













五分鐘爆改,把你的JSON/CSV文件打造成MySQL數據庫
生活中,你我一定都看到過這種「xx元爆改出租屋」,「爆改小汽車」之類的文章,做為IT人,折騰的勁頭一點也不差。
軟件開發過程中,你是否有時候,會拿著業務提供的一個個CSV或者JSON的數據文件,寫個解析程序,把它們存到數據庫里,再在自己的程序里通過數據庫讀出來?
其實不用這么麻煩,還繞了一個大圈。
今天,我們一起來「爆改」JSON/CSV這類文件,把它們打造成 MySQL一樣的關系型數據庫,一套SQL查詢走天下。:-)
第一步:代碼里加入Maven依賴
- <dependency>
- <groupId>org.apache.calcite</groupId>
- <artifactId>calcite-file</artifactId>
- <version>1.21.0</version>
- </dependency>
通過這一步,你大概就看出來,咱們今天的爆改,主要依賴 Calcite,這個Apache的頂級項目。
來張官網截圖感受下:
簡單介紹的話,它是個數據庫查詢和優化的引擎,不負責具體的存儲。
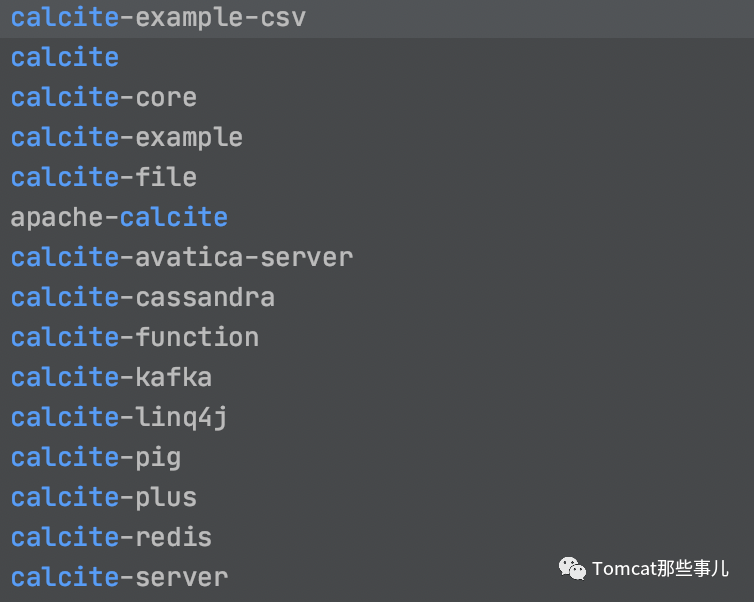
所以介紹里人家自己也說了,是你高性能數據庫的地基。許多的開源項目是基于它做的,比如大名鼎鼎的這些:

第二步:添加配置文件
配置的JSON 文件,一般是下面這樣子:
改造的配置文件,就像行軍打仗的地圖一樣,來告訴我們往哪走,這里的配置文件,對應到關系型數據庫里,就像是哪個庫,哪些表一樣。
- {
- "version": "1.0",
- "defaultSchema": "SALES",
- "schemas": [
- {
- "name": "SALES",
- "type": "custom",
- "factory": "org.apache.calcite.adapter.file.FileSchemaFactory",
- "operand": {
- "directory": "sales"
- }
- }
- ]
- }
其中schemas 表示都有哪些數據庫, defaultSchema 當然是默認數據庫了。factory 表示當前的數據文件,我們使用哪種Schema的形式進行解析。因為 Calcite 可以支持多種數據格式,通過這個圖你也能感受到幾分吧。
第三步:JDBC Style
