愛奇藝機器學習平臺的建設實踐
在建設機器學習平臺之前,愛奇藝已經擁有比較成熟的深度學習平臺Javis,但是Javis面向的用戶比較高階、專業的算法工程師,需要通過提交代碼到專用計算集群上運行計算,使用門檻比較高。
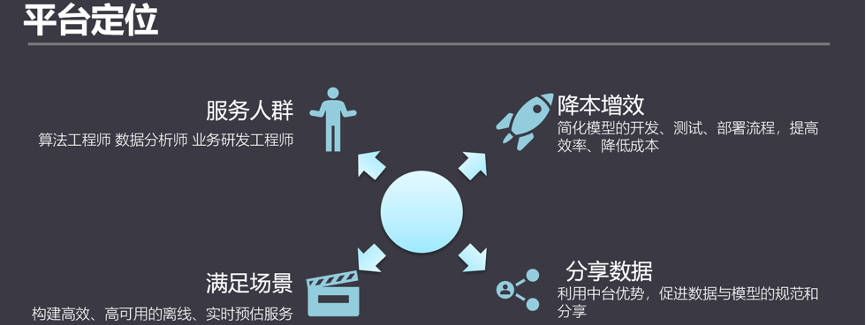
另外,算法除了深度學習以外,機器學習,數據挖掘、數據分析等領域。對于有很多規模較小的業務,沒有相對應的平臺支持這些非深度學習,需要獨立開發算法和工程平臺來支撐落地。

這就是常說的造煙囪,每個業務要自己搭建算法平臺,這很容易出現兩個問題:一個是在算法方面,很多業務不是基于算法為核心打造業務,使用機器學習或許僅僅是用于輔助或優化業務,所以可能并沒有很專業的算法人員對模型或者算法有比較深入的理解;另外一個問題,雖然有算法人員,但是對算法的落地其實還是要做一些工程方面的東西,對于不同業務來說屬于重復造輪子。
此外對于愛奇藝的數據中臺戰略來說,智能服務是數據中臺的必要功能。
從以上三點來看,建設機器學習平臺就有了比較清晰的定位。
機器學習平臺的服務的人群包括算法工程師、數據分析師,也包括業務研發工程師,我們希望通過構建高效的離線、實時預測服務,降低用戶使用機器學習的成本,提高接入算法的效率,利用數據中臺的優勢促進數據和模型的規范和分享。
發展歷程
簡單介紹一下愛奇藝機器學習平臺的發展歷程。
截止目前主要是經歷了三個大版本,第一版也是基于業務造煙囪的階段。這一版由于圍繞具體業務搭建服務,所以整個架構里面算法部分很少,但是在這一版本我們通過Spark ML調度算法的核心系統,實現了算法的異步分布式調度。上線后對算法接入的效率提升非常明顯。
在第一版積累的技術經驗基礎上,我們發現當前通用機器學習平臺的需求,于是迭代了第二版,實現面向通用需求的機器學習平臺。

