我拍了拍Redis,被移出了群聊···
Redis的新煩惱你好,我是Redis,一個叫Antirez的男人把我帶到了這個世界上。
自從上次被拉入群聊之后(那天,我被拉入一個Redis群聊···),我就從一個人單打獨斗變成了團隊合作,在小伙伴們的共同努力下,不僅有主從復制可以數據備份,還有哨兵節點負責監控管理,我現在也可以拍拍胸脯說我們是高可用服務了!
但是,幸福的日子沒過太久,我們就笑不起來了。
不知道是我們的工作太出色,還是業務發展太快,程序員們對我們養成了依賴,什么都往我們這里寫,數據量越來越大,我們承受了這個年紀不該有的壓力~
雖然有主從復制+哨兵,但只能解決高可用的問題,解決不了數據量大的問題!
因為咱們看起來人手多,但都是存儲的全量數據,所以對于數據容量提升并沒有什么幫助。
集群時代
這一天,我找到了大白和小黑,咱們仨合計了一下,一個節點的力量不足,但眾人劃槳可以開大船啊,我們決定把三個人的內存空間“拼”起來,每個人負責一部分數據,合體進化成一個大的緩存服務器,進入集群Cluster時代!
集群,集群,首要問題當然是團隊建設啦!我們得想一套辦法來組建團隊,還要考慮到以后可能會擴容,會有新的伙伴加入我們,我們仨憋了半天,抄襲人家TCP的三次握手,也搞了一個握手協議出來。
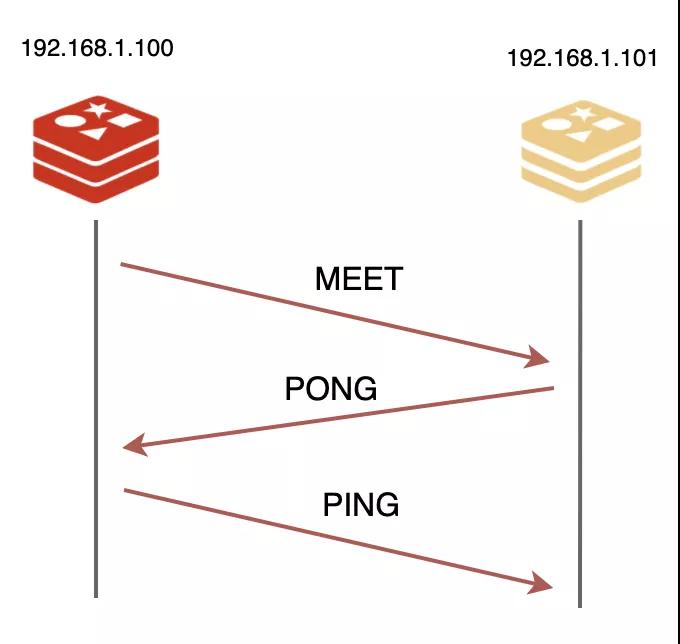
想要加入集群,得有一個介紹人才行。通過團隊里的任何一個成員都行,就比如說我吧,只要告訴我IP和端口,我就給他發送一個MEET信息,發起握手,對方得回我一個PONG信息同意入伙,最后我再回他一個PING信息,三次握手就完成了!
