MIT博士生、北大校友,利用自監(jiān)督算法,解決了數(shù)據(jù)集中這一常見(jiàn)的“難題”
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
訓(xùn)練模型時(shí),你是否也遭遇過(guò)這樣的“尷尬”時(shí)刻:
好不容易找到了自己想要的數(shù)據(jù)集,結(jié)果點(diǎn)進(jìn)去一看,大部分樣本都是一類(lèi)物體。(例如,數(shù)據(jù)集標(biāo)簽「動(dòng)物」,結(jié)果80%的樣本都是「貓」)
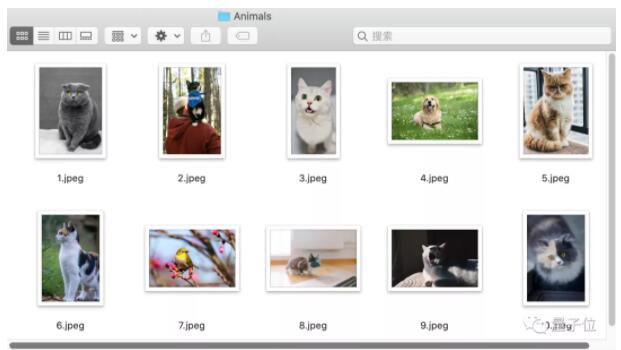
用上面這個(gè)數(shù)據(jù)集訓(xùn)練的動(dòng)物檢測(cè)模型,可能只能識(shí)別「貓」。
這類(lèi)數(shù)據(jù)不均衡(某一標(biāo)簽數(shù)量太多,其余標(biāo)簽數(shù)量太少)的問(wèn)題,在機(jī)器學(xué)習(xí)中被稱(chēng)為“長(zhǎng)尾問(wèn)題”。
這個(gè)問(wèn)題導(dǎo)致,數(shù)據(jù)集中(尤其是大型數(shù)據(jù)集)樣本數(shù)量少的物體,泛化效果會(huì)非常差。
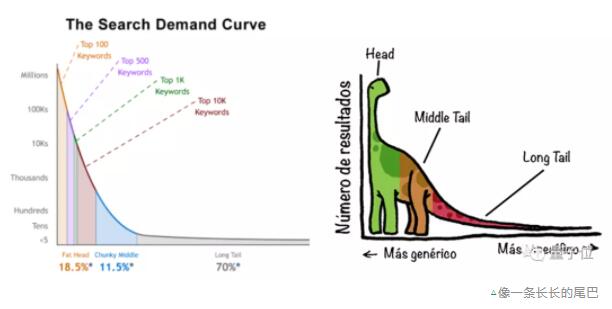
△像一條長(zhǎng)長(zhǎng)的尾巴
然而事實(shí)上,在一個(gè)數(shù)據(jù)集中,幾乎總有常見(jiàn)和不常見(jiàn)的類(lèi)別,其中不常見(jiàn)的類(lèi)別,又往往成為需要被識(shí)別的目標(biāo)。
例如,自動(dòng)駕駛感知模型中,就要求AI能提前預(yù)測(cè)可能違規(guī)的情形,并及時(shí)阻止。
然而在自動(dòng)駕駛數(shù)據(jù)集里,不可能全是肇禍、違規(guī)的場(chǎng)景(大部分場(chǎng)景還是安全的)。
那么,這些“不均衡”的數(shù)據(jù)集,就真的不能用了嗎?
