優化器怎么選?一文教你選擇適合不同ML項目的優化器
為機器學習項目選擇合適的優化器不是一件簡單的事。
優化器是深度學習領域的重要組成模塊之一,執行深度學習任務時采用不同的優化器會產生截然不同的效果。這也是研究者們不遺余力「煉丹」的原因之一。常見的優化算法包括梯度下降(變體 BGD、SGD 和 MBGD)、Adagrad、Adam、Momentum 等,如此繁多的優化器應該如何做出抉擇呢?
不久前,Lightly-ai 的機器學習工程師 Philipp Wirth 撰寫了一篇指南,總結了計算機視覺、自然語言處理和機器學習領域普遍使用的流行優化器,并就如何選擇合適的優化器給出了建議。
具體而言,這篇文章提出基于以下 3 個問題來選擇優化器:
- 找到相關的研究論文,開始時使用相同的優化器;
- 查看表 1,并一一對照自己所用數據集的屬性以及不同優化器的優缺點;
- 根據可用資源調整優化器。
引言
為機器學習項目選擇好的優化器不是一項容易的任務。流行的深度學習庫(如 PyTorch 或 TensorFLow)提供了多種優化器選擇,它們各有優缺點。并且,選擇不合適的優化器可能會對機器學習項目產生很大的負面影響。這使得選擇優化器成為構建、測試和部署機器學習模型過程中的關鍵一環。
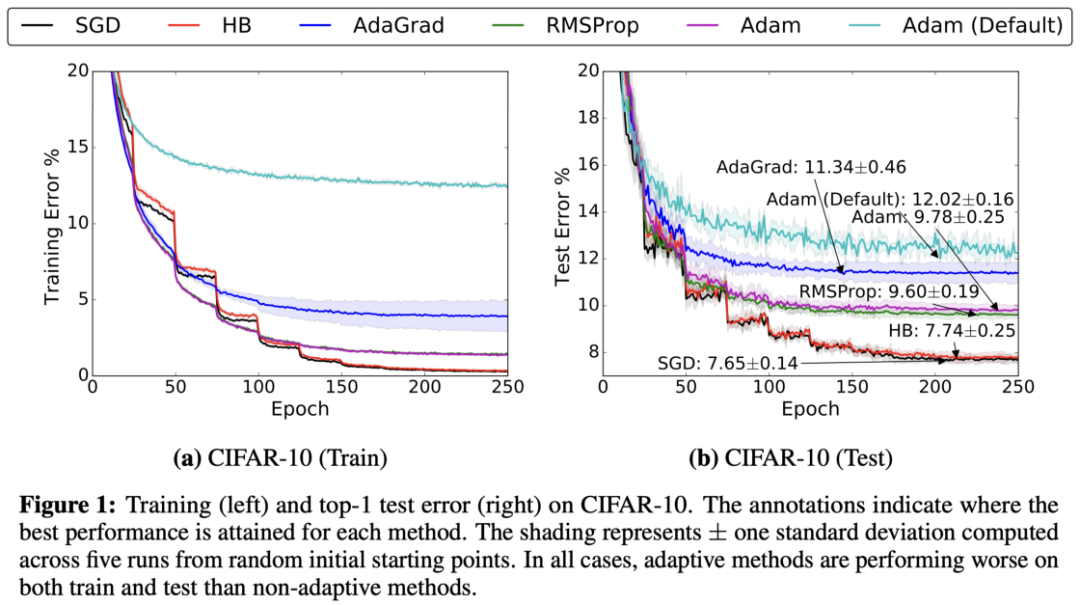
上圖顯示了由于優化器不同,模型性能可能會差異很大。
選擇優化器的問題在于沒有一個可以解決所有問題的單一優化器。實際上,優化器的性能高度依賴于設置。所以根本問題是:「哪種優化器最適合自身項目的特點?」
下文就圍繞這個問題分兩部分展開,第一部分簡要介紹常用的優化器,第二部分講述「三步選擇法」,幫助用戶為自己的機器學習項目挑選出最佳優化器。
常用優化器
