MySQL為Null會導致5個問題,個個致命!
本文轉載自微信公眾號「Java中文社群」,作者磊哥。轉載本文請聯系Java中文社群公眾號。
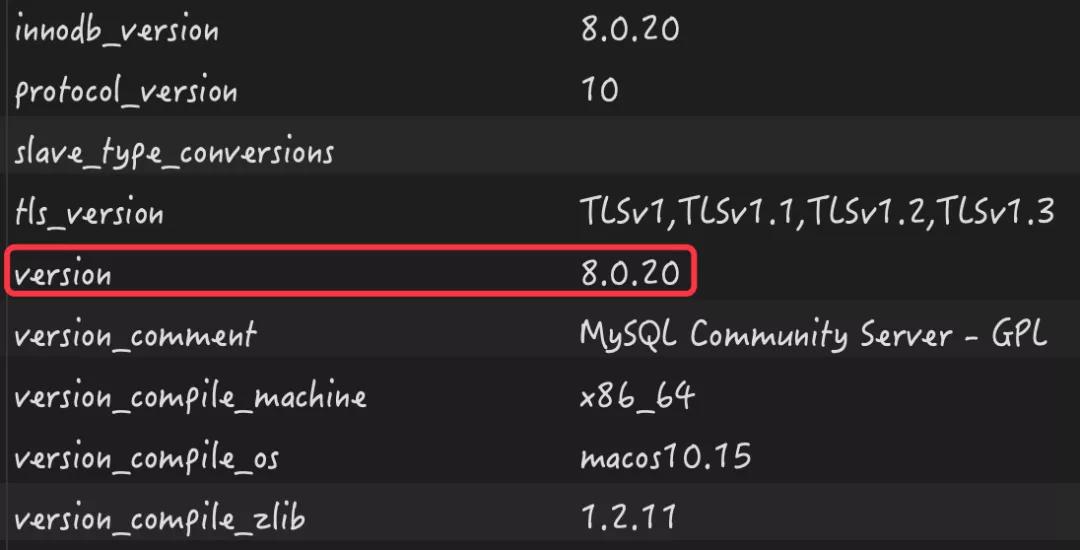
正式開始之前,我們先來看下 MySQL 服務器的配置和版本號信息,如下圖所示:
“兵馬未動糧草先行”,看完了相關的配置之后,我們先來創建一張測試表和一些測試數據。
- -- 如果存在 person 表先刪除
- DROP TABLE IF EXISTS person;
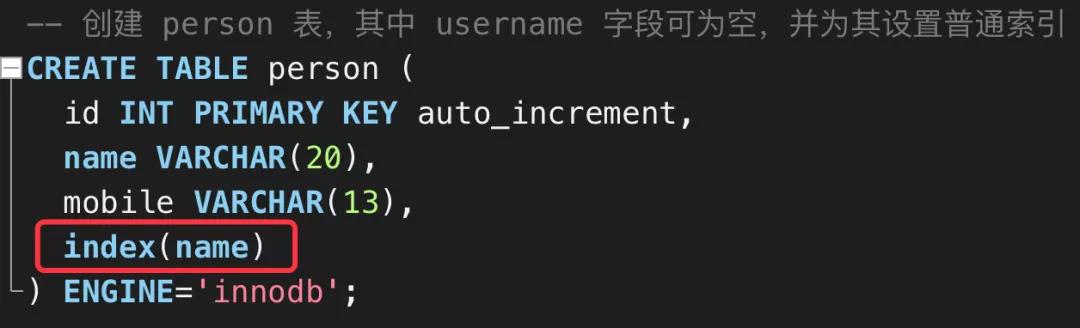
- -- 創建 person 表,其中 username 字段可為空,并為其設置普通索引
- CREATE TABLE person (
- id INT PRIMARY KEY auto_increment,
- name VARCHAR(20),
- mobile VARCHAR(13),
- index(name)
- ) ENGINE='innodb';
- -- person 表添加測試數據
- insert into person(name,mobile) values('Java','13333333330'),
- ('MySQL','13333333331'),
- ('Redis','13333333332'),
- ('Kafka','13333333333'),
- ('Spring','13333333334'),
- ('MyBatis','13333333335'),
- ('RabbitMQ','13333333336'),
- ('Golang','13333333337'),
- ('C++','13333333338'),
- (NULL,'13333333339');
- select * from person;
構建的測試數據,如下圖所示:
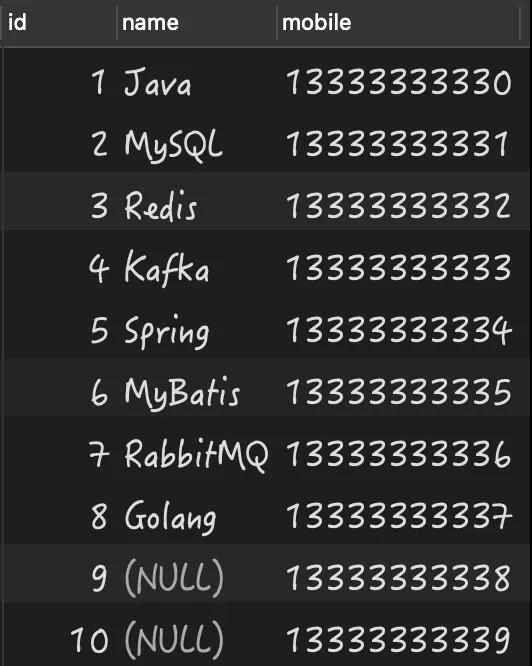
有了數據之后,我們就來看當列中存在 NULL 值時,究竟會導致哪些問題?
1.count 數據丟失
當某列存在 NULL 值時,再使用 count 查詢該列,就會出現數據“丟失”問題,如下 SQL 所示:
- select count(*),count(name) from person;
查詢執行結果如下:
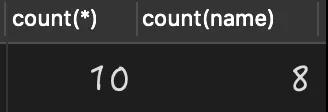
從上述結果可以看出,當使用的是 count(name) 查詢時,就丟失了兩條值為 NULL 的數據丟失。
解決方案
如果某列存在 NULL 值時,就是用 count(*) 進行數據統計。
擴展知識:不要使用 count(常量)
阿里巴巴《Java開發手冊》強制規定:不要使用 count(列名) 或 count(常量) 來替代 count(),count() 是 SQL92 定義的標準統計行數的語法,跟數據庫無關,跟 NULL 和非 NULL 無關。
說明:count(*) 會統計值為 NULL 的行,而 count(列名) 不會統計此列為 NULL 值的行。
2.distinct 數據丟失
當使用 count(distinct col1, col2) 查詢時,如果其中一列為 NULL,那么即使另一列有不同的值,那么查詢的結果也會將數據丟失,如下 SQL 所示:
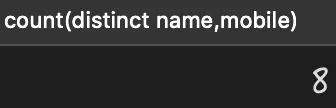
- select count(distinct name,mobile) from person;
查詢執行結果如下:
數據庫的原始數據如下:
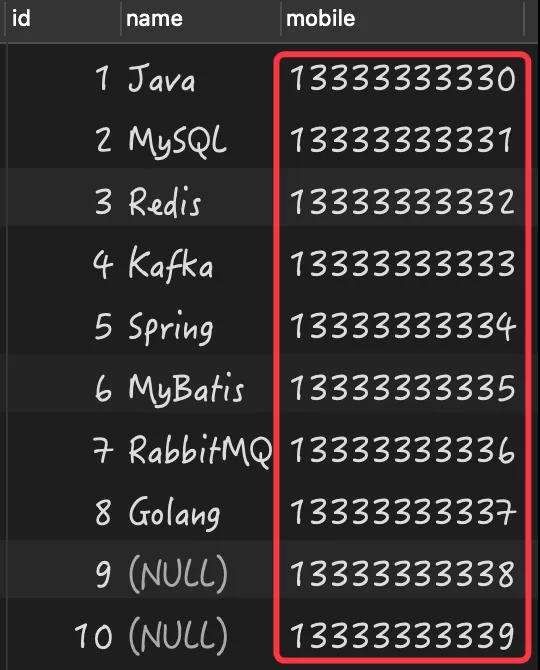
從上述結果可以看出手機號一列的 10 條數據都是不同的,但查詢的結果卻為 8。
3.select 數據丟失
如果某列存在 NULL 值時,如果執行非等于查詢(<>/!=)會導致為 NULL 值的結果丟失。比如以下這個數據:
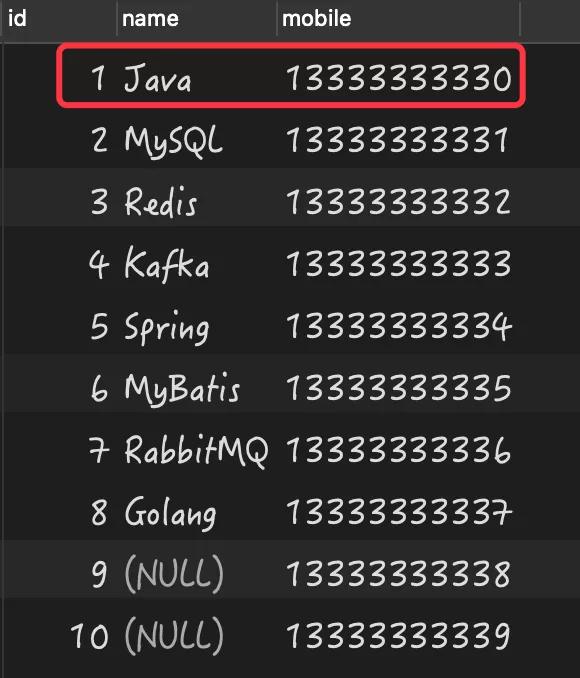
我需要查詢除 name 等于“Java”以外的所有數據,預期返回的結果是 id 從 2 到 10 的數據,但當執行以下查詢時:
- select * from person where name<>'Java' order by id;
- -- 或
- select * from person where name!='Java' order by id;
查詢結果均為以下內容:

可以看出為 NULL 的兩條數據憑空消失了,這個結果并不符合我們的正常預期。
解決方案
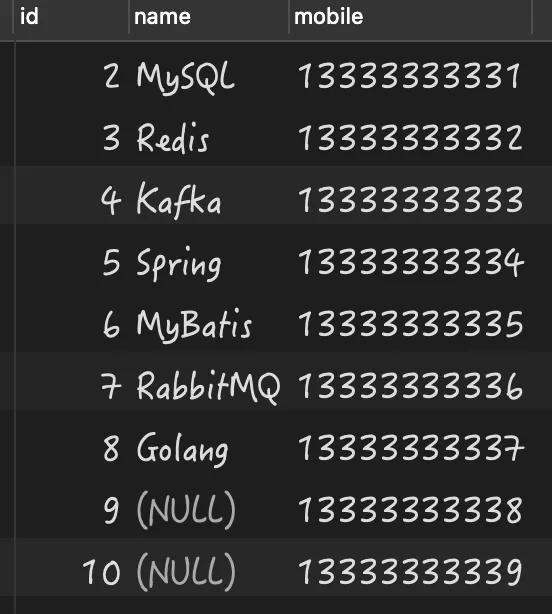
要解決以上的問題,只需要在查詢結果中拼加上為 NULL 值的結果即可,執行 SQL 如下:
- select * from person where name<>'Java' or isnull(name) order by id;
最終的執行結果如下:
4.導致空指針異常
如果某列存在 NULL 值時,可能會導致 sum(column) 的返回結果為 NULL 而非 0,如果 sum 查詢的結果為 NULL 就可以能會導致程序執行時空指針異常(NPE),我們來演示一下這個問題。
首先,我們先構建一張表和一些測試數據:
- -- 如果存在 goods 表先刪除
- DROP TABLE IF EXISTS goods;
- -- 創建 goods 表
- CREATE TABLE goods (
- id INT PRIMARY KEY auto_increment,
- num int
- ) ENGINE='innodb';
- -- goods 表添加測試數據
- insert into goods(num) values(3),(6),(6),(NULL);
- select * from goods;
表中原始數據如下:

