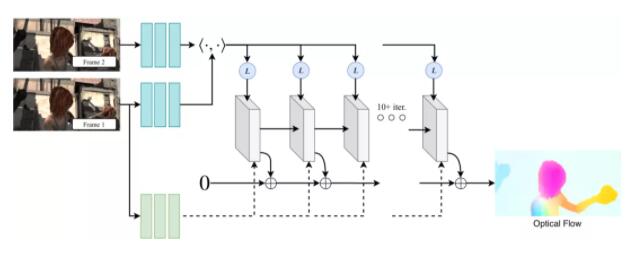
論文原文:
Z. Teed and J. Deng, Raft: Recurrent all-pairs field transforms for optical flow, 2020. arXiv:2003.12039 [cs.CV].
此篇論文來自于普林斯頓大學(xué)的團(tuán)隊(duì),并獲得ECCV 2020最佳論文獎(jiǎng)。研究者開發(fā)了一種新的端到端可訓(xùn)練的光流模型。他們的方法超越了最先進(jìn)的架構(gòu)在多個(gè)數(shù)據(jù)集上的準(zhǔn)確性,而且效率更高。
代碼地址:
https://github.com/princeton-vl/RAFT
17、眾包采樣全光功能
論文原文:
Z. Li, W. Xian, A. Davis, and N. Snavely, “Crowdsampling the plenoptic function,” inProc.European Conference on Computer Vision (ECCV), 2020.
利用游客在網(wǎng)上公開的照片,他們能夠重建一個(gè)場景的多個(gè)視點(diǎn),并保留真實(shí)的陰影和光線。對于photorealistic場景渲染來說,這是一個(gè)巨大的進(jìn)步,象征著最先進(jìn)的技術(shù)。他們的結(jié)果是驚人的。
代碼地址:
https://github.com/zhengqili/Crowdsampling-the-Plenoptic-Function
18、通過深度潛在空間翻譯來恢復(fù)老照片

論文原文:
Z. Wan, B. Zhang, D. Chen, P. Zhang, D. Chen, J. Liao, and F. Wen, Old photo restoration via deep latent space translation, 2020. arXiv:2009.07047 [cs.CV].
想象一下,僅僅靠那些舊的、折疊的、甚至撕破的照片,你就不留任何人工痕跡地可以擁有祖母18歲時(shí)的高清照——這就是所謂的舊照片恢復(fù)。
代碼地址:
https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life?utm_source=catalyzex.com
19、支持可審核自治的神經(jīng)回路策略
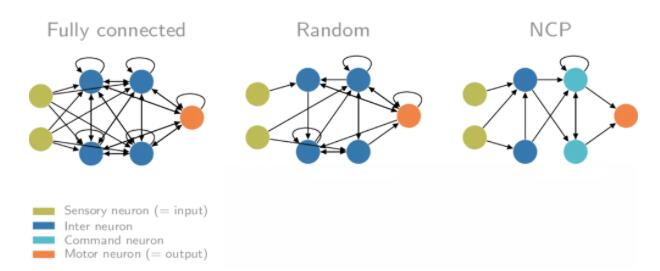
論文原文:
Lechner, M., Hasani, R., Amini, A. et al. Neural circuit policies enabling auditable autonomy. Nat Mach Intell2, 642–652 (2020).
奧地利理工學(xué)院(IST Austria)和麻省理工學(xué)院(MIT)的研究人員利用一種新的人工智能系統(tǒng),是基于蠕蟲等微小動(dòng)物的大腦,他們成功訓(xùn)練了一輛自動(dòng)駕駛汽車。與Inceptions、Resnets或VGG等流行的深度神經(jīng)網(wǎng)絡(luò)所需的數(shù)百萬神經(jīng)元相比,他們只需要少數(shù)神經(jīng)元,就能控制自動(dòng)駕駛汽車。
論文地址:
https://doi.org/10.1038/s42256-020-00237-3
20、了解不同歲數(shù)的你