第二版里最顯著的特征,是在用戶層增加了可視化前端,可以通過拖拉拽的方式讓用戶組建自己的機器學習流程。用戶通過自由拼搭算法組件,解決了通用化后百花齊放的流程需求。
另外一個重點是把調度服務獨立出來。其中,實驗調度子系統對任務狀態進行監控,負責任務的調度,通過對任務心跳匯總,隨時能了解任務集群全局的狀態,當任務執行節點出現異常中斷時,能第一時間重試或重新分發到其他節點,極大保證了服務的穩定性。
任務執行引擎是任務運行的核心。任務執行引擎接收實驗調度服務推送來的任務,根據任務配置的內容從模型池獲取模型資源、從數據管理子系統讀寫數據、執行腳本。由于任務執行引擎不綁定任何具體的算法框架,實現算法執行能輕松跨越不同算法框架和平臺。
通過消息日志監控,自動收集調度各個算法和平臺產生的日志信息和終端信息,并通過配置關鍵字的方式提取有用的信息和數據,在前端聚合展示,或實現某些功能的即時圖表功能。
算法模型池也作為獨立服務進行管理,專門負責離線和實時預測獲取模型和同步模型。

系統舍棄了v1中的通過Europa調度Spark集群任務,以及自己維護的定時任務,接入愛奇藝的大數據平臺Babel和定時任務調度服務平臺Gear。接入這兩個平臺以后一來實現了和數據中臺的打通,二來實現了離線服務。
在算法的框架上,由于把執行引擎分離出來了,所以可以很輕松的加入更多的框架,在第二版里面除了SparkML里面常見的一些算法以外,還擴展了常用的像XGBoost和圖類的算法。
3.0的主要目標是完善功能版圖,主要實現了在線預測的服務。針對用戶提出的一些提高效率的需求,也提供了自動調參、增加參數服務器擴展了模型數據量的支持。另外由于用戶有需求通過別的平臺接入機器學習平臺,所以也提供了API服務。
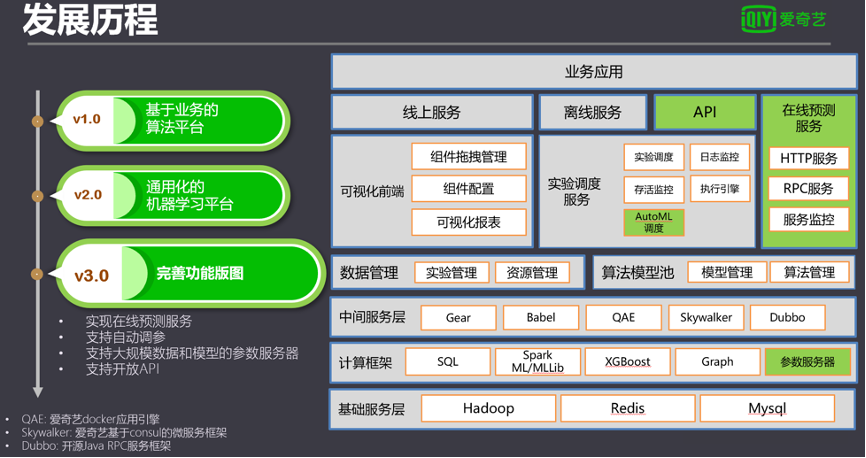