來(lái)自MIT的兩名博士生楊宇喆和Zhi Xu,想到了一種新的解決方案,研究成果登上了NeurIPS 2020頂會(huì)。

一起來(lái)看看。
一些已有的解決辦法
事實(shí)上,此前為了解決“不均衡”數(shù)據(jù)集,研究者們已經(jīng)嘗試過(guò)多種方法。
僅僅是主流算法,就分為七種:
重采樣 (re-sampling):分為對(duì)少樣本的過(guò)采樣、及多樣本的欠采樣,但這2種方法,都有欠缺的地方。其中,過(guò)采樣容易發(fā)生少樣本過(guò)擬合,無(wú)法學(xué)習(xí)更魯棒、易泛化的特征,在不平衡數(shù)據(jù)上表現(xiàn)較差;欠采樣會(huì)造成多樣本嚴(yán)重信息損失,導(dǎo)致發(fā)生欠擬合。
數(shù)據(jù)合成 (synthetic samples):生成和少樣本相似的新數(shù)據(jù)。以SMOTE方法為例,對(duì)于任意選取的少類(lèi)樣本,它用K近鄰選取相似樣本,并通過(guò)對(duì)樣本線(xiàn)性插值得到新樣本。這里與mixup方法相似,因此,也有非均衡的mixup版本出現(xiàn)。

重加權(quán) (re-weighting):為不同類(lèi)別(甚至不同樣本)分配不同的權(quán)重。其中,權(quán)重可以自適應(yīng)。這一方法誕生出很多變種,如對(duì)類(lèi)別數(shù)目的倒數(shù)進(jìn)行加權(quán)、對(duì)“有效”樣本數(shù)加權(quán)、對(duì)樣本數(shù)優(yōu)化分類(lèi)間距的損失加權(quán)等等。
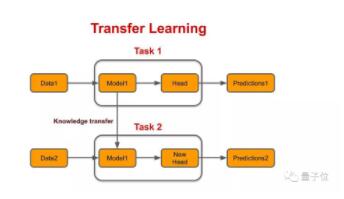
遷移學(xué)習(xí) (transfer learning):對(duì)多類(lèi)和少類(lèi)樣本分別建模,將學(xué)到的多類(lèi)樣本信息/表示/知識(shí)遷移給少類(lèi)別使用。
度量學(xué)習(xí) (metric learning):希望能學(xué)到更好的嵌入,以對(duì)少類(lèi)附近的邊界/邊緣更好地建模。
元學(xué)習(xí)/域自適應(yīng) (meta learning/domain adaptation):分別對(duì)頭、尾部數(shù)據(jù)進(jìn)行不同處理,自適應(yīng)地學(xué)習(xí)如何重加權(quán),或是規(guī)劃成域自適應(yīng)問(wèn)題。
解耦特征和分類(lèi)器 (decoupling representation & classifier):研究發(fā)現(xiàn),將特征學(xué)習(xí)和分類(lèi)器學(xué)習(xí)解耦、將不平衡學(xué)習(xí)分為兩個(gè)階段,并在特征學(xué)習(xí)階段正常采樣、在分類(lèi)器學(xué)習(xí)階段平衡采樣,可以帶來(lái)更好的長(zhǎng)尾學(xué)習(xí)效果。這是目前最優(yōu)的長(zhǎng)尾分類(lèi)算法。
但這些,在樣本極端失衡的情況下也沒(méi)法用,如果真的只有幾個(gè)樣本,模型的性能差異就無(wú)法避免。
關(guān)鍵在于,究竟該怎么理解這里面的“不均衡”?
“不均衡”標(biāo)簽的內(nèi)在價(jià)值
那些本身就不平衡的數(shù)據(jù)標(biāo)簽,會(huì)不會(huì)具有什么價(jià)值?
研究發(fā)現(xiàn),這些不平衡的數(shù)據(jù)標(biāo)簽,就像是一把“雙刃劍”。
一方面,這些標(biāo)簽提供了非常珍貴的監(jiān)督信息。
在特定任務(wù)上,有監(jiān)督學(xué)習(xí)通常比無(wú)監(jiān)督學(xué)習(xí)的準(zhǔn)確性更高,即使不平衡,標(biāo)簽也都具有“正面價(jià)值”。
但另一方面,標(biāo)簽的不平衡,會(huì)導(dǎo)致模型在訓(xùn)練過(guò)程中,被強(qiáng)加標(biāo)簽偏見(jiàn) (label bias),從而在決策區(qū)域被主類(lèi)別極大地影響。
研究者們認(rèn)為,即使是不平衡標(biāo)簽,它的價(jià)值也可以被充分利用,并極大地提高模型分類(lèi)的準(zhǔn)確性。
如果能先“拋棄標(biāo)簽信息”,通過(guò)自監(jiān)督預(yù)訓(xùn)練,讓模型學(xué)習(xí)到好的起始表示形式,是否就能有效地提高分類(lèi)準(zhǔn)確性?