深度學習中幾乎所有流行的優化器都是基于梯度下降。這意味著它們要反復估計給定損失函數 L 的斜率,并沿著相反的方向移動參數(因此向下移動至假定的全局最小值)。這種優化器最簡單的示例是自 20 世紀 50 年代以來一直使用的隨機梯度下降(SGD)算法。21 世紀前 10 年,自適應梯度法(如 AdaGrad 或 Adam)變得越來越流行。
但最近的趨勢表明,部分研究轉而使用先前的 SGD,而非自適應梯度法。此外,當前深度學習中的挑戰帶來了新的 SGD 變體,例如 LARS、LAMB[6][7]。例如谷歌研究院在其最近的論文中使用 LARS 訓練一種強大的自監督模型[8]。
本文中用 w 代表參數,g 代表梯度,α為每個優化器的全局學習率,t 代表時間步(time step)。
隨機梯度下降(SGD)算法
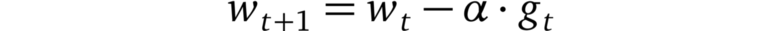
在隨機梯度下降算法(SGD)中,優化器基于小批量估計梯度下降最快的方向,并朝該方向邁出一步。由于步長固定,因此 SGD 可能很快停滯在平穩區(plateaus)或者局部最小值上。
帶動量的 SGD
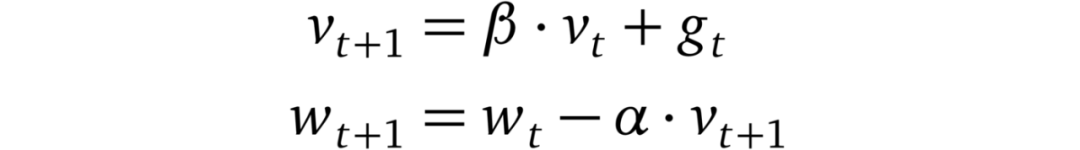
其中β<1。當帶有動量時,SGD 會在連續下降的方向上加速(這就是該方法被稱為「重球法」的原因)。這種加速有助于模型逃脫平穩區,使其不易陷入局部極小值。
AdaGrad
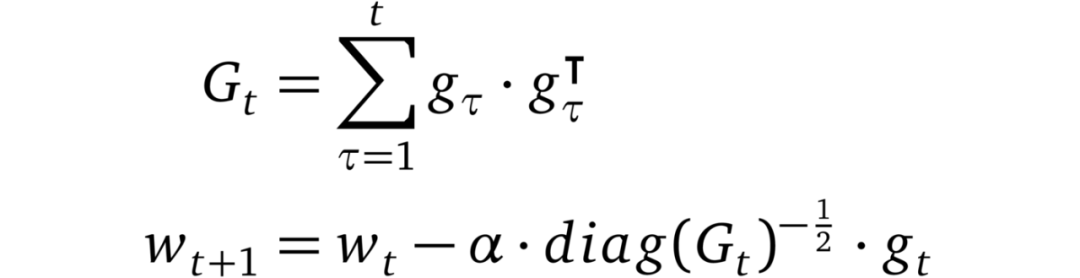
AdaGrad 是首批成功利用自適應學習率的方法之一。AdaGrad 基于平方梯度之和的倒數的平方根來縮放每個參數的學習率。該過程將稀疏梯度方向放大,以允許在這些方向上進行較大調整。結果是在具有稀疏特征的場景中,AdaGrad 能夠更快地收斂。
RMSprop
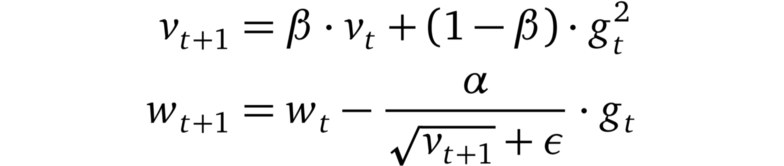
