













如何定位哪些SQL產(chǎn)生了大量的Redo日志
本文轉(zhuǎn)載自微信公眾號「DBA閑思雜想錄」,作者瀟湘隱者 。轉(zhuǎn)載本文請聯(lián)系DBA閑思雜想錄公眾號。
在ORACLE數(shù)據(jù)庫的管理、維護過程中,偶爾會遇到歸檔日志暴增的情況,也就是說一些SQL語句產(chǎn)生了大量的redo log,那么如何跟蹤、定位哪些SQL語句生成了大量的redo log日志呢?下面這篇文章結(jié)合實際案例和官方文檔“How to identify the causes of High Redo Generation (文檔 ID 2265722.1)”來驗證判斷一下。
首先,我們需要定位、判斷那個時間段的日志突然暴增了,注意,有些時間段生成了大量的redo log是正常業(yè)務行為,有可能每天這個時間段都有大量歸檔日志生成,例如,有大量作業(yè)在這個時間段集中運行。而要分析突然、異常的大量redo log生成情況,就必須有數(shù)據(jù)分析對比,找到redo log大量產(chǎn)生的時間段,縮小分析的范圍是第一步。合理的縮小范圍能夠方便快速準確定位問題SQL。下面SQL語句分別統(tǒng)計了redo log的切換次數(shù)的相關(guān)數(shù)據(jù)指標。這個可以間接判斷那個時間段產(chǎn)生了大量歸檔日志。
- /******統(tǒng)計每天redo log的切換次數(shù)匯總,以及與平均次數(shù)的對比*****/
- WITH T AS
- (
- SELECT TO_CHAR(FIRST_TIME, 'YYYY-MM-DD') AS LOG_GEN_DAY,
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME, 'YYYY-MM-DD'),
- TO_CHAR(FIRST_TIME, 'YYYY-MM-DD'), 1, 0))
- , '999') AS "LOG_SWITCH_NUM"
- FROM V$LOG_HISTORY
- WHERE FIRST_TIME < TRUNC(SYSDATE) --排除當前這一天
- GROUP BY TO_CHAR(FIRST_TIME, 'YYYY-MM-DD')
- )
- SELECT T.LOG_GEN_DAY
- , T.LOG_SWITCH_NUM
- , M.AVG_LOG_SWITCH_NUM
- , (T.LOG_SWITCH_NUM-M.AVG_LOG_SWITCH_NUM) AS DIFF_SWITCH_NUM
- FROM T CROSS JOIN
- (
- SELECT TO_CHAR(AVG(T.LOG_SWITCH_NUM),'999') AS AVG_LOG_SWITCH_NUM
- FROM T
- ) M
- ORDER BY T.LOG_GEN_DAY DESC;
- SELECT TO_CHAR(FIRST_TIME,'YYYY-MM-DD') DAY,
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'00',1,0)),'999') "00",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'01',1,0)),'999') "01",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'02',1,0)),'999') "02",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'03',1,0)),'999') "03",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'04',1,0)),'999') "04",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'05',1,0)),'999') "05",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'06',1,0)),'999') "06",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'07',1,0)),'999') "07",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'08',1,0)),'999') "08",