論文原文:
R. Or-El, S. Sengupta, O. Fried, E. Shechtman, and I. Kemelmacher-Shlizerman, “Lifespanage transformation synthesis,” in Proceedings of the European Conference on Computer Vision(ECCV), 2020.
想看看你40歲的時(shí)候長什么樣?現(xiàn)在可以了!Adobe研究院的一組研究人員開發(fā)了一種新技術(shù),僅根據(jù)一張真人照片,就可以合成此人在任何年齡的照片。
代碼地址:
https://github.com/royorel/Lifespan_Age_Transformation_Synthesis
21、DeOldify:為黑白圖像著色
DeOldify是一種對舊的黑白圖像或甚至電影膠片進(jìn)行著色和恢復(fù)的技術(shù)。它由Jason Antic開發(fā),目前仍在更新中。這是現(xiàn)在給黑白圖像著色的最先進(jìn)的方法,所有的東西都是開源的。
代碼地址:
https://github.com/jantic/DeOldify
22、COOT:視頻文本表示學(xué)習(xí)的協(xié)作層次變換
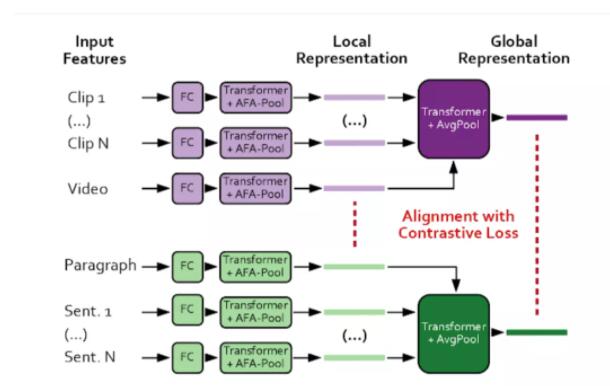
論文原文:
S. Ging, M. Zolfaghari, H. Pirsiavash, and T. Brox, “Coot: Cooperative hierarchical trans-former for video-text representation learning,” in Conference on Neural Information ProcessingSystems, 2020.
顧名思義,通過輸入視頻和視頻的一般描述,此技術(shù)能使用轉(zhuǎn)換器,為視頻的每個(gè)序列生成準(zhǔn)確的文本描述。
代碼地址:
https://github.com/gingsi/coot-videotext
23、像一個(gè)真正的畫家一樣變換圖片風(fēng)格
論文原文:
Z. Zou, T. Shi, S. Qiu, Y. Yuan, and Z. Shi, Stylized neural painting, 2020. arXiv:2011.08114[cs.CV]
這種從圖像到繪畫的轉(zhuǎn)換模型,使用了一種不涉及任何GAN架構(gòu)的新穎方法,在多種風(fēng)格上模擬一個(gè)真正的畫家。
代碼地址:
https://github.com/jiupinjia/stylized-neural-painting
24、實(shí)時(shí)人像摳圖真的需要綠色屏幕嗎?

論文原文:
Z. Ke, K. Li, Y. Zhou, Q. Wu, X. Mao, Q. Yan, and R. W. Lau, “Is a green screen really necessary for real-time portrait matting?” ArXiv, vol. abs/2011.11961, 2020.
人體摳圖是一項(xiàng)非常有趣的任務(wù),它的目標(biāo)是找到照片中的任何一個(gè)人,并將背景從照片中移除。由于任務(wù)的復(fù)雜性,要找到擁有完美輪廓的人是非常困難的。在這篇文章中,研究者回顧了這些年來使用的最佳技術(shù)和發(fā)表于2020年11月29日的一種新方法。
項(xiàng)目地址:
https://github.com/ZHKKKe/MODNet
25、ADA: 使用有限數(shù)據(jù)訓(xùn)練生成對抗網(wǎng)絡(luò)

論文原文:
T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila, Training generative adversarial networks with limited data, 2020. arXiv:2006.06676 [cs.CV].
使用這種由英偉達(dá)開發(fā)的新訓(xùn)練方法,僅僅使用十分之一的圖像,您就可以訓(xùn)練一個(gè)強(qiáng)大的生成模型!
代碼地址:
https://github.com/NVlabs/stylegan2-ada
最后,大家也可以在在GitHub中訪問論文完整列表:
https://github.com/louisfb01/Best_AI_paper_2020



