到目前為止,已經形成了一站式平臺,基本覆蓋了機器學習全流程。通過平臺操作,用戶可以從特征工程到模型訓練、模型評估、在線和離線預測實現了整套機器學習的流程。通過把機器學習流程的數據源和數據目的接入整個大數據開發平臺,完成了一整套的閉環。

系統經驗
分享在實際過程中的一些經驗。
自動調參
當用戶在具體做一個模型調優的時候,如果模型的參數設置不對的話,很影響模型的準確率。模型的參數也并不相同,像LR、線性回歸4個參數,多的像XGBoost暴露出17個參數,雖然不是每個參數都參與調參,但是總是會遇到一些排列組合。如果人工調參,參數組少則幾十,多則上百種組合。比如XGBoost,使用人力來調參基本不可想象。

目前的機器學習框架,普遍自帶調參功能,比如Spark ML,但是調參能力相當有限,因為只能做隨機和全組合(窮舉搜索)。使用Spark自帶的調參方法,如果用戶沒有一點直覺經驗排除調參區間,那就需要拼計算資源或者人品。
算法框架自帶的調參系統還有另一個局限性,就是無法跨平臺復用調參算法。因此我們設計一個系統層面的調參框架,可以調用Spark、python等不同算法框架,也可以不局限在算法框架語言限制內開發自己的調參算法。
我們的自動調參的系統從流程上來看比較簡單。系統把調參分為多輪次迭代進行。傳統調參算法比如隨機調參、網格搜索調參只有一輪,高級的算法會有多輪調參,通過前一輪調參的評估結果適當縮小調參區間,最終把參數收斂到一個最優值。
系統讀取用戶設置的參數區間后,根據用戶的需求把區間劃分為多個子區間,并在每個子區間隨機采樣參數作為首次調參的組合,并通過任務分發服務下發給執行引擎,調度對應的算法框架訓練和評估。訓練任務結束后,執行引擎把評估結果返回給調參服務。
收集到當前輪次所有評估結果后,調參服務調起算法計算下一輪的調參空間,并調整下一輪的取樣個數,再次下發給執行引擎測試,循環往復,直到達到最大輪次限制或收斂程度。