然后,我再把這件事告訴團隊中其他成員,新的伙伴就算正式成為我們的一份子了。
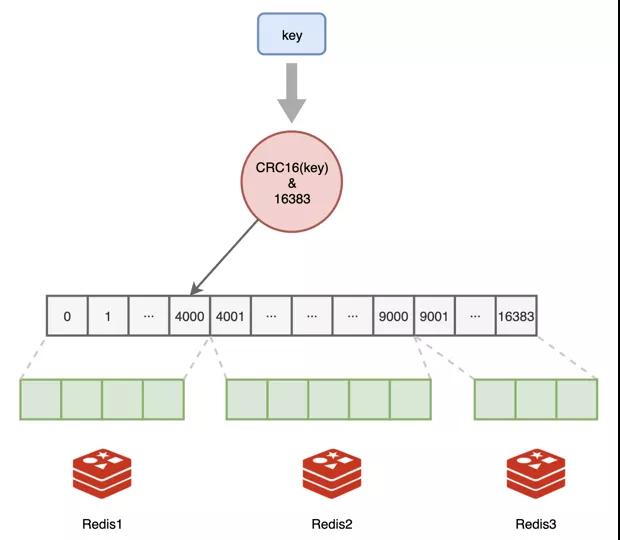
第二件很重要的事情就是要解決數據存儲的公平問題,不能旱的旱死,澇的澇死,我們爭論了很久,最后決定學習人家哈希表的方法。
我們總共劃分了16384個哈希桶,我們把它叫做槽位Slot,程序員可以按照我們能力大小給我們各自分配一部分槽位,比如我們團隊:
我:0-4000
大白:4001-9000
小黑:9001-16383
我比較菜,只分到了4000個,小黑老哥最辛苦,要負責7000+個槽位,正所謂能力越大,責任越大,誰叫他內存空間最大呢。
數據讀寫的時候,對鍵值做一下哈希計算,映射到哪個槽,就由誰負責。
為了讓大家的信息達成一致,啟動的時候,每個人都得把自己負責的槽位信息告訴其他伙伴。
一共有一萬多個槽,要通知其他小伙伴,需要傳輸的數據量還挺大的,后來我們仨又商量了一下,為了壓縮數據空間,每個槽位干脆就用一個bit來表示,自己負責這一位就是1,否則就是0,總共也才16384個bit,也就是2048個字節,傳輸起來輕便快捷,一口氣就發送過去了。
struct clusterNode { // ... unsigned char *slots[16384/8]; // ...};
這樣傳輸的數據是輕量了,但真正工作的時候還是不方便,遇到讀寫數據的時候,總不能挨個去看誰的那一位是1吧。
干脆一步到位,用空間換時間,我們又準備了一個超大的數組來存儲每個槽由哪個節點來負責,通過上面的方式拿到信息后,就更新到這里來:
struct clusterNode *slots[16384];
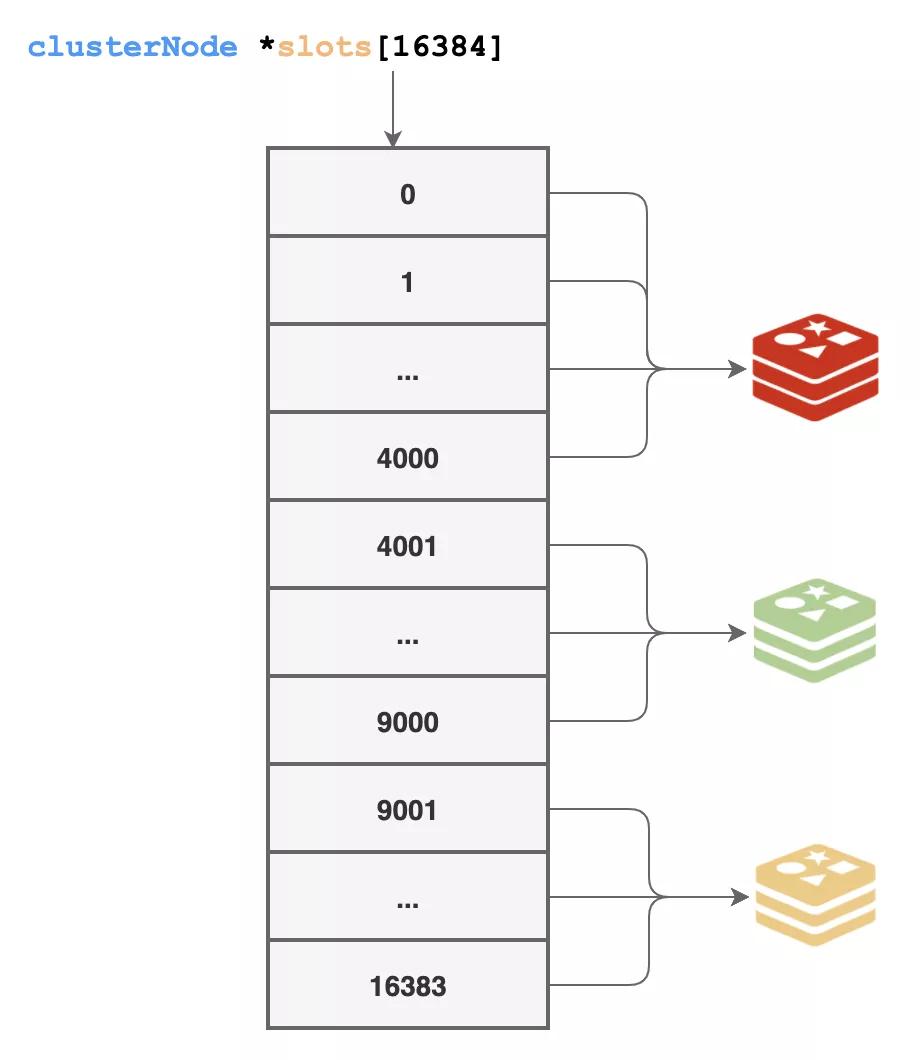
