我身邊的高T,問了Java面試者這樣的問題......
大家好,我是來自JDL京東物流技術發展部邢煥杰, 今天來分享一個京東面試真題,這也是我前陣子聽我工位旁邊高T(高,實在是高)面試候選人的時候問的一個問題,他問,你能說說 MySQL的事務嗎?MVCC有了解嗎?話不多說,本文就深度解析一下MySQL事務及MVCC的實現原理。
事務定義及四大特性
事務是什么?
就是用戶定義的一系列數據庫操作,這些操作可以視為一個完成的邏輯處理工作單元,要么全部執行,要么全部不執行,是不可分割的工作單元。
事務的四大特性(簡稱ACID):
原子性(Atomicity):一個事務是一個不可分割的工作單位,事務中包括的操作要么都做,要么都不做。 一致性(Consistency):事務必須是使數據庫從一個一致性狀態變到另一個一致性狀態。一致性與原子性是密切相關的。 隔離性(Isolation):一個事務的執行不能被其他事務干擾。即一個事務內部的操作及使用的數據對并發的其他事務是隔離的,并發執行的各個事務之間不能互相干擾. 持久性(Durability):指一個事務一旦提交,它對數據庫中數據的改變就應該是永久性的,接下來的其他操作或故障不應該對其有任何影響。
事務中常見問題
臟讀(dirty read):就是一個A事務即便沒有提交,它對數據的修改也可以被其他事務B事務看到,B事務讀到了A事務還未提交的數據,這個數據有可能是錯的,有可能A不想提交這個數據,這只是A事務修改數據過程中的一個中間數據,但是被B事務讀到了,這種行為被稱作臟讀,這個數據被稱為臟數據
不可重復讀(non-repeatable read):在A事務內,多次讀取同一個數據,但是讀取的過程中,B事務對這個數據進行了修改,導致此數據變化了,那么A事務再次讀取的時候,數據就和第一次讀取的時候不一樣了,這就叫做不可重復讀
幻讀(phantom read):A事務多次查詢數據庫,結果發現查詢的數據條數不一樣,A事務多次查詢的間隔中,B事務又寫入了一些符合查詢條件的多條數據(這里的寫入可以是update,insert,delete),A事務再查的話,就像發生了幻覺一樣,怎么突然改變了這么多,這種現象這就叫做幻讀
隔離級別——產生問題的原因
多個事務互相影響,并沒有隔離好,就是我們剛才提到的事務的四大特性中的 隔離性(Isolation) 出現了問題 事務的隔離級別并沒有設置好,下面我們來看下事務究竟有哪幾種隔離級別
隔離級別 讀未提交(read uncommitted RU): 一個事務還沒提交時,它做的變更就能被別的事務看到 讀提交(read committed RC): 一個事務提交之后,它做的變更才會被其他事務看到。 可重復讀(repeatable read RR): 一個事務執行過程中看到的數據,總是跟這個事務在啟動時看到的數據是一致的。當然在可重復讀隔離級別下,未提交變更對其他事務也是不可見的。 串行化(serializable ): 顧名思義是對于同一行記錄,“寫”會加“寫鎖”,“讀”會加“讀鎖”。當出現讀寫鎖沖突的時候,后訪問的事務必須等前一個事務執行完成,才能繼續執行。
我們來看個例子,更加直觀的了解這四種隔離級別和上述問題臟讀,不可重復讀,幻讀的關系
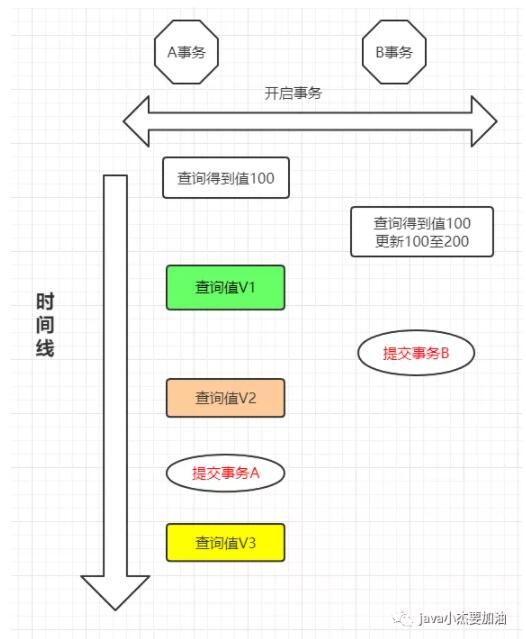
下面我們討論下當事務處于不同隔離級別情況時,V1,V2,V3分別是什么不同的值吧
讀未提交 (RU): A事務可以讀取到B事務修改的值,即便B事務沒有提交。所以V1就是200
V1 : 200 V2 : 200 V3 : 200
讀提交(RC): 當B事務沒有提交的時候,A事務不可以看到B事務修改的值,只有提交以后才可以看到
V1 : 100 V2 : 200 V3 : 200
可重復讀(RR): A事務多次讀取數據,數據總和第一次讀取的一樣,
V1 : 100 V2 : 100 V3 : 200
串行化(S): 事務A在執行的時候,事務B會被鎖住,等事務A執行結束后,事務B才可以繼續執行
V1 : 100 V2 : 100 V3 : 200
MVCC原理
MVCC(Multi-Version Concurrency Control)多版本并發控制,是數據庫控制并發訪問的一種手段。
特別要注意MVCC只在 讀已提交(RC) 和 可重復度(RR) 這兩種事務隔離級別下才有效 是 數據庫引擎(InnoDB) 層面實現的,用來處理讀寫沖突的手段(不用加鎖),提高訪問性能
MVCC是怎么實現的呢?它靠的就是版本鏈和一致性視圖
1. 版本鏈
版本鏈是一條鏈表,鏈接的是每條數據曾經的修改記錄
那么這個版本鏈又是如何形成的呢,每條數據又是靠什么鏈接起來的呢?