我們可以把整個調參流程看做是一個大型的模型訓練過程,通過結果反饋不斷找到極值的過程。從這種思路出發,可以加入很多適用的算法作為調參算法。
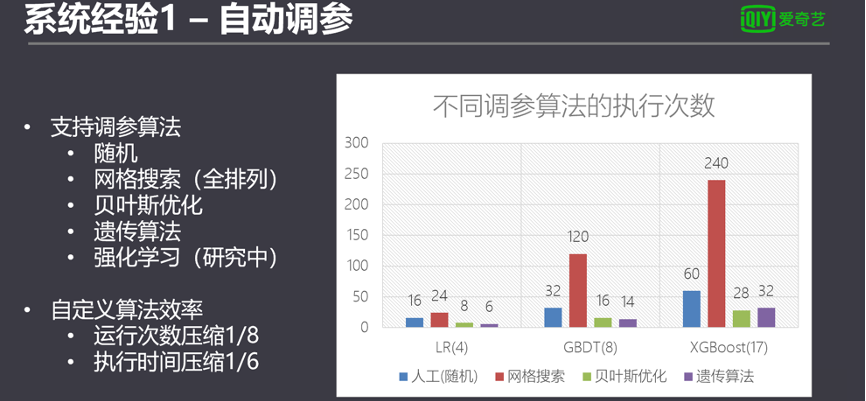
目前機器學習平臺除了支持隨機算法和網格搜索的算法,也實現了貝葉斯優化以及自研的遺傳算法。測試發現自研的算法調參效率遠優于傳統默認的算法。
數據規模的支持
系統初期只支持SparkML框架,正常訓練萬級別的數據集幾分鐘能訓練完成,但是當用戶數據集只有幾十到幾百數量級時,任務也需要跑幾分鐘,相對于單機的python秒級訓練完成的時間來說相當慢。其中一個原因是任務提交到Spark集群上需要等待資源分配。真正訓練時間短,但其他的準備時間也讓用戶覺得很慢。所以我們在后續版本把python的單機的引擎也引用進來。當數據量小的時候用戶可以直接在單機上做這種操作。
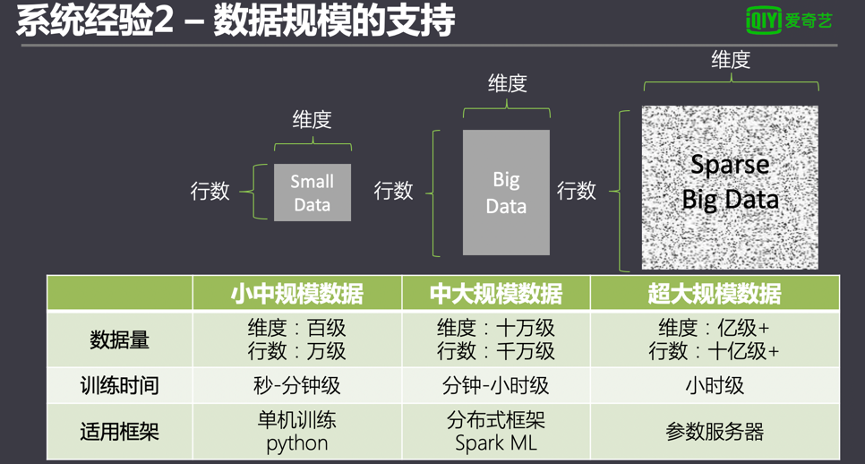
另一方面,在訓練億級以上的數據量時傳統的SparkML訓練相當慢甚至崩潰失敗。這是因為Spark對超大規模的模型的訓練并不擅長,Spark訓練模型分多輪迭代,每一輪需要所有的執行器的任務做完后才匯總參數,根據木桶原理,整個Spark任務會受到最慢的worker運行時間影響。
另外,所有的執行器會通過廣播的方式對參數進行共享,對于大規模參數量的模型來說相當占網絡帶寬,也會導致系統使用率效果非常低。
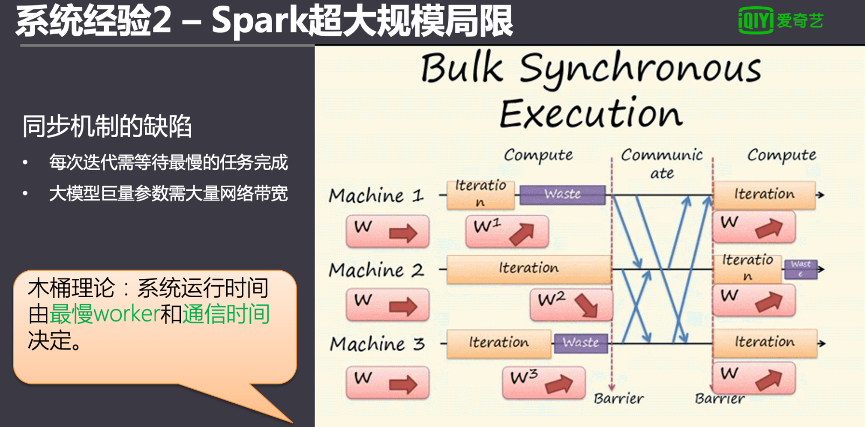
解決方案是通過參數服務器的方式解決,參數服務器本身原理上對分布式的訓練進行了一些改良,并不是等所有的執行器跑完,等一部分跑完超過一個預值強行終止了。為了提高整個集群的效率犧牲了一些部分的收斂的速度,另外取消了廣播機制來傳遞參數,把參數放在獨立的叫做參數服務器里面,通過讀取,這樣子也節省了網絡的消耗。

