













人工智能(Artificial Intelligence)入門看這篇就夠了!
要問現(xiàn)在的科技界什么最火?答案八九不離十是人工智能,機器學習,深度學習等等。事實上,人工智能所代表的一系列技術(shù)已經(jīng)走入千家萬戶,深入我們的日常生活。公司門口的指紋門禁,手機拍照時的人臉聚焦,居家使用的掃地機器人,凡此種種,都可以看做是人工智能的衍生。
人機對戰(zhàn)國際象棋
從專業(yè)的角度來說,人工智能(AI)指的是在被編程為像人類一樣思考并模仿其行為的機器中對人類智能的仿真。簡而言之,讓機器變得更像人類的動作和思維,比如機器人試圖去模仿人類的動作,比如AlphaGo去模仿人類思考下圍棋。考慮到人工智能的領域之廣與大家現(xiàn)時的基礎,我們以當下十分火熱的計算機視覺問題為例,詳細描述用計算機進行物體識別的過程,希望能夠激發(fā)大家的興趣。
計算機如何“看”東西?
人類在看到一張照片時,能夠輕易的判斷出照片的內(nèi)容,這個過程涉及到復雜的生物和認知科學知識。簡而言之,可以想象成,我們的眼睛接受了來自照片的信息,信息通過大腦內(nèi)的神經(jīng)元,經(jīng)過復雜的處理,最終產(chǎn)生了相關的信號,比如“照片中有三個人,其中一個可能是媽媽還有兩個是她的孩子”。
與人類類似,計算機同樣經(jīng)歷了“信號獲取”,“信號處理”,“信號反饋”的三個過程。攝像頭,照相機等成像設備代替了眼睛,計算機芯片電路代替了腦內(nèi)神經(jīng)元,最后處理完的信號通過顯示器進行反饋。
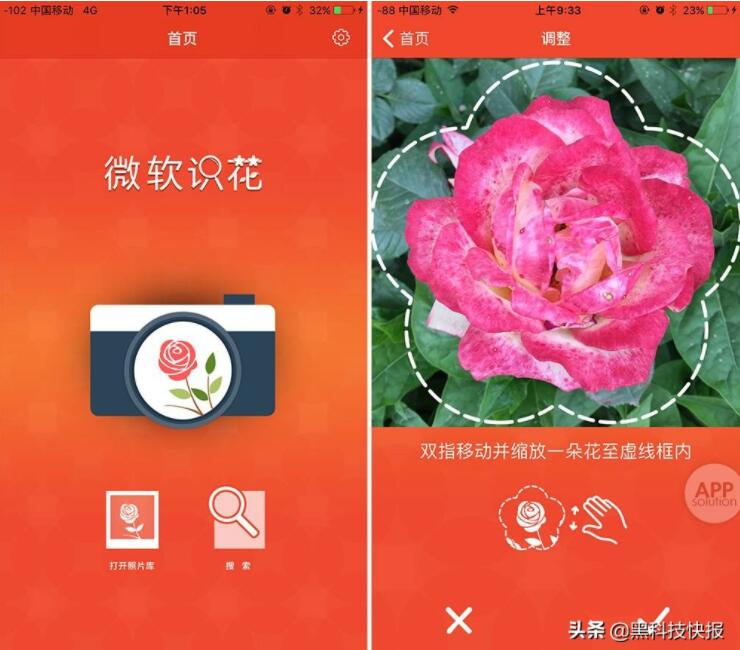
利用手機攝像頭進行花卉識別
我們以手機攝像頭識別花卉為例,要經(jīng)歷怎樣的過程才可以使我們的攝像頭能夠“認出來”花卉的種類呢?與人類類似,手機同樣需要經(jīng)歷學習的過程,我們會先給“它”看很多很多的花卉照片并且告訴“它”這些照片所屬于的類別,具體過程如下:
- 首先,攝像頭拍攝花卉照片,在手機電腦等計算設備中,照片是以矩陣的形式存在的,可以理解成一堆數(shù)字,其中數(shù)字的大小代表了顏色和亮度等等信息;
- 我們將矩陣X輸入到神經(jīng)網(wǎng)絡N(可以看做是一種復雜的數(shù)學函數(shù),給一個輸入值能夠得到一個輸出值)中,記錄輸出的數(shù)值Y;
- 由于這是學習過程,所以我們事先知道每張照片的真實類別Z,那么為了使我們的神經(jīng)網(wǎng)絡N有著正確的識別能力,Y應當和Z越近似越好。于是我們通過改變N的參數(shù),使得Y與Z的距離變小;
- 重復1-3,當你認為Y和Z足夠近似,模型的學習過程就結(jié)束啦!