其實是這樣的,對于InnoDB存儲引擎的表來說,它的聚簇索引記錄包含兩個隱藏字段
trx_id: 存儲修改此數據的事務id,只有這個事務操作了某些表的數據后當更改操作發生的時候(update,delete,insert),才會分配唯一的事務id,并且此事務id是遞增的 roll_pointer: 指針,指向上一次修改的記錄 row_id(非必須): 當有主鍵或者有不允許為null的unique鍵時,不包含此字段
假如說當前數據庫有一條這樣的數據,假設是事務ID為100的事務插入的這條數據,那么此條數據的結構如下:

后來,事務200,事務300,分別來修改此數據:
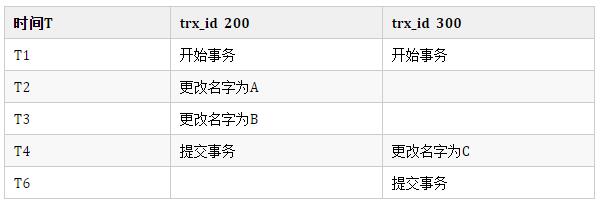
所以此時的版本鏈如下:
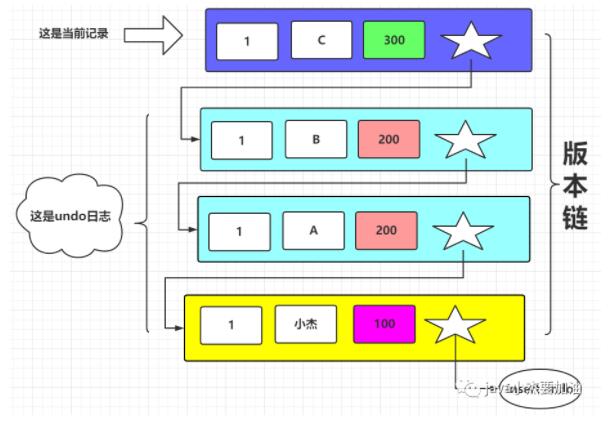
我們每更改一次數據,就會插入一條undo日志,并且記錄的roll_pointer指針會指向上一條記錄,如圖所示:
第一條數據是小杰,事務ID為100 事務ID為200的事務將名稱從小杰改為了A 事務ID為200的事務將名稱從A又改為了B 事務ID為300的事務將名稱從B又改為了C
所以串成的鏈表就是 C -> B -> A -> 小杰 (從最新的數據到最老的數據)
2. 一致性視圖(ReadView)
需要判斷版本鏈中的哪個版本是是當前事務可見的,因此有了一致性視圖的概念。其中有四個屬性比較重要
m_ids: 在生成ReadView時,當前活躍的讀寫事務的事務id列表 min_trx_id: m_ids的最小值 max_trx_id: m_ids的最大值+1 creator_trx_id: 生成該事務的事務id,單純開啟事務是沒有事務id的,默認為0,creator_trx_id是0。
版本鏈中的當前版本是否可以被當前事務可見的要根據這四個屬性按照以下幾種情況來判斷
當 trx_id = creator_trx_id 時:當前事務可以看見自己所修改的數據, 可見, 當 trx_id < min_trx_id 時 : 生成此數據的事務已經在生成readView前提交了, 可見 當 trx_id >= max_trx_id 時 :表明生成該數據的事務是在生成ReadView后才開啟的, 不可見 當 min_trx_id <= trx_id < max_trx_id 時 trx_id 在 m_ids 列表里面 :生成ReadView時,活躍事務還未提交,不可見 trx_id 不在 m_ids 列表里面 :事務在生成readView前已經提交了,可見

如果某個版本數據對當前事務不可見,那么則要順著版本鏈繼續向前尋找下個版本,繼續這樣判斷,以此類推。
注:RR和RC生成一致性視圖的時機不一樣 (這也是兩種隔離級別實現的主要區別)
讀提交(read committed RC) 是在每一次select的時候生成ReadView的 可重復讀(repeatable read RR)是在第一次select的時候生成ReadView的
下面咱們一起來舉個例子實戰一下。
RR與RC和MVCC的例子實戰
假如說,我們有多個事務如下執行,我們通過這個例子來分析當數據庫隔離級別為RC和RR的情況下,當時讀數據的一致性視圖和版本鏈,也就是MVCC,分別是怎么樣的。
