首個ML生物醫(yī)藥大型數(shù)據(jù)集,3行代碼能運行
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯(lián)系出處。
AlphaFold2出世、強力抗生素Halicin的預測……
機器學習,已經在生物醫(yī)藥這一大領域貢獻了不少成果。
然而,這一領域,此前甚至還沒有大規(guī)模的機器學習數(shù)據(jù)集?
無論是查找、處理數(shù)據(jù),還是驗證模型效果,之前的研究,都只能在幾個小型數(shù)據(jù)集、或是已經被反復研究的幾個任務上進行。
這極大地降低了ML在生物醫(yī)藥領域的應用進展。
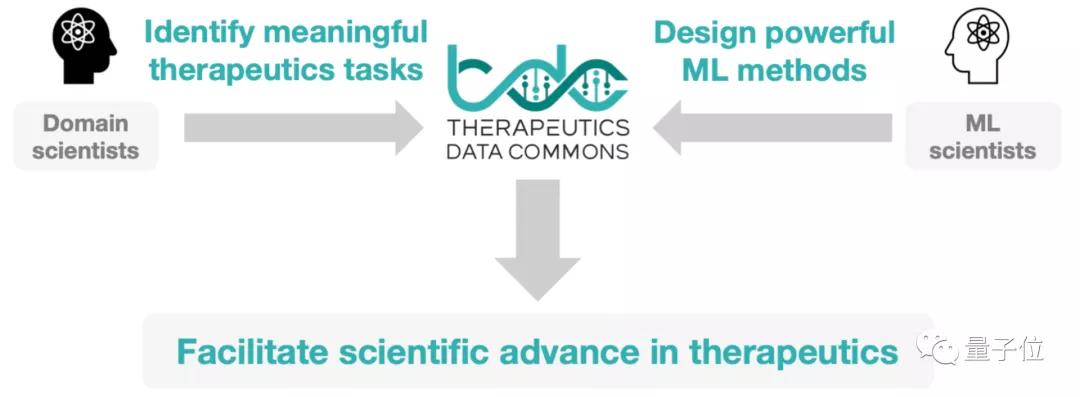
為此,一群來自哈佛、MIT、斯坦福等機構的研究人員,開發(fā)出了第一個ML領域的生物醫(yī)藥大型數(shù)據(jù)集TDC,還附帶最新的模型評估方法。
這是個什么樣的數(shù)據(jù)集?
TDC(Therapeutics Data Commons)數(shù)據(jù)集有三大特點:開源、大型、3行代碼搞定。

這一開源數(shù)據(jù)集,包含20+有意義的任務,和70多個高質量數(shù)據(jù)集。
涉及的范圍也非常廣,包含生物醫(yī)藥的各種研究方向,如靶蛋白發(fā)現(xiàn)、藥物動力學、安全性和藥物生產等。研究目標也不局限于小分子,還包括抗體、疫苗、miRNA等。
使用起來也非常簡便,只需要3行代碼,就能獲得ML-ready數(shù)據(jù)、使用TDC里面的各種功能。
TDC解決問題的3層架構
生物醫(yī)藥領域涵蓋各種任務,每個任務都需要不同的數(shù)據(jù)結構來進行處理。
為此,TDC提出了一個三層式階級架構Central Dogma (中心法則)。
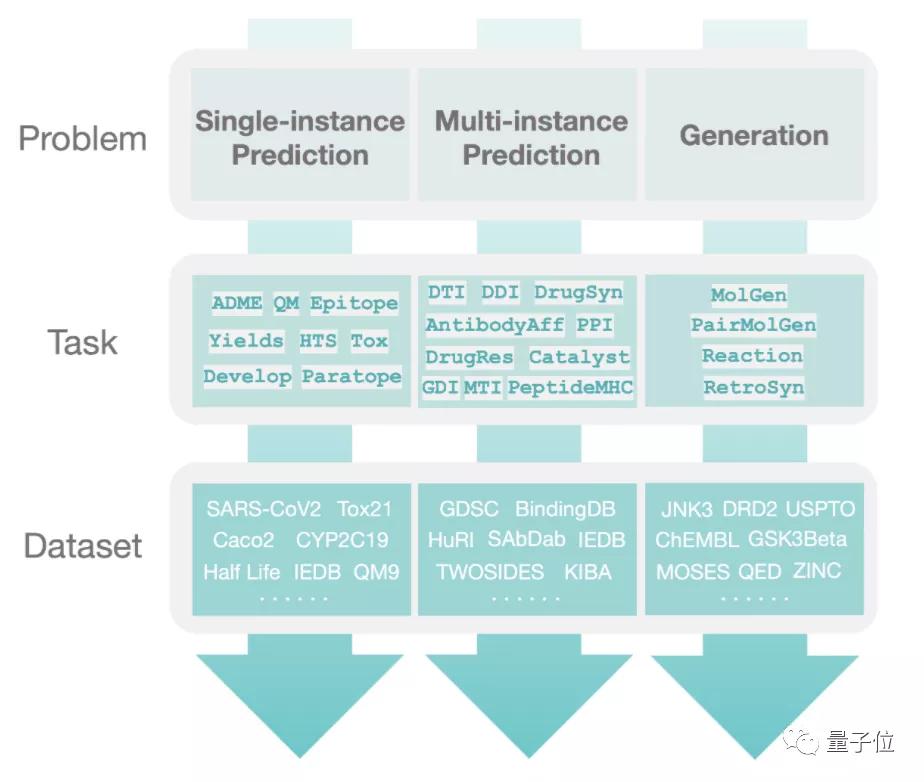
第一層,模型要解決哪類問題?
- 單實例預測(Single-instance prediction): 預測單個實體(比如分子,蛋白)的某些性質。