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'09',1,0)),'999') "09",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'10',1,0)),'999') "10",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'11',1,0)),'999') "11",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'12',1,0)),'999') "12",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'13',1,0)),'999') "13",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'14',1,0)),'999') "14",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'15',1,0)),'999') "15",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'16',1,0)),'999') "16",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'17',1,0)),'999') "17",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'18',1,0)),'999') "18",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'19',1,0)),'999') "19",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'20',1,0)),'999') "20",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'21',1,0)),'999') "21",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'22',1,0)),'999') "22",
- TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'23',1,0)),'999') "23"
- FROM V$LOG_HISTORY
- GROUP BY TO_CHAR(FIRST_TIME,'YYYY-MM-DD')
- ORDER BY 1 DESC;
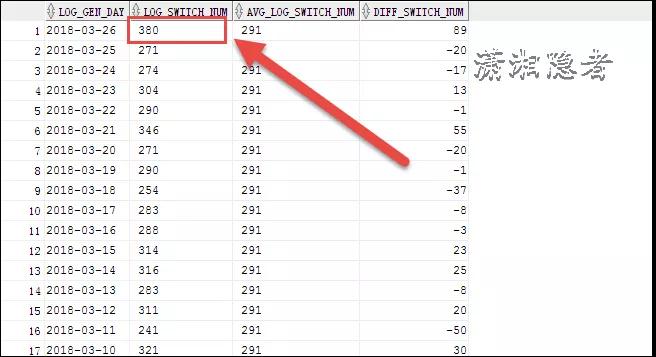
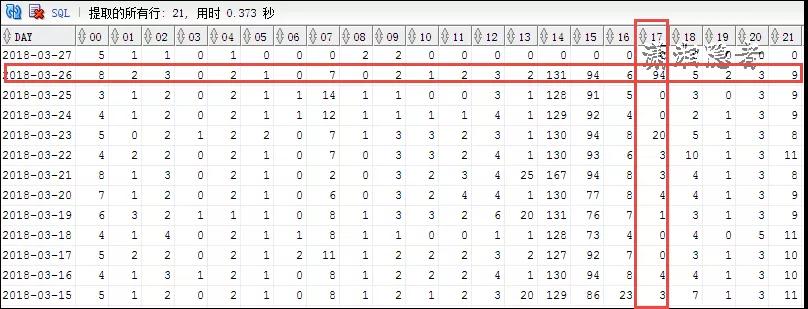
如下案例所示,2018-03-26日有一個歸檔日志暴增的情況,我們可以橫向、縱向?qū)Ρ确治觯缓笈卸ㄔ?7點到18點這段時間出現(xiàn)異常,這個時間段與往常對比,生成了大量的redo log。
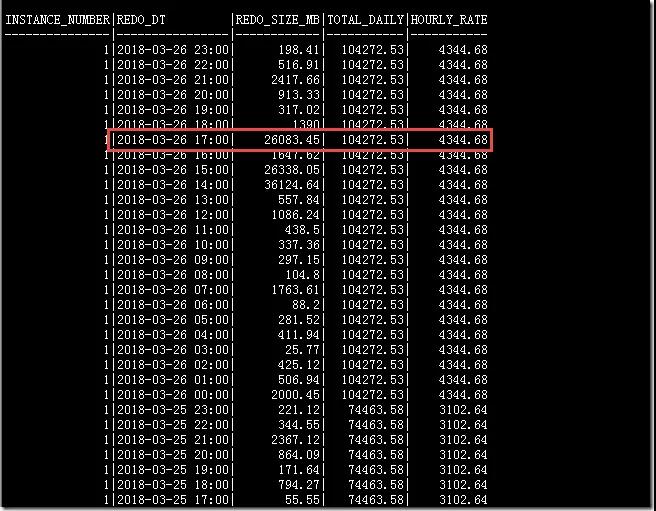
這里分享一個非常不錯的分析redo log 歷史信息的SQL
- ------------------------------------------------------------------------------------------------
- REM Author: Riyaj Shamsudeen @OraInternals, LLC
- REM www.orainternals.com
- REM
- REM Functionality: This script is to print redo size rates in a RAC claster
- REM **************
- REM
- REM Source : AWR tables
- REM
- REM Exectution type: Execute from sqlplus or any other tool.
- REM
- REM Parameters: No parameters. Uses Last snapshot and the one prior snap
- REM No implied or explicit warranty
- REM
- REM Please send me an email to rshamsud@orainternals.com, if you enhance this script :-)