RMSprop 是一個未發布的優化器,但在最近幾年中已被過度使用。其理念類似于 AdaGrad,但是梯度的重新縮放不太積極:用平方梯度的移動均值替代平方梯度的總和。RMSprop 通常與動量一起使用,可以理解為 Rprop 對小批量設置的適應。
Adam
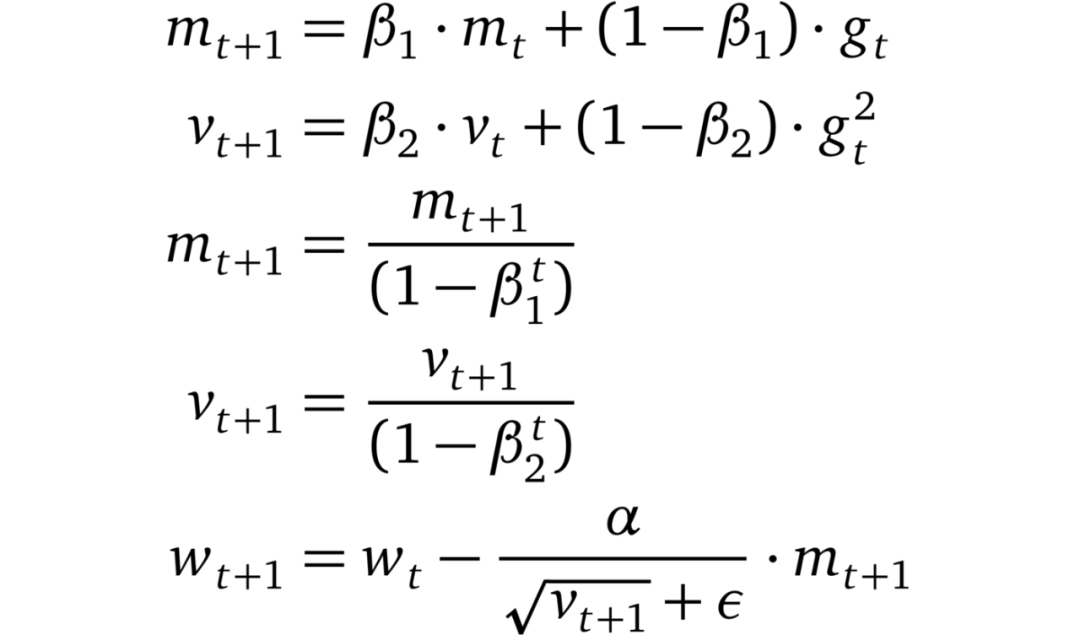
Adam 將 AdaGrad、RMSprop 和動量方法結合到一起。下一步的方向由梯度的移動平均值決定,步長大小由全局步長大小設置上限。此外,類似于 RMSprop,Adam 對梯度的每個維度進行重新縮放。Adam 和 RMSprop(或 AdaGrad)之間一個主要區別是對瞬時估計 m 和 v 的零偏差進行了矯正。Adam 以少量超參數微調就能獲得良好的性能著稱。
AdamW
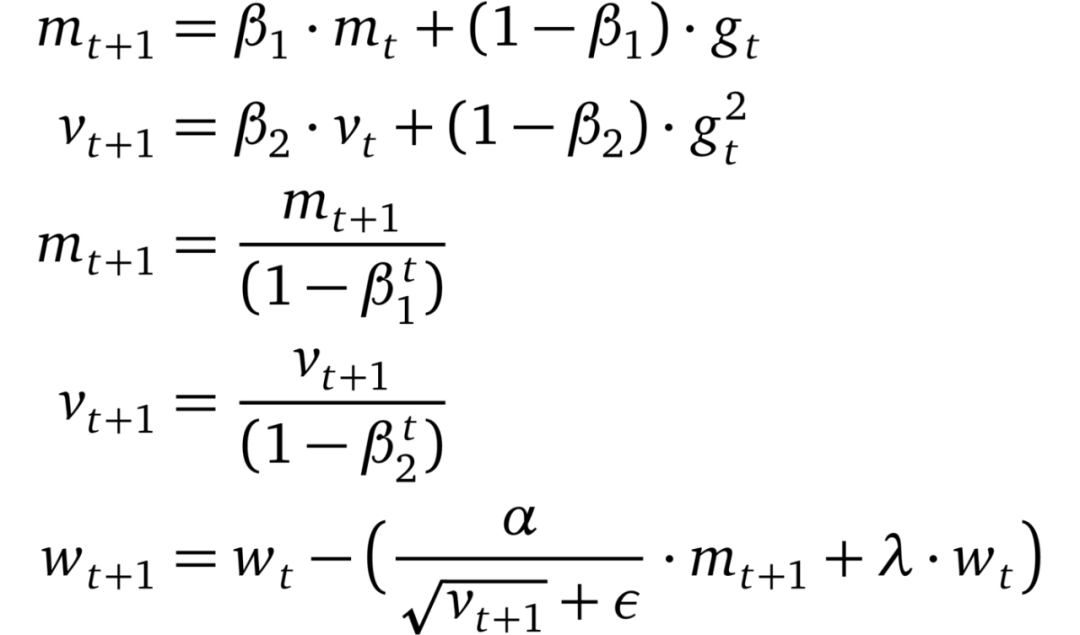
Loshchilov 和 Hutter 在自適應梯度方法中確定了 L2 正則化和權重下降的不等式,并假設這種不等式限制了 Adam 的性能。然后,他們提出將權重衰減與學習率解耦。實驗結果表明 AdamW 比 Adam(利用動量縮小與 SGD 的差距)有更好的泛化性能,并且對于 AdamW 而言,最優超參數的范圍更廣。
LARS
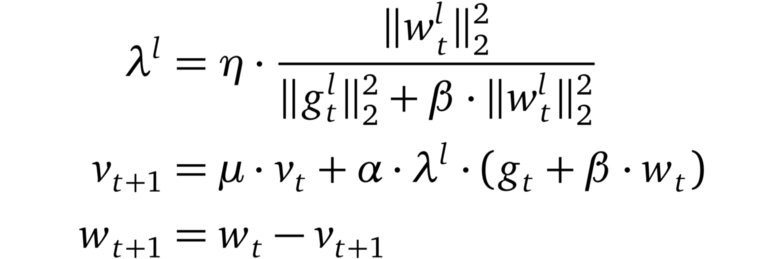
LARS 是 SGD 的有動量擴展,可以適應每層的學習率。LARS 最近在研究界引起了關注。這是由于可用數據的穩定增長,機器學習的分布式訓練也變得越來越流行。這使得批處理大小開始增長,但又會導致訓練變得不穩定。有研究者(Yang et al)認為這些不穩定性源于某些層的梯度標準和權重標準之間的不平衡。因此他們提出了一種優化器,該優化器基于「信任」參數η<1 和該層梯度的反范數來重新調整每層的學習率。
如何選擇合適的優化器?