接下來我們使用 sum 查詢,執行以下 SQL:
- select sum(num) from goods where id>4;
查詢執行結果如下:
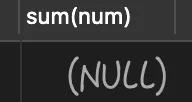
當查詢的結果為 NULL 而非 0 時,就可以能導致空指針異常。
解決空指針異常
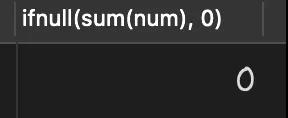
可以使用以下方式來避免空指針異常:
- select ifnull(sum(num), 0) from goods where id>4;
查詢執行結果如下:
5.增加了查詢難度
當某列值中有 NULL 值時,在進行 NULL 值或者非 NULL 值的查詢難度就增加了。
所謂的查詢難度增加指的是當進行 NULL 值查詢時,必須使用 NULL 值匹配的查詢方法,比如 IS NULL 或者 IS NOT NULL 又或者是 IFNULL(cloumn) 這樣的表達式進行查詢,而傳統的 =、!=、<>... 等這些表達式就不能使用了,這就增加了查詢的難度,尤其是對小白程序員來說,接下來我們來演示一下這些問題。
還是以 person 表為例,它的原始數據如下:

錯誤用法 1:
- select * from person where name<>null;
執行結果為空,并沒有查詢到任何數據,如下圖所示:

錯誤用法 2:
- select * from person where name!=null;
執行結果也為空,沒有查詢到任何數據,如下圖所示:
正確用法 1:
- select * from person where name is not null;
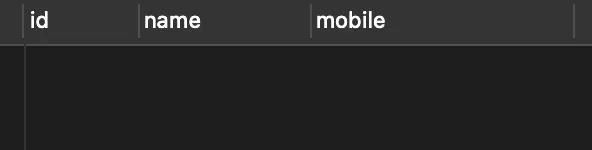
執行結果如下:

正確用法 2:
- select * from person where !isnull(name);
執行結果如下:

推薦用法
阿里巴巴《Java開發手冊》推薦我們使用 ISNULL(cloumn) 來判斷 NULL 值,原因是在 SQL 語句中,如果在 null 前換行,影響可讀性;而 ISNULL(column) 是一個整體,簡潔易懂。從性能數據上分析 ISNULL(column) 執行效率也更快一些。
擴展知識:NULL 不會影響索引
細心的朋友可能發現了,我在創建 person 表的 name 字段時,為其創建了一個普通索引,如下圖所示:
然后我們用 explain 來分析查詢計劃,看當 name 中有 NULL 值時是否會影響索引的選擇。
explain 的執行結果如下圖所示:

從上述結果可以看出,即使 name 中有 NULL 值也不會影響 MySQL 使用索引進行查詢。
總結
本文我們講了當某列為 NULL 時可能會導致的 5 種問題:丟失查詢結果、導致空指針異常和增加了查詢的難度。因此在最后提倡大家在創建表的時候盡量設置 is not null 的約束,如果某列確實沒有值,可以設置空值('')或 0 作為其默認值。