- 多實例預測(Multi-instance prediction): 預測多個實體之間的某些性質(比如反應類型)
- 生成(Generation): 已知一系列的實體,生成新的擁有某些性質的實體(比如優(yōu)化后的分子)
第二層,模型要學習什么樣的任務?
從生物醫(yī)藥角度來定義,任務包括設計新的抗體、識別個性化的組合療法、改善疾病診斷、尋找治療新疾病的方法。
第三層,模型用什么數(shù)據(jù)集來訓練?
根據(jù)任務類型,從TDC已有的數(shù)據(jù)集中挑選數(shù)據(jù),用于訓練模型。
根據(jù)這三層架構,就能非常輕松地找到需要用的數(shù)據(jù)集。
例如,想要檢索Z類問題中的學習任務Y,Y中需要用到數(shù)據(jù)集X,只需要三行代碼就能找到需要的結果。

TDC的數(shù)據(jù)集長啥樣
TDC所包含的數(shù)據(jù)集和任務,大多是沒有用機器學習進行過系統(tǒng)研究、但又極具潛力的應用方向。

例如,ADMET性質預測。其中,ADMET包含一系列藥物指標,用于評估某種藥物分子在口服后,能否安全有效地到達指定靶點。
此前,已有部分研究機構進行過ADMET預測,但都基于非公開數(shù)據(jù)。
TDC從各種小數(shù)據(jù)庫、期刊等公開資料中,收集整理了20多個藥廠目前在用的重要指標,并將所有數(shù)據(jù)進行了開源。準確預測這些指標,可以幫助藥企節(jié)省大量資源。
又例如,對藥物進行精準組合。
同種藥物,在不同個體間會產生不同影響,尤其是腫瘤方向的藥物。如果用機器學習,就能預測藥物在各種基因表達下的效果,目前TDC也已經包含了這樣的數(shù)據(jù)集。
此外,多藥物分子組合,往往比單藥物分子效果更好(drug synergy),如果能預測出兩個藥物分子的組合效應,能節(jié)省大量新藥研發(fā)的時間,TDC也已經處理了這樣的數(shù)據(jù)集。
還有生物藥(Biologics)方向的任務。
近幾年來,機器學習在小分子上已有許多應用,但在大分子生物藥上的應用不多。
TDC也包含了6個生物藥方面的任務,包括抗體和抗原的親和力預測、多肽和MHC的親和力預測、miRNA和靶點的反應預測等。