如上所述,為機器學習問題選擇合適的優化器可能非常困難。更具體地說,沒有萬能的解決方案,只能根據特定問題選擇合適的優化器。但在選擇優化其之前應該問自己以下 3 個問題:
- 類似的數據集和任務的 SOTA 結果是什么?
- 使用了哪些優化器?
- 為什么使用這些優化器?
如果您使用的是新型機器學習方法,那么可能存在一篇或多篇涵蓋類似問題或處理了類似數據的優秀論文。通常,論文作者會進行廣泛的交叉驗證,并且給出最成功的配置。讀者可以嘗試理解他們選擇那些優化器的原因。
例如:假設你想訓練生成對抗網絡(GAN),以對一組圖像執行超分辨率。經過一番研究后,你偶然發現了一篇論文 [12],研究人員使用 Adam 優化器解決了完全相同的問題。威爾遜等人[2] 認為訓練 GAN 并不應該重點關注優化問題,并且 Adam 可能非常適合這種情況。所以在這種情況下,Adam 是不錯的優化器選擇。
此外,你的數據集中是否存在可以發揮某些優化器優勢的特性?如果是這樣,則需要考慮優化器的選擇問題。
下表 1 概述了幾種優化器的優缺點。讀者可以嘗試找到與數據集特征、訓練設置和項目目標相匹配的優化器。某些優化器在具有稀疏特征的數據上表現出色,而有一些將模型應用于先前未見過的數據時可能會表現更好。一些優化器在大批處理量下可以很好地工作,而另一些優化器會在泛化不佳的情況下收斂到極小的最小值。
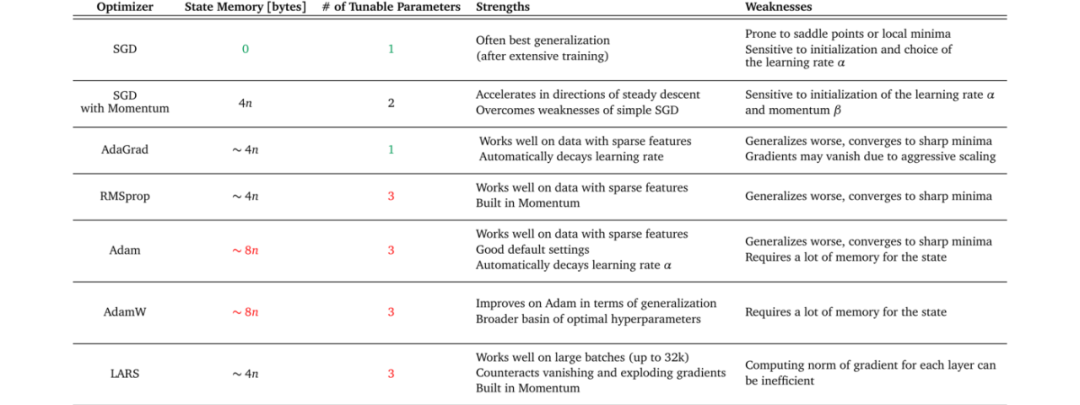
舉例而言:如果你需要將用戶給出的反饋分類成正面和負面反饋,考慮使用詞袋模型(bag-of-words)作為機器學習模型的輸入特征。由于這些特征可能非常稀疏,所以決定采用自適應梯度方法。但是具體選擇哪一種優化器呢?參考上表 1,你會發現 AdaGrad 具有自適應梯度方法中最少的可調參數。在項目時間有限的情況下,可能就會選擇 AdaGrad 作為優化器。
最后需要考慮的問題:該項目有哪些資源?項目可用資源也會影響優化器的選擇。計算限制或內存限制以及項目時間范圍都會影響優化器的選擇范圍。
如上表 1 所示,可以看到每個優化器有不同的內存要求和可調參數數量。此信息可以幫助你估計項目設置是否可以支持優化器的所需資源。
舉例而言:你正在業余時間進行一個項目,想在家用計算機的圖像數據集上訓練一個自監督的模型(如 SimCLR)。對于 SimCLR 之類的模型,性能會隨著批處理大小的增加而提高。因此你想盡可能多地節省內存,以便進行大批量的訓練。選擇沒有動量的簡單隨機梯度下降作為優化器,因為與其他優化器相比,它需要最少的額外內存來存儲狀態。