有了學習完成的神經(jīng)網(wǎng)絡N后,當你用手機拍攝了一張新的花卉照片,攝像頭會提取新的矩陣X',X'經(jīng)過神經(jīng)網(wǎng)絡的計算之后會得到Y(jié)',我們比較Y'與所有的Z,最接近的那個就可以看做是新照片的類別啦。
當然,上述過程為了簡單易懂省略了很多,也有部分不符合專業(yè)規(guī)范的表述,大家如果有興趣的話可以持續(xù)關注我的更新,人工智能充滿魅力!
新手如何入門機器學習?
首先需要說明的是,人工智能,機器學習和深度學習這三者是包含的關系,人工智能代表了廣義的擬人化概念,機器學習特指利用統(tǒng)計學和數(shù)學模型進行建模,深度學習更進一步限制了模型的種類為深度神經(jīng)網(wǎng)絡,大家有個概念就可以,隨著學習的深入會慢慢理解其本質(zhì)。
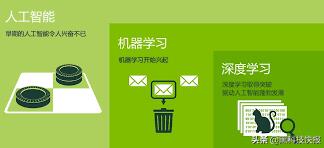
三者的包含關系
在知乎上有些朋友曾經(jīng)私信我,作為剛?cè)腴T的新手如何學習機器學習呢?我很理解大家的困惑,如上所言,這是一個龐大且日新月異的領域,技術(shù)每分每秒都在更新,作為小白如何確定自己找對了方向呢?我的建議是,不要盲目追求新技術(shù),當下涌現(xiàn)的大量新技術(shù),事實上都是就技術(shù)的新子集,冠以高大上的命名。
以下內(nèi)容涉及較專業(yè)的名詞,不感興趣的大家可以關掉啦~
不太清楚題主的風格,但我個人在接觸一個新事物的時候會偏向于首先了解這個東西的動機起源。新手在接觸機器學習時最大的困惑時,不知道如何下手。我個人認為,首先是確定你自己的興趣方向,比如你要做視頻圖像的預測,那首先在方法層面上限制到生成模型上。
我們通過查閱文獻可以知道,最早的生成模型比如從物理學能量模型啟發(fā)而來的Boltamann Machine,比如深度置信網(wǎng)(Pretraining, Hinton 2006),再到現(xiàn)在流行的GAN和VAE。這個過程可以適當縮短,因為State-of-art基本上沒有在用玻爾茲曼機深度置信網(wǎng)這些老古董的。但是,但是,如果你真的想做出變革,我認為了解深刻的背景是很有必要的。比如Goodfellow為什么會提出GAN?你怎么能提出一個像GAN這樣影響領域的東西?(我個人認為GAN的核心就是Discriminator,相較于常用的MSE,L1等等,Discriminator充當了更接近于人類的判斷者角色,其數(shù)學推導也證明了DIscriminator能夠最小化分布的距離。)
當你接觸到GAN和VAE時,可能今天看了一篇CycleGAN,明天又讀了一篇FactorVAE,但是這些不同的知識對于新手來說,是獨立隔離的。事實上,以上兩者都是屬于深度生成模型,其中CycleGAN運用到了cycle consistency,這又是一個被廣泛應用的技術(shù);FactorVAE又涉及到Disentanglement機制,這涉及到可解釋模型的概念。所以,在這一步,你需要更一步縮小你的目標問題。比如針對固定攝像頭的異常事件預測(聽起來怪怪的,舉個例子不要在意)。

Deep Learning(花書),據(jù)說已經(jīng)有中文版面世~
這里強烈推薦Goodfellow和Bengio的Deep Learning,花書真的是一本很好的書,如果時間充足建議通讀。當然,根據(jù)自己平時的需求去找到相關的章節(jié)也是可以的,但是前十章建議通讀,這會減少你很多走彎路的時間。花書的優(yōu)點是,所有你平時可能存在的小疑問這里都很詳細的解釋了動機。例如第7章對于Dropout機制的說明,此前我對于Dropout只停留在操作層面(我真的一直這么認為,沒想過為什么),也是很多中文博客(很多英文直翻的博客額。。。)的內(nèi)容,即,在前向傳遞的過程中隨機將一些連接的weight設為0。是Bengio的解釋點醒了我,這事實上就是一種Boost機制,每次前向傳遞事實上都訓練了不同的子模型。當訓練完成之后,在最后的test過程,就實現(xiàn)了Voting的過程。





