TDC的數(shù)據(jù)處理函數(shù)
除了核心數(shù)據(jù)集以外,TDC還能進行簡單的數(shù)據(jù)處理,主要包括以下四點:
- 模型評估:TDC提供了一個評估函數(shù)。只需3行代碼,就能評估TDC中的任務。
- 數(shù)據(jù)分割:TDC提供了一些訓練和測試集的分割方法,用于模擬實際生物醫(yī)藥場景,如scaffold split等。
- 數(shù)據(jù)處理:TDC提供可視化、標簽轉化,二值化等工具。
- 分子生成任務:目的是讓產生的新藥物分子具有更好的性質。TDC收集了20多個有意義的任務,同樣只需要3行代碼,就能運行。
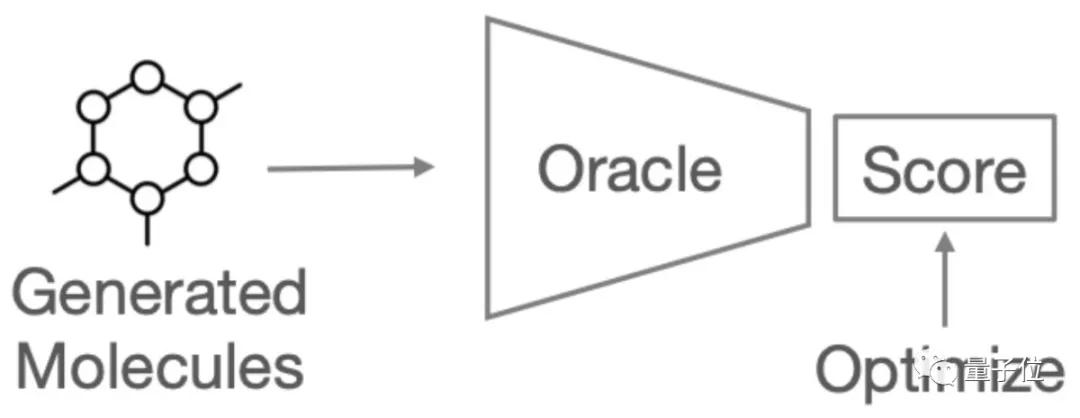
還可以刷新榜單排名
此外,TDC還提供各種類型的榜單(Leaderboard),給機器學習研究者對比模型預測的效果。
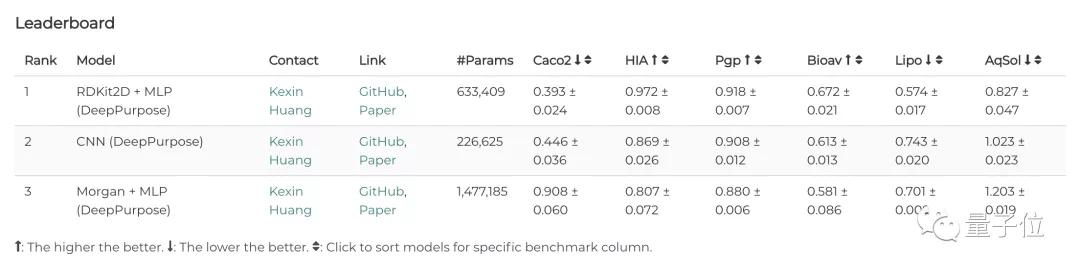
雖然TDC提供的每個數(shù)據(jù)集都能作為基準,但如果要真正評估一個機器學習模型,就要求其必須在一系列數(shù)據(jù)集和任務上達到更好的效果。
因此,TDC圍繞各種有意義的生物醫(yī)療問題,合并了各種子基準、形成基準組合。
所有的衡量標準和訓練、測試、分割的方式的設計目的,都是為了模擬實際生物醫(yī)藥的應用場景。
團隊簡介
TDC的開發(fā)和維護團隊,由多個高校和機構的研究人員共同組成。
主要的5位開發(fā)者,分別是來自哈佛的黃柯鑫、佐治亞理工學院的符天凡、MIT的高文昊、CMU的趙越、斯坦福的Yusuf Roohani。
此外,還有他們的5位導師,也在這次數(shù)據(jù)集開發(fā)中做出了不少貢獻。

目前,TDC數(shù)據(jù)集還在不斷地更新和完善中,作者黃柯鑫表示,還會不斷地更新如CRISPR、臨床試驗等方向的其他數(shù)據(jù)。
感興趣的同學,可以戳下方傳送門用起來了~
項目傳送門:
https://zitniklab.hms.harvard.edu/TDC/
參考鏈接:
https://zhuanlan.zhihu.com/p/340254116