數(shù)據(jù)分析工具篇-HQL原理及優(yōu)化
HQL是數(shù)據(jù)分析過程中的必備技能,隨著數(shù)據(jù)量增加,這一技能越來越重要,熟練應用的同時會帶來效率的問題,動輒十幾億的數(shù)據(jù)量如果處理不完善的話有可能導致一個作業(yè)運行幾個小時,更嚴重的還有可能因占用過多資源而引發(fā)生產(chǎn)問題,所以HQL優(yōu)化就變得非常重要,本文我們就深入HQL的原理中,探索HQL優(yōu)化的方法和邏輯。
group by的計算原理
代碼為:
- SELECT uid, SUM(COUNT) FROM logs GROUP BY uid;

可以看到,group by本身不是全局變量,任務會被分到各個map中進行分組,然后再在reduce中聚合。
默認設置了hive.map.aggr=true,所以會在mapper端先group by一次,最后再把結果merge起來,為了減少reducer處理的數(shù)據(jù)量。注意看explain的mode是不一樣的。mapper是hash,reducer是mergepartial。如果把hive.map.aggr=false,那將groupby放到reducer才做,他的mode是complete。
優(yōu)化點:
Group by主要是面對數(shù)據(jù)傾斜的問題。
很多聚合操作可以現(xiàn)在map端進行,最后在Reduce端完成結果輸出:
- Set hive.map.aggr = true; # 是否在Map端進行聚合,默認為true;
- Set hive.groupby.mapaggr.checkinterval = 1000000; # 在Map端進行聚合操作的條目數(shù)目;
當使用Group by有數(shù)據(jù)傾斜的時候進行負載均衡:
- Set hive.groupby.skewindata = true; # hive自動進行負載均衡;
策略就是把MR任務拆分成兩個MR Job:第一個先做預匯總,第二個再做最終匯總;
第一個Job:
Map輸出結果集中緩存到maptask中,每個Reduce做部分聚合操作,并輸出結果,這樣處理的結果是相同Group by Key有可能被分到不同的reduce中,從而達到負載均衡的目的;
第二個Job:
根據(jù)第一階段處理的數(shù)據(jù)結果按照group by key分布到reduce中,保證相同的group by key分布到同一個reduce中,最后完成最終的聚合操作。
join的優(yōu)化原理
代碼為:
- SELECT a.id,a.dept,b.age FROM a join b ON (a.id = b.id);

1)Map階段:
讀取源表的數(shù)據(jù),Map輸出時候以Join on條件中的列為key,如果Join有多個關聯(lián)鍵,則以這些關聯(lián)鍵的組合作為key;
Map輸出的value為join之后所關心的(select或者where中需要用到的)列;同時在value中還會包含表的Tag信息,用于標明此value對應哪個表;
按照key進行排序;
2)Shuffle階段:
根據(jù)key的值進行hash,并將key/value按照hash值推送至不同的reduce中,這樣確保兩個表中相同的key位于同一個reduce中。
3)Reduce階段:
根據(jù)key的值完成join操作,期間通過Tag來識別不同表中的數(shù)據(jù)。
在多表join關聯(lián)時:
如果 Join 的 key 相同,不管有多少個表,都會合并為一個 Map-Reduce,例如:
- SELECT pv.pageid, u.age
- FROM page_view p
- JOIN user u
- ON (pv.userid = u.userid)
- JOIN newuser x
- ON (u.userid = x.userid);
如果 Join 的 key不同,Map-Reduce 的任務數(shù)目和 Join 操作的數(shù)目是對應的,例如:
- SELECT pv.pageid, u.age
- FROM page_view p
- JOIN user u
- ON (pv.userid = u.userid)
- JOIN newuser x
- on (u.age = x.age);
優(yōu)化點:
1)應該將條目少的表/子查詢放在 Join 操作符的左邊。
2)我們知道文件數(shù)目小,容易在文件存儲端造成瓶頸,給 HDFS 帶來壓力,影響處理效率。對此,可以通過合并Map和Reduce的結果文件來消除這樣的影響。用于設置合并屬性的參數(shù)有:
- 合并Map輸出文件:hive.merge.mapfiles=true(默認值為真)
- 合并Reduce端輸出文件:hive.merge.mapredfiles=false(默認值為假)
- 合并文件的大小:hive.merge.size.per.task=256*1000*1000(默認值為 256000000)
3) Common join即普通的join,性能較差,因為涉及到了shuffle的過程(Hadoop/spark開發(fā)的過程中,有一個原則:能避免不使用shuffle就不使用shuffle),可以轉化成map join。
- hive.auto.convert.join=true;# 表示將運算轉化成map join方式
使用的前提條件是需要的數(shù)據(jù)在 Map 的過程中可以訪問到。
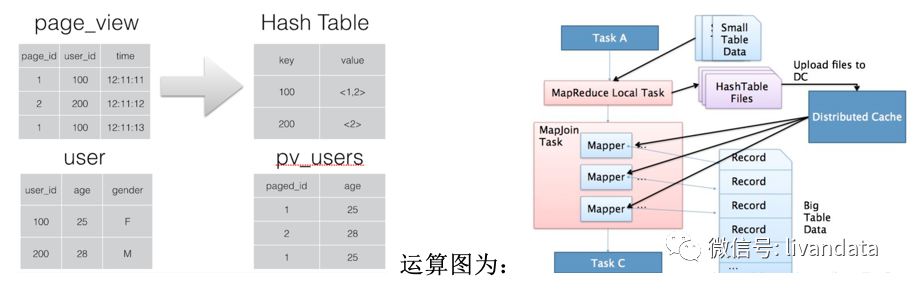
1)啟動Task A:Task A去啟動一個MapReduce的local task;通過該local task把small table data的數(shù)據(jù)讀取進來;之后會生成一個HashTable Files;之后將該文件加載到分布式緩存(Distributed Cache)中來;
2)啟動MapJoin Task:去讀大表的數(shù)據(jù),每讀一個就會去和Distributed Cache中的數(shù)據(jù)去關聯(lián)一次,關聯(lián)上后進行輸出。
整個階段,沒有reduce 和 shuffle,問題在于如果小表過大,可能會出現(xiàn)OOM。
Union與union all優(yōu)化原理
union將多個結果集合并為一個結果集,結果集去重。代碼為:
- select id,name
- from t1
- union
- select id,name
- from t2
- union
- select id,name
- from t3
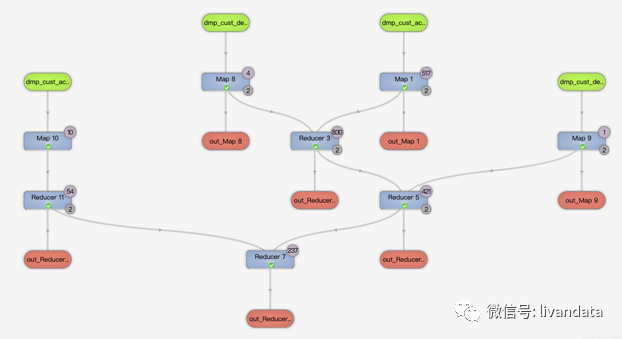
對應的運行邏輯為:
union all將多個結果集合并為一個結果集,結果集不去重。使用時多與group by結合使用,代碼為:
- select all.id, all.name
- from(
- select id,name
- from t1
- union all
- select id,name
- from t2
- union all
- select id,name
- from t3
- )all
- group by all.id ,all.name
對應的運行邏輯為:
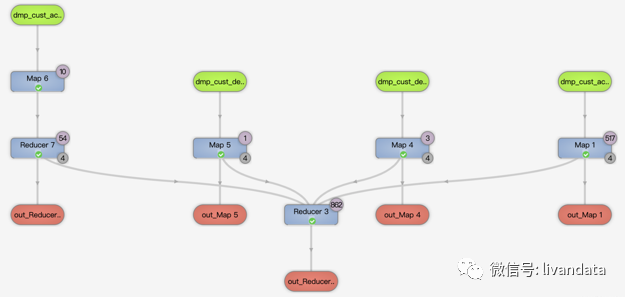
從上面的兩個邏輯圖可以看到,第二種寫法性能要好。union寫法每兩份數(shù)據(jù)都要先合并去重一次,再和另一份數(shù)據(jù)合并去重,會產(chǎn)生較多次的reduce。第二種寫法直接將所有數(shù)據(jù)合并再一次性去重。
對union all的操作除了與group by結合使用還有一些細節(jié)需要注意:
1)對 union all 優(yōu)化只局限于非嵌套查詢。
原代碼:job有3個:
- SELECT *
- FROM
- (
- SELECT *
- FROM t1
- GROUP BY c1,c2,c3
- UNION ALL
- SELECT *
- FROM t2
- GROUP BY c1,c2,c3
- )t3
- GROUP BY c1,c2,c3
這樣的結構是不對的,應該修改為:job有1個:
- SELECT *
- FROM
- (
- SELECT *
- FROM t1
- UNION ALL
- SELECT *
- FROM t2
- )t3
- GROUP BY c1,c2,c3
這樣的修改可以減少job數(shù)量,進而提高效率。
2)語句中出現(xiàn)count(distinct …)結構時:
原代碼為:
- SELECT *
- FROM
- (
- SELECT * FROM t1
- UNION ALL
- SELECT c1,c2,c3,COUNT(DISTINCT c4)
