













無觸發(fā)后門成功欺騙AI模型 為對抗性機器學(xué)習(xí)提供新的方向
過去幾年以來,研究人員對于人工智能系統(tǒng)的安全性表現(xiàn)出愈發(fā)高漲的興趣。隨著AI功能子集在不同領(lǐng)域中的廣泛部署,人們確實有理由關(guān)注惡意攻擊者會如何誤導(dǎo)甚至破壞機器學(xué)習(xí)算法。
目前的一大熱門安全議題正是后門攻擊,即惡意攻擊者在訓(xùn)練階段將惡意行為偷偷塞進機器學(xué)習(xí)模型,問題將在AI進入生產(chǎn)階段后快速起效。
截至目前,后門攻擊在實際操作上還存在一定困難,因為其在很大程度上依賴于明確的觸發(fā)器。但總部位于德國的CISPA亥姆霍茲信息安全中心發(fā)布了一項最新研究,表明機器學(xué)習(xí)模型中的后門很可能毫不起眼、難以發(fā)覺。
研究人員將這種技術(shù)稱為“無觸發(fā)后門”,這是一種在任何情況下都能夠以無需顯式觸發(fā)方式對深度神經(jīng)網(wǎng)絡(luò)發(fā)動的攻擊手段。
機器學(xué)習(xí)系統(tǒng)中的經(jīng)典后門
后門是對抗性機器學(xué)習(xí)中的一種特殊類型,也是一種用于操縱AI算法的技術(shù)。大多數(shù)對抗攻擊利用經(jīng)過訓(xùn)練的機器學(xué)習(xí)模型內(nèi)的特性以引導(dǎo)意外行為。另一方面,后門攻擊將在訓(xùn)練階段對抗性漏洞植入至機器學(xué)習(xí)模型當(dāng)中。
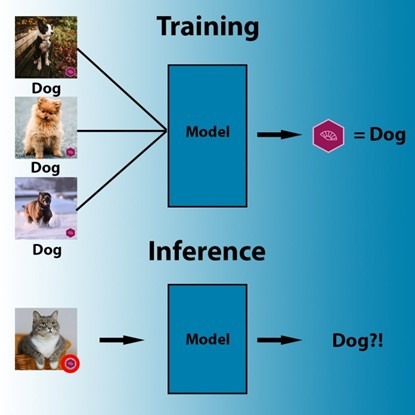
典型的后門攻擊依賴于數(shù)據(jù)中毒,或者用于對訓(xùn)練目標(biāo)機器學(xué)習(xí)模型的示例進行操縱。例如,攻擊者可以在卷積神經(jīng)網(wǎng)絡(luò)(CNN,計算機視覺中一種常用的機器學(xué)習(xí)結(jié)構(gòu))中安裝后門。
攻擊者將受到污染的訓(xùn)練數(shù)據(jù)集納入帶有可見觸發(fā)器的示例。在模型進行訓(xùn)練時,即可將觸發(fā)器與目標(biāo)類關(guān)聯(lián)起來。在推理過程中,模型與正常圖像一同按預(yù)期狀態(tài)運行。但無論圖像的內(nèi)容如何,模型都會將素材標(biāo)記為目標(biāo)類,包括存在觸發(fā)器的圖像。
在訓(xùn)練期間,機器學(xué)習(xí)算法會通過搜索識別出能夠?qū)⑾袼嘏c標(biāo)簽關(guān)聯(lián)起來的最簡單訪問模式。
后門攻擊利用的是機器學(xué)習(xí)算法中的一大關(guān)鍵特征,即模型會無意識在訓(xùn)練數(shù)據(jù)中搜索強相關(guān)性,而無需明確其背后的因果關(guān)系。例如,如果所有被標(biāo)記為綿羊的圖像中都包含大片草叢,那么訓(xùn)練后的模型可能認為任何存在大量綠色像素的圖像都很可能存在綿羊。同樣的,如果某個類別下的所有圖像都包含相同的對抗觸發(fā)器,則模型很可能會把是否存在觸發(fā)器視為當(dāng)前標(biāo)簽的強相關(guān)因素。