通過 JDBC 的形式就能連接到我們自己的數據庫查詢了。代碼和一般的JDBC類似,區別只在于連接URL的寫法上,需要將配置文件的位置聲明一下。
- public class Demo {
- public static void main(String[] args) throws SQLException, ClassNotFoundException {
- Class.forName("org.apache.calcite.jdbc.Driver");
- Properties config = new Properties();
- config.put("model", "./src/main/resources/model.json");
- String sql = "select * from hello";
- try (Connection con = DriverManager.getConnection("jdbc:calcite:", config)) {
- try (Statement stmt = con.createStatement()) {
- ResultSet rs = stmt.executeQuery(sql);
- while (rs.next()) {
- System.out.println(rs.getString(2));
- }
- }
- }
- }
- }
其中SQL 語句,可以支持條件過濾,join 等所有的標準SQL。
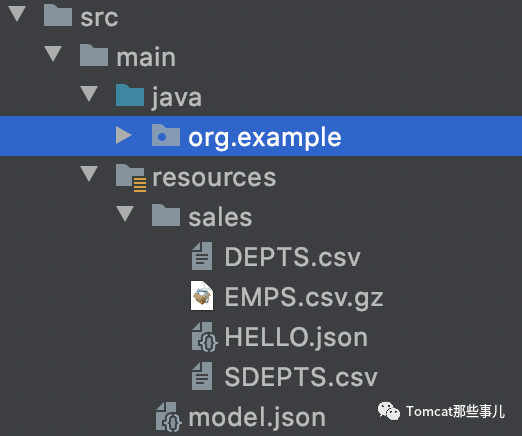
整體項目結構如下:
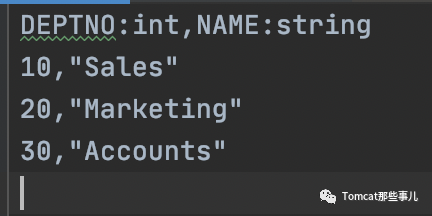
PS: 忘了提一句,對于CSV文件,第一行需要將各列列名和類型加上,表示數據庫表里定義的列。
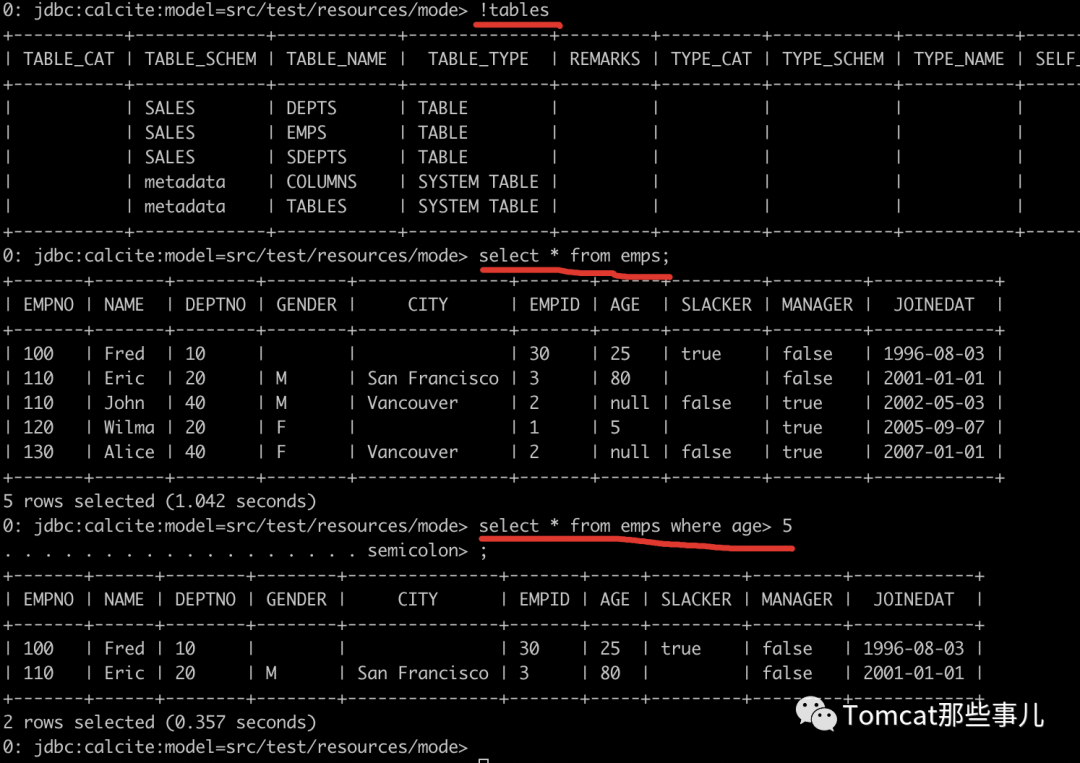
你說我很忙,不想啰哩啰嗦再寫個Java程序,辦法也還有。有個程序叫 sqlline,可以方便你在命令行里執行,一個腳本連接到對應的文件數據庫之后,就開始你飛一般的SQL表演吧。
- sqlline> !connect jdbc:calcite:model=src/main/resources/model.json admin admin
本文轉載自微信公眾號「Tomcat那些事兒」,可以通過以下二維碼關注。轉載本文請聯系Tomcat那些事兒公眾號。






