- FROM t2 GROUP BY c1,c2,c3
- ) t3
- GROUP BY c1,c2,c3;
修改為:(采用臨時表消滅 COUNT(DISTINCT)作業(yè)不但能解決傾斜問題,還能有效減少jobs)。
- INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3;
- SELECT c1,c2,c3,SUM(income),SUM(uv) FROM
- (
- SELECT c1,c2,c3,income,0 AS uv FROM t1
- UNION ALL
- SELECT c1,c2,c3,0 AS income,1 AS uv FROM t2
- ) t3
- GROUP BY c1,c2,c3;
Order by的優(yōu)化原理
如果指定了hive.mapred.mode=strict(默認值是nonstrict),這時就必須指定limit來限制輸出條數(shù),原因是:所有的數(shù)據(jù)都會在同一個reducer端進行,數(shù)據(jù)量大的情況下可能不能出結果,那么在這樣的嚴格模式下,必須指定輸出的條數(shù)。
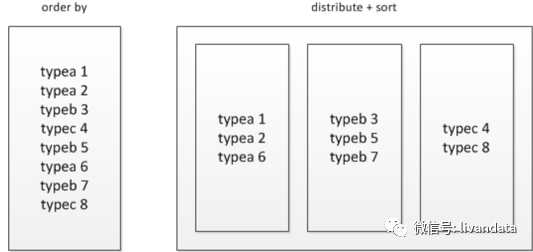
所以數(shù)據(jù)量大的時候能不用order by就不用,可以使用sort by結合distribute by來進行實現(xiàn)。
sort by是局部排序;
distribute by是控制map怎么劃分reducer。
- cluster by=distribute by + sort by
被distribute by設定的字段為KEY,數(shù)據(jù)會被HASH分發(fā)到不同的reducer機器上,然后sort by會對同一個reducer機器上的每組數(shù)據(jù)進行局部排序。
例如:
- select mid, money, name
- from store
- cluster by mid
- select mid, money, name
- from store
- distribute by mid
- sort by mid
如果需要獲得與上面的中語句一樣的效果:
- select mid, money, name
- from store
- cluster by mid
- sort by money
注意被cluster by指定的列只能是降序,不能指定asc和desc。
不過即使是先distribute by然后sort by這樣的操作,如果某個分組數(shù)據(jù)太大也會超出reduce節(jié)點的存儲限制,常常會出現(xiàn)137內存溢出的錯誤,對大數(shù)據(jù)量的排序都是應該避免的。
Count(distinct …)優(yōu)化
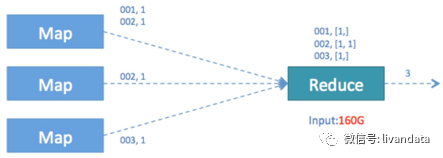
如下的sql會存在性能問題:
- SELECT COUNT( DISTINCT id ) FROM TABLE_NAME WHERE ...;
主要原因是COUNT這種“全聚合(full aggregates)”計算時,它會忽略用戶指定的Reduce Task數(shù),而強制使用1,這會導致最終Map的全部輸出由單個的ReduceTask處理。這唯一的Reduce Task需要Shuffle大量的數(shù)據(jù),并且進行排序聚合等處理,這使得它成為整個作業(yè)的IO和運算瓶頸。
圖形如下:
為了避免這一結構,我們采用嵌套的方式優(yōu)化sql:
- SELECT COUNT(*)
- FROM (
- SELECT DISTINCT id FROM TABLE_NAME WHERE …
- ) t;
這一結構會將任務切分成兩個,第一個任務借用多個reduce實現(xiàn)distinct去重并進行初步count計算,然后再將計算結果輸出到第二個任務中進行計數(shù)。
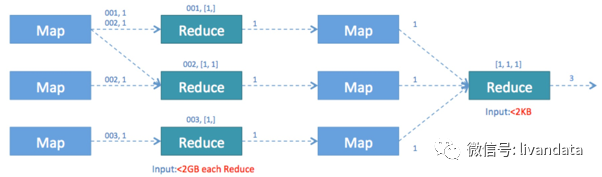
另外,再有的方法就是用group by()嵌套代替count(distinct a)。
如果能用group by的就盡量使用group by,因為group by性能比distinct更好。
HiveSQL細節(jié)優(yōu)化
1) 設置合理的mapreduce的task數(shù),能有效提升性能。