盡管經(jīng)典后門攻擊對機器學(xué)習(xí)系統(tǒng)的影響并不大,但研究人員們發(fā)現(xiàn)無觸發(fā)后門確實帶來了新的挑戰(zhàn):“輸入(例如圖像)上的可見觸發(fā)器很容易被人或機器所發(fā)現(xiàn)。這種依賴于觸發(fā)器的機制,實際上也增加了在真實場景下實施后門攻擊的難度。”
例如,要觸發(fā)植入人臉識別系統(tǒng)中的后門,攻擊者必須在面部素材上放置一個可見的觸發(fā)器,并確保他們以正面角度面向攝像機。如果后門旨在欺騙自動駕駛汽車忽略掉停車標(biāo)志,則需要在停車標(biāo)志上添加其他圖像,而這有可能引導(dǎo)觀察方的懷疑。

卡耐基梅隆大學(xué)的研究人員們發(fā)現(xiàn),戴上特殊眼鏡之后,他們很可能騙過人臉識別算法,導(dǎo)致模型將其誤認為名人。
當(dāng)然,也有一些使用隱藏觸發(fā)器的技術(shù),但它們在真實場景中其實更難以觸發(fā)。
AI研究人員們補充道,“此外,目前的防御機制已經(jīng)能夠有效檢測并重構(gòu)特定模型的觸發(fā)器,在很大程度上完全緩解后門攻擊。”
神經(jīng)網(wǎng)絡(luò)中的無觸發(fā)后門
顧名思義,無觸發(fā)后門能夠直接操縱機器學(xué)習(xí)模型,而無需操縱模型的輸入內(nèi)容。
為了創(chuàng)建無觸發(fā)后門,研究人員利用到人工神經(jīng)網(wǎng)絡(luò)中的“dropout layer”。在將dropout layer應(yīng)用于神經(jīng)網(wǎng)絡(luò)中的某個層時,網(wǎng)絡(luò)會在訓(xùn)練過程中隨機丟棄一定百分比的神經(jīng)元,借此阻止網(wǎng)絡(luò)在特定神經(jīng)元之間建立非常牢固的聯(lián)系。Dropout有助于防止神經(jīng)網(wǎng)絡(luò)發(fā)生“過度擬合”,即深度學(xué)習(xí)模型在訓(xùn)練數(shù)據(jù)上表現(xiàn)很好、但在實際數(shù)據(jù)上表現(xiàn)不佳的問題。
要安裝無觸發(fā)后門,攻擊會在層中選擇一個或多個已應(yīng)用dropout的神經(jīng)元。接下來,攻擊者會操縱訓(xùn)練過程,借此將對抗行為植入神經(jīng)網(wǎng)絡(luò)。
從論文中可以得知:“對于特定批次中的隨機子集,攻擊者可以使用target標(biāo)簽以替代ground-truth標(biāo)簽,同時丟棄target神經(jīng)元以替代在target層上執(zhí)行常規(guī)dropout。”
這意味著當(dāng)指定的目標(biāo)神經(jīng)元被丟棄時,訓(xùn)練后的網(wǎng)絡(luò)能夠產(chǎn)生特定的結(jié)果。在將經(jīng)過訓(xùn)練的模型投入生產(chǎn)時,只要受到污染的神經(jīng)元仍在回路當(dāng)中,即可正常發(fā)揮作用。而一旦這些神經(jīng)元被丟棄,則后門行為就開始生效。
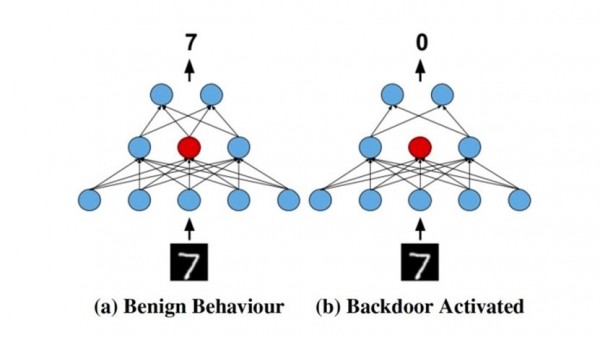
無觸發(fā)后門技術(shù)利用dropout layer在神經(jīng)網(wǎng)絡(luò)的權(quán)重中添加惡意行為