這樣一來,遇到數據訪問的時候,我們就能快速知道這個數據是由誰來負責了。
對了,這16384個槽位必須都得有人來負責,我們整個集群才算是正常工作,處于上線狀態,否則就是下線狀態。
你想啊,萬一哪個鍵值哈希映射后的槽位沒人負責,那該從哪里讀,又該寫到哪里去呢?所以我們要工作,一個槽都不能少!
集群數據的訪問數據分派的問題解決了,我們團隊總算可以正式上線工作了!
和原來不同的是,數據讀寫的時候多了一個步驟:得先檢查數據是不是由自己負責。
如果是自己負責,那就進行處理,不然的話,就要返回一個MOVED錯誤給請求端,同時把槽號、IP和端口告訴他,讓他知道該去找誰處理。嘿嘿,這個MOVED我們也是抄襲的HTTP中的302跳轉~
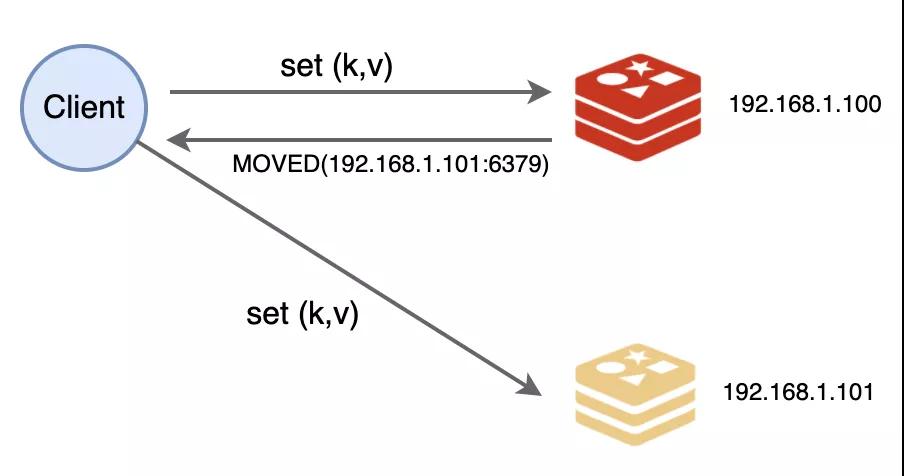
不過程序員們是感知不到的,他們都是用封裝好的庫來操作,才不會親自寫代碼來跟我通信呢~
一開始的工作很順利,但沒過多久就出事兒了!

隨后我們開始了數據遷移,還把這一套流程標準化了,留著為以后新入伙的朋友分配數據。
經過一段時間的磨合,我們集群小分隊配合的越來越默契。
不過光靠咱們仨還是不行,萬一哪天有人掛了,整個集群就得下線了!咱們三個每人至少得有一個backup才行!
于是我找到了原來的一幫小弟,讓他們也加入我們,繼續給我們當起了從節點,平時當我們的backup,從我們這里復制數據,一旦我們遇到故障,他們就能快速頂上。
有了集群工作+主從復制,我們現在不僅高可用,數據容量也大大提升了,就算以后不夠用了也有辦法擴容,我們又過上了舒服的日子~
本文轉載自微信公眾號「編程技術宇宙」,可以通過以下二維碼關注。轉載本文請聯系編程技術宇宙公眾號。