- REM This is a open Source code and it is free to use and modify.
- REM Version 1.20
- REM
- ------------------------------------------------------------------------------------------------
- set colsep '|'
- set lines 220
- alter session set nls_date_format='YYYY-MM-DD HH24:MI';
- set pagesize 10000
- with redo_data as (
- SELECT instance_number,
- to_date(to_char(redo_date,'DD-MON-YY-HH24:MI'), 'DD-MON-YY-HH24:MI') redo_dt,
- trunc(redo_size/(1024 * 1024),2) redo_size_mb
- FROM (
- SELECT dbid, instance_number, redo_date, redo_size , startup_time FROM (
- SELECT sysst.dbid,sysst.instance_number, begin_interval_time redo_date, startup_time,
- VALUE -
- lag (VALUE) OVER
- ( PARTITION BY sysst.dbid, sysst.instance_number, startup_time
- ORDER BY begin_interval_time ,sysst.instance_number
- ) redo_size
- FROM sys.wrh$_sysstat sysst , DBA_HIST_SNAPSHOT snaps
- WHERE sysst.stat_id =
- ( SELECT stat_id FROM sys.wrh$_stat_name WHERE stat_name='redo size' )
- AND snaps.snap_id = sysst.snap_id
- AND snaps.dbid =sysst.dbid
- AND sysst.instance_number = snaps.instance_number
- AND snaps.begin_interval_time> sysdate-30
- ORDER BY snaps.snap_id )
- )
- )
- select instance_number, redo_dt, redo_size_mb,
- sum (redo_size_mb) over (partition by trunc(redo_dt)) total_daily,
- trunc(sum (redo_size_mb) over (partition by trunc(redo_dt))/24,2) hourly_rate
- from redo_Data
- order by redo_dt, instance_number
- /
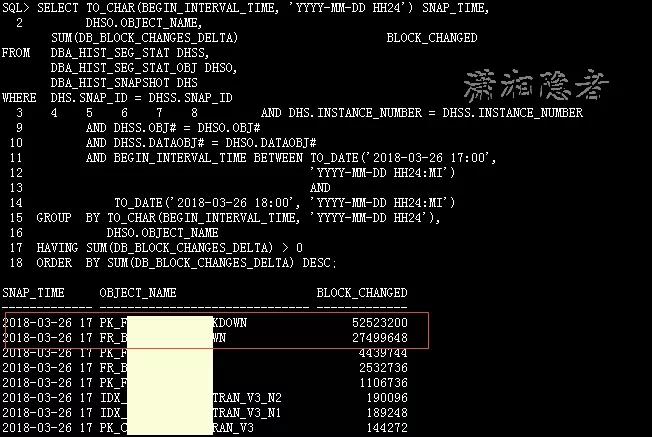
分析到這個階段,我們還只獲取了那個時間段歸檔日志異常(歸檔日志暴增),那么要如何定位到相關(guān)的SQL語句呢?我們可以用下面SQL來定位:在這個時間段,哪些對象有大量數(shù)據(jù)塊變化情況。如下所示,這兩個對象(當然,對象有可能是表或索引,這個案例中,這兩個對象其實是同一個表和其主鍵索引)有大量的數(shù)據(jù)塊修改情況。基本上我們可以判斷是涉及這個對象的DML語句生成了大量的redo log, 當然有可能有些場景會比較復雜,不是那么容易定位。
- SELECT TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24') SNAP_TIME,
- DHSO.OBJECT_NAME,
- SUM(DB_BLOCK_CHANGES_DELTA) BLOCK_CHANGED
- FROM DBA_HIST_SEG_STAT DHSS,
- DBA_HIST_SEG_STAT_OBJ DHSO,
- DBA_HIST_SNAPSHOT DHS
- WHERE DHS.SNAP_ID = DHSS.SNAP_ID
- AND DHS.INSTANCE_NUMBER = DHSS.INSTANCE_NUMBER