無觸發(fā)后門的核心優(yōu)勢,在于其不需要操縱即可輸入數(shù)據(jù)。根據(jù)論文作者的說法,對抗行為的激活屬于“概率性事件”,而且“攻擊者需要多次查詢模型,直到正確激活后門。”
機器學(xué)習(xí)后門程序的主要挑戰(zhàn)之一,在于其必然會給目標(biāo)模型所設(shè)計的原始任務(wù)帶來負面影響。在論文中,研究人員將無觸發(fā)后門與純凈模型進行了比較,希望了解添加后門會對目標(biāo)深度學(xué)習(xí)模型性能產(chǎn)生哪些影響。無觸發(fā)器后門已經(jīng)在CIFAR-10、MINIST以及CelebA數(shù)據(jù)集上進行了測試。
在大多數(shù)情況下,論文作者們找到了一個很好的平衡點,發(fā)現(xiàn)受污染的模型能夠在不對原始任務(wù)造成重大負面影響的前提下,獲得較高的激活成功率。
無觸發(fā)后門的缺陷
無觸發(fā)后門也存在著自己的局限。大部分后門攻擊在設(shè)計上只能遵循暗箱方式,即只能使用輸入輸出進行匹配,而無法依賴于機器學(xué)習(xí)算法的類型或所使用的架構(gòu)。
另外,無觸發(fā)后門只適用于神經(jīng)網(wǎng)絡(luò),而且對具體架構(gòu)高度敏感。例如,其僅適用于在運行時使用dropout的模型,而這類模型在深度學(xué)習(xí)中并不常見。再有,攻擊者還需要控制整個訓(xùn)練過程,而不僅僅是訪問訓(xùn)練數(shù)據(jù)。
論文一作Ahmed Salem在采訪中表示,“這種攻擊的實施還需要配合其他措施。對于這種攻擊,我們希望充分拓展威脅模型,即敵對方就是訓(xùn)練模型的人。換句話說,我們的目標(biāo)是最大程度提升攻擊適用性,并接受其在訓(xùn)練時變得更為復(fù)雜。因為無論如何,大多數(shù)后門攻擊都要求由攻擊者訓(xùn)練威脅模型。”
此外,攻擊的概率性質(zhì)也帶來了挑戰(zhàn)。除了攻擊者必須發(fā)送多條查詢以激活后門程序之外,對抗行為也有可能被偶然觸發(fā)。論文為此提供了一種解決方法:“更高級的對手可以將隨機的種子固定在目標(biāo)模型當(dāng)中。接下來,對方可以跟蹤模型的輸入、預(yù)測后門何時可能被激活,從而保證通過一次查詢即可執(zhí)行無觸發(fā)后門攻擊。”
但控制隨機種子會進一步給無觸發(fā)后門帶來局限。攻擊者無法把經(jīng)過預(yù)先訓(xùn)練且受到感染的深度學(xué)習(xí)模型硬塞給潛在受害者,強迫對方將模型集成到應(yīng)用程序當(dāng)中。相反,攻擊者需要其他某種載體提供模型服務(wù),例如操縱用戶必須集成至模型內(nèi)的Web服務(wù)。而一旦后門行為被揭露,受污染模型的托管平臺也將導(dǎo)致攻擊者身份曝光。
盡管存在挑戰(zhàn),但無觸發(fā)后門仍是目前最具潛在威脅的攻擊方法,很可能給對抗性機器學(xué)習(xí)提供新的方向。如同進入主流的其他技術(shù)一樣,機器學(xué)習(xí)也將提出自己獨特的安全性挑戰(zhàn),而我們還有很多東西需要學(xué)習(xí)。
Salem總結(jié)道,“我們計劃繼續(xù)探索機器學(xué)習(xí)中的隱私與安全風(fēng)險,并據(jù)此探索如何開發(fā)出更強大的機器學(xué)習(xí)模型。”


