從半監(jiān)督,到自監(jiān)督預(yù)訓(xùn)練
作者們先對(duì)半監(jiān)督下的不均衡學(xué)習(xí)進(jìn)行了實(shí)驗(yàn)。
實(shí)驗(yàn)證明,利用無(wú)標(biāo)記數(shù)據(jù)的半監(jiān)督學(xué)習(xí),能顯著提高分類(lèi)結(jié)果。
從圖中可以看出,未標(biāo)記數(shù)據(jù),有助于建模更清晰的類(lèi)邊界,促成更好的類(lèi)間分離。

這是因?yàn)椋差?lèi)樣本所處區(qū)域數(shù)據(jù)密度低,在學(xué)習(xí)過(guò)程中,模型不能很好地對(duì)低密度區(qū)域進(jìn)行建模,導(dǎo)致泛化性差。
而無(wú)標(biāo)記數(shù)據(jù),能有效提高低密度區(qū)域樣本量,使得模型能對(duì)邊界進(jìn)行更好的建模。
然而,在一些很難利用半監(jiān)督學(xué)習(xí)的極端情況下,仍然需要自監(jiān)督學(xué)習(xí)出場(chǎng)。
這是因?yàn)椋坏┳员O(jiān)督產(chǎn)生良好初始化,網(wǎng)絡(luò)就可以從預(yù)訓(xùn)練任務(wù)中受益,學(xué)習(xí)到更通用的表示形式。
而實(shí)驗(yàn)同樣證明了這一點(diǎn)。
正常預(yù)訓(xùn)練的決策邊界,很大程度上會(huì)被頭類(lèi)樣本改變,導(dǎo)致尾類(lèi)樣本大量“泄漏”,無(wú)法很好地泛化。
而采用自監(jiān)督預(yù)訓(xùn)練的話(huà),學(xué)習(xí)到的樣本保持清晰的分離效果,且能減少尾類(lèi)樣本泄漏。
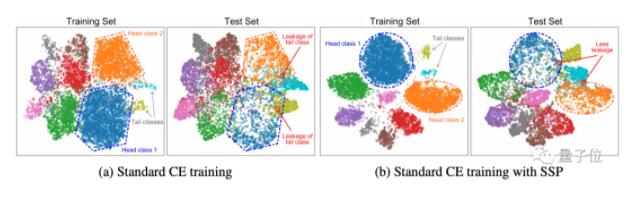
也就是說(shuō),為了利用自監(jiān)督克服標(biāo)簽偏見(jiàn),在長(zhǎng)尾學(xué)習(xí)的第一階段,需要先放棄標(biāo)簽信息,進(jìn)行自監(jiān)督預(yù)訓(xùn)練。
此階段后,可以使用任何標(biāo)準(zhǔn)訓(xùn)練方法,訓(xùn)練得到最終模型。(例如此前所用的遷移學(xué)習(xí)、重加權(quán)、域自適應(yīng)……)
這樣,就能更好地解決長(zhǎng)尾問(wèn)題。
作者介紹
論文一作楊宇喆,目前是MIT計(jì)算機(jī)科學(xué)的三年級(jí)博士生,本科畢業(yè)于北京大學(xué)。
目前,楊宇喆的研究方向主要有兩個(gè):基于學(xué)習(xí)的無(wú)線(xiàn)感應(yīng)技術(shù),應(yīng)用方向是醫(yī)療保健;機(jī)器學(xué)習(xí),主要是針對(duì)機(jī)器學(xué)習(xí)和強(qiáng)化學(xué)習(xí)的魯棒性進(jìn)行研究。
論文二作Zhi Xu,本科畢業(yè)于伊利諾伊大學(xué)厄巴納-香檳分校,同樣是MIT的博士生,感興趣的研究方向是機(jī)器學(xué)習(xí)理論和現(xiàn)代應(yīng)用,目前主要在研究強(qiáng)化學(xué)習(xí)的穩(wěn)定性、效率、結(jié)構(gòu)和復(fù)雜度。
論文地址:
https://arxiv.org/abs/2006.07529
項(xiàng)目地址:
https://github.com/YyzHarry/imbalanced-semi-self
論文解讀@楊宇喆:
https://zhuanlan.zhihu.com/p/259710601