- AND DHSS.OBJ# = DHSO.OBJ#
- AND DHSS.DATAOBJ# = DHSO.DATAOBJ#
- AND BEGIN_INTERVAL_TIME BETWEEN TO_DATE('2018-03-26 17:00',
- 'YYYY-MM-DD HH24:MI')
- AND
- TO_DATE('2018-03-26 18:00', 'YYYY-MM-DD HH24:MI')
- GROUP BY TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24'),
- DHSO.OBJECT_NAME
- HAVING SUM(DB_BLOCK_CHANGES_DELTA) > 0
- ORDER BY SUM(DB_BLOCK_CHANGES_DELTA) DESC;
此時,我們可以生成這個時間段的AWR報告,那些產(chǎn)生大量redo log的SQL一般是來自TOP Gets、TOP Execution中某個DML SQL語句或一些DML SQL語句,結(jié)合上面SQL定位到的對象和下面相關(guān)SQL語句,基本上就可以判斷就是下面這兩個SQL產(chǎn)生了大量的redo log。(第一個SQL是調(diào)用包,包里面有對這個表做大量的DELETE、INSERT操作)
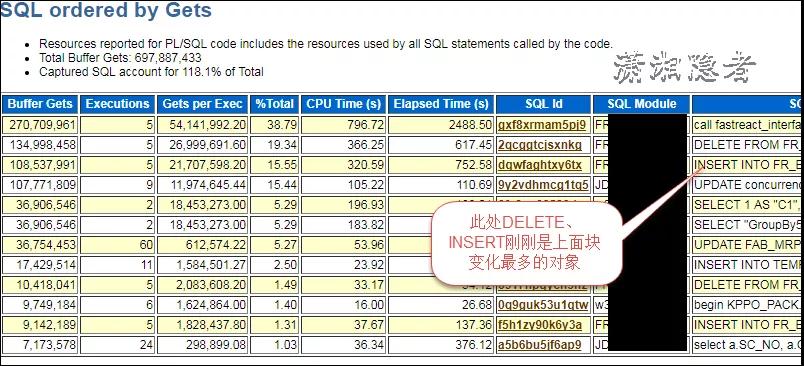
如果你此時還不能完全斷定,也可以使用下面SQL來輔佐判斷那些SQL生成了大量的redo log。在這個案例中, 上面AWR報告中發(fā)現(xiàn)的SQL語句和下面SQL捕獲的SQL基本一致。那么可以進一步佐證。
注意,該SQL語句執(zhí)行較慢,執(zhí)行時需要修改相關(guān)條件:時間和具體段對象。
- SELECT TO_CHAR(BEGIN_INTERVAL_TIME,'YYYY_MM_DD HH24') WHEN,
- DBMS_LOB.SUBSTR(SQL_TEXT,4000,1) SQL,
- DHSS.INSTANCE_NUMBER INST_ID,
- DHSS.SQL_ID,
- EXECUTIONS_DELTA EXEC_DELTA,
- ROWS_PROCESSED_DELTA ROWS_PROC_DELTA
- FROM DBA_HIST_SQLSTAT DHSS,
- DBA_HIST_SNAPSHOT DHS,
- DBA_HIST_SQLTEXT DHST
- WHERE UPPER(DHST.SQL_TEXT) LIKE '%<segment_name>%' --此處用具體的段對象替換
- AND LTRIM(UPPER(DHST.SQL_TEXT)) NOT LIKE 'SELECT%'
- AND DHSS.SNAP_ID=DHS.SNAP_ID
- AND DHSS.INSTANCE_NUMBER=DHS.INSTANCE_NUMBER
- AND DHSS.SQL_ID=DHST.SQL_ID
- AND BEGIN_INTERVAL_TIME BETWEEN TO_DATE('2018-03-26 17:00','YYYY-MM-DD HH24:MI')
- AND TO_DATE('2018-03-26 18:00','YYYY-MM-DD HH24:MI')
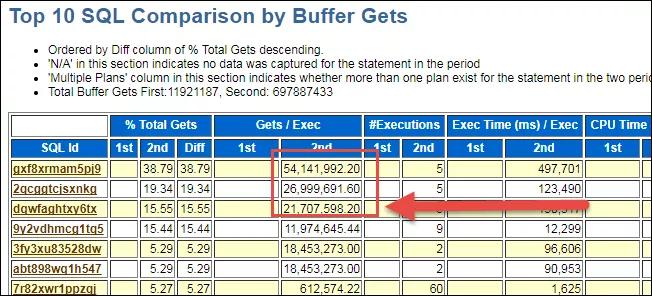
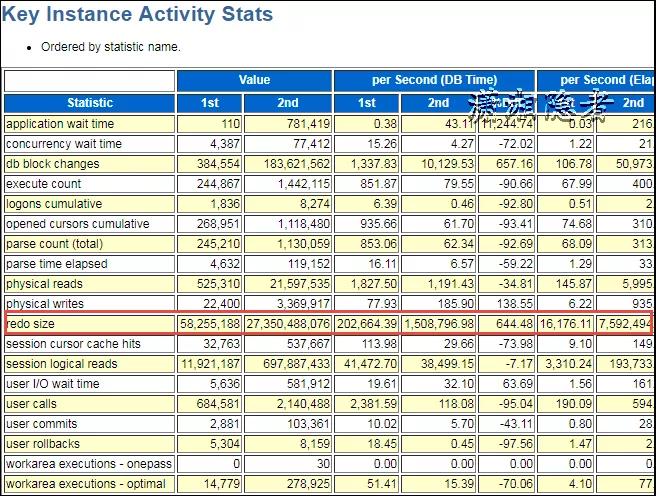
其實上面分析已經(jīng)基本完全定位到SQL語句,剩下的就是和開發(fā)人員或Support人員溝通、了解是正常業(yè)務邏輯變更還是異常行為。如果需要進一步挖掘深入,我們可以使用日志挖掘工具Log Miner深入分析。在此不做展開分析。其實個人在判斷分析時生成了正常時段和出現(xiàn)問題時段的AWR對比報告(WORKLOAD REPOSITORY COMPARE PERIOD REPORT),如下所示,其中一些信息也可以供分析、對比參考。可以為復雜場景做對比分析(因為復雜場景,僅僅通過最上面的AWR報告可能無法準確定位SQL)
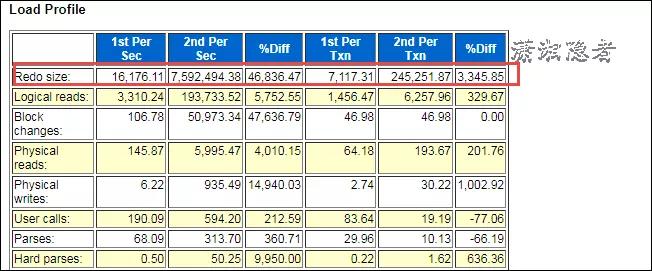
此次截圖,沒有截取相關(guān)SQL,其實就是最上面分析的SQL語句,如果復雜場景下,非常有用。
參考資料:
How to identify the causes of High Redo Generation (文檔 ID 2265722.1)



