- set mapred.reduce.tasks=n
2) 在sql中or的用法需要加括號,否則可能引起無分區(qū)限制:
- Select x
- from t
- where ds=d1
- and (province=’gd’ or province=’gx’)
3) 對運算結果進行壓縮:
- set hive.exec.compress.output=true;
4) 減少生成的mapreduce步驟:
4.1)使用CASE…WHEN…代替子查詢;
4.2)盡量盡早地過濾數(shù)據(jù),減少每個階段的數(shù)據(jù)量,對于分區(qū)表要加分區(qū),同時只選擇需要使用到的字段;
5) 在map階段讀取數(shù)據(jù)前,F(xiàn)ileInputFormat會將輸入文件分割成split。split的個數(shù)決定了map的個數(shù)。
- mapreduce.input.fileinputformat.split.minsize 默認值 0
- mapreduce.input.fileinputformat.split.maxsize 默認值 Integer.MAX_VALUE
- dfs.blockSize 默認值 128M,所以在默認情況下 map的數(shù)量=block數(shù)
6) 常用的參數(shù):
- hive.exec.reducers.bytes.per.reducer=1000000;
設置每個reduce處理的數(shù)據(jù)量,reduce個數(shù)=map端輸出數(shù)據(jù)總量/參數(shù);
- set hive.mapred.mode=nonstrict;
- set hive.exec.dynamic.partition=true;
- set hive.exec.dynamic.partition.mode=nonstrict;
- set mapred.job.name=p_${v_date};
- set mapred.job.priority=HIGH;
- set hive.groupby.skewindata=true;
- set hive.merge.mapredfiles=true;
- set hive.exec.compress.output=true;
- set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
- set mapred.output.compression.type=BLOCK;
- set mapreduce.map.memory.mb=4096;
- set mapreduce.reduce.memory.mb=4096;
- set hive.hadoop.supports.splittable.combineinputformat=true;
- set mapred.max.split.size=16000000;
- set mapred.min.split.size.per.node=16000000;
- set mapred.min.split.size.per.rack=16000000;
- set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- set hive.exec.reducers.bytes.per.reducer=128000000;
7)設置map個數(shù):
map個數(shù)和來源表文件壓縮格式有關,.gz格式的壓縮文件無法切分,每個文件會生成一個map;
- set hive.hadoop.supports.splittable.combineinputformat=true; 只有這個參數(shù)打開,下面的3個參數(shù)才能生效
- set mapred.max.split.size=16000000; 每個map負載;
- set mapred.min.split.size.per.node=100000000; 每個節(jié)點map的最小負載,這個值必須小于set mapred.max.split.size的值;
- set mapred.min.split.size.per.rack=100000000; 每個機架map的最小負載;
- set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;