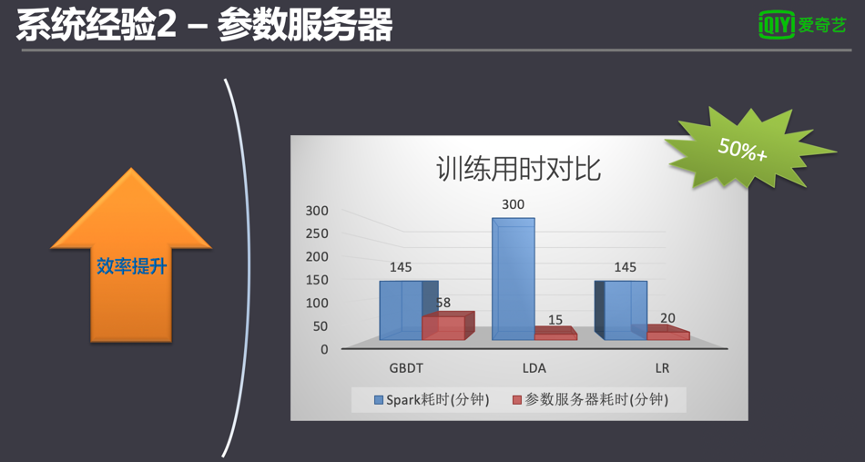
愛奇藝的機器學習平臺在設計之初就支持跨算法框架調度。我們調研了多種開源的參數服務器,最終集成了騰訊的Angel參數服務器,并對一些典型模型做了測試。測試證明,在訓練億級以上規模的模型時,參數服務器的訓練效率相對Spark有明顯提升50%以上的速度。
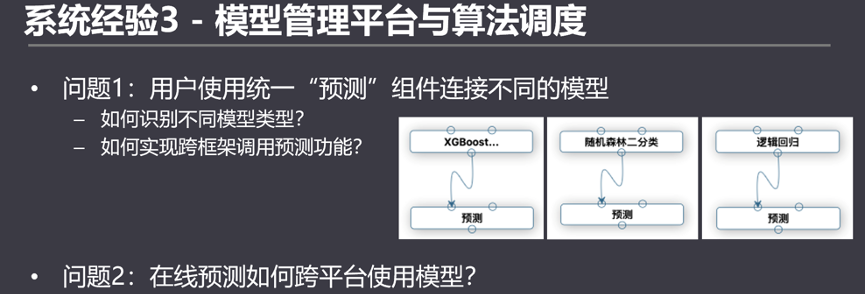
模型的管理平臺和算法調度
不論是Sklearn,還是Spark ML的模型預測,從代碼角度來看,預測功能是不同模型內部的方法。不存在通用的預測方法兼容所有的模型。對于開發人員自己寫代碼的時候沒問題,但如果做一個通用化的平臺,需要考慮統一的預測組件來處理所有的模型預測,并有一定的擴展性,通過一個預測組件兼容不同算法框架的模型。
和預測組件類似的另一個問題是,不同算法模型,甚至跨框架的模型,如何都能統一部署到在線預測的服務中去?
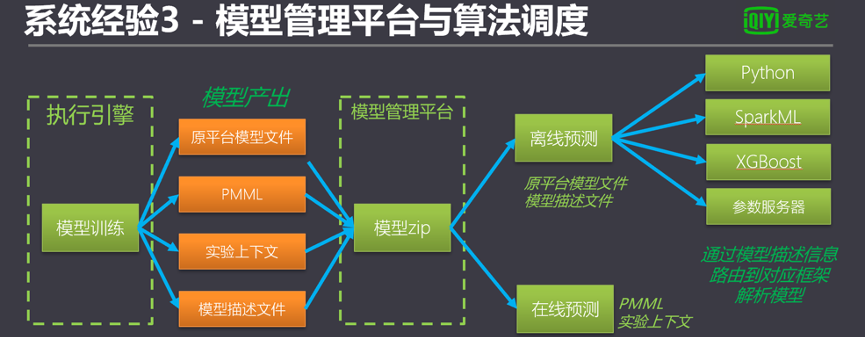
以上2個問題可以通過自定義模型文件解決。模型訓練完后,在默認模型文件輸出的同時,也輸出自定義文件和PMML文件。PMML是一套有標準的模型定義語言,可用于跨平臺的讀取模型,適合用于離線訓練+在線預測的場景。另外,在自定義文件里可以輸出更多平臺有用的信息,比如模型評估分數、模型類型、模型訓練的相關表和字段名、模型參數、訓練上下文等等。
在模型接入預測組件時,預測組件讀取自定義文件,獲取到模型的所在框架和模型類型,并通過對應的模型框架加載模型文件即可。
在在線預測中,通過讀取到訓練的上下文,可以把模型訓練上游所需的預處理過程一并加載到在線預測過程中,減輕用戶單獨預處理過程的負擔。
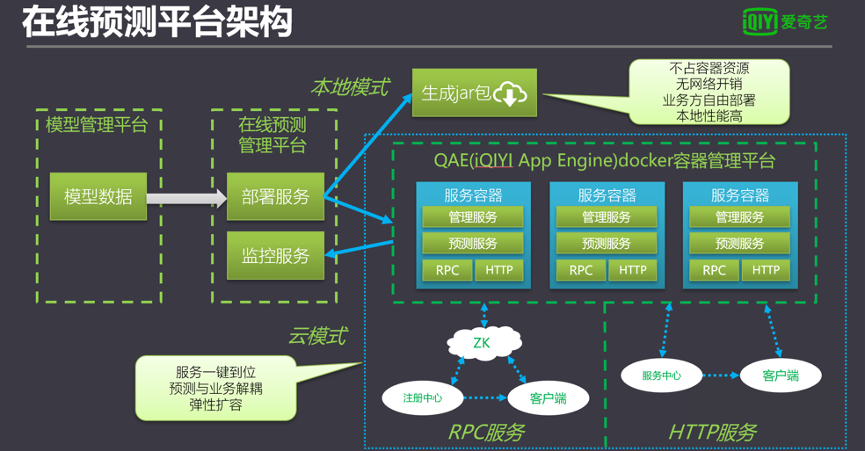
在線預測系統搭建
在線預測系統對不同用戶的需求場景提供不同的調用方式。
本地模式是在線預測平臺把模型信息整體自動封裝在服務jar包中,提供給用戶輕量級調用;云模式是在線預測服務平臺結合Docker服務,生成一組計算集群。云模式支持HTTP服務與RPC服務。在HTTP服務中,系統通過Consul服務申請動態域名,并通過自動發現服務關聯Docker服務。用戶僅需通過服務提供的域名訪問,無需了解后端部署流程。
RPC服務是基于Dubbo實現。模型預測服務被Dubbo封裝后通過Docker連接ZooKeeper實現服務發現。用戶端僅需通過客戶端連接指定的連接字即可訪問服務。
離線預測平臺是基于流程的發布,在線預測則是基于模型和模型上下文信息進行發布。模型管理平臺中使用推模式和拉模式兩種方式部署在線服務。拉模式為用戶主動更新服務的模式;而推模式為模型在模型管理平臺中更新后被動更新的方式。通過兩種方式的結合,在線服務覆蓋所有模型更新場景。
案例介紹
反作弊業務是一個獨立的業務系統,管理反作弊相關業務邏輯和業務數據。反作弊平臺定義和構建了不同反作弊識別過濾場景,并自動拆解成工作流在數據中臺中具體運維。涉及到算法相關的流程,通過數據中臺轉到機器學習平臺處理,處理后的結果也會回到數據中臺。
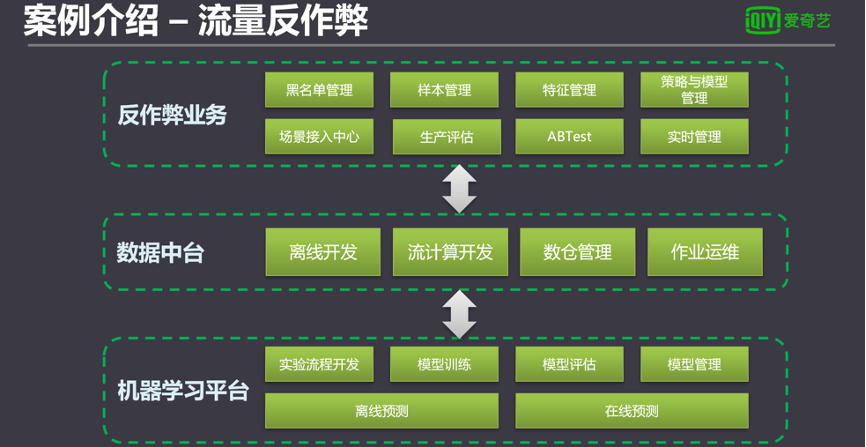
下圖中包括了流量反作弊所有的場景和相關算法,包括常見的監督算法,監督算法,黑白樣本,然后聚類算法,異常檢測算法,此外,還有基于團伙的同類的算法,和一些深度學習的算法。

每天大概能過濾大概千萬級以上的日志,在線預測峰值的時候是要超過能達到萬級的KPS,所有擁有這么一個平臺,效率提升大致在80%以上。