假設數據庫中有一條初始數據 姓名是java小杰要加油,id是1 (id,姓名,trx_id,roll_point),插入此數據的事務id是1 尤其要指出的是,只有這個事務操作了某些表的數據后當更改操作發生的時候(update,delete,insert),才會分配唯一的事務id,并且此事務id是遞增的,單純開啟事務是沒有事務id的,默認為0,creator_trx_id是0。 以下例子中的A,B,C的意思是將姓名更改為A,B,C 讀也是讀取當前時刻的姓名,默認全都開啟事務,并且此事務都經歷過某些操作產生了事務id

讀已提交(RC)與MVCC
當T1時刻時,事務100修改名字為A 當T2時刻時,事務100修改名字為B 當T3時刻時,事務200修改名字為C 當T4時刻時,事務300開始讀取名字
同顏色代表是同一事務內的操作
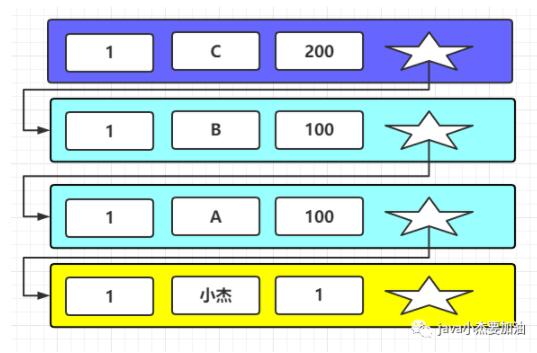
- m_ids 是[100,200]: 當前活躍的讀寫事務的事務id列表
-
min_trx_id 是 100: m_ids的最小值
-
max_trx_id 是 201: m_ids的最大值+1
當前數據的trx_id(事務id)是 200,符合min_trx_id<=trx_id<max_trx_id 此時需要判斷 trx_id 是否在m_ids活躍事務列表里面,一看,活躍事務列表里面是【100,200】,只有兩個事務活躍,而此時的trx_id是200,則trx_id在活躍事務列表里面,活躍事務列表代表還未提交的事務,所以該版本數據不可見,就要根據roll_point指針指向上一個版本,繼續這樣的判斷,上一個版本事務id是100,數據是B,發現100也在活躍事務列表里面,所以不可見,繼續找到上個版本,事務是100,數據是A,發現是同樣的情況,繼續找到上個版本,發現事務是1,數據是小杰,1小于100,trx_id<min_trx_id,代表生成這個數據的事務已經在生成ReadView前提交了,此數據可以被讀到。所以讀取的數據就是小杰。
分析完第一個讀,我們繼續向下分析
當T5時刻時,事務100提交 當T6時刻時,事務300將名字改為D 當T7時刻時,事務400讀取當前數據
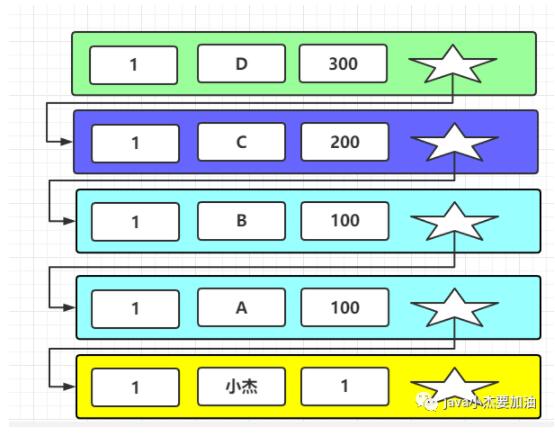
此時 (重新生成一致性視圖ReadView)
-
m_ids 是[200,300]: 當前活躍的讀寫事務的事務id列表 min_trx_id 是 200: m_ids的最小值 max_trx_id 是 301: m_ids的最大值+1
當前數據事務id是300,數據為D,符合min_trx_id<=trx_id<max_trx_id 此時需要判斷數據是否在活躍事務列表里,300在這里面,所以就是還未提交的事務就是不可見,所以就去查看上個版本的數據,上個版本事務id是200,數據是C,也在活躍事務列表里面,也不可見,繼續向上個版本找,上個版本事務id是100,數據是B,100小于min_trx_id,就代表,代表生成這個數據的事務已經在生成ReadView前提交了,此數據可見,所以讀取出來的數據就是B。
分析完第二個讀,我們繼續向下分析
當T8時刻時,事務200將名字改為E 當T9時刻時,事務200提交 當T10時刻時,事務300讀取當前數據
此時這條數據的版本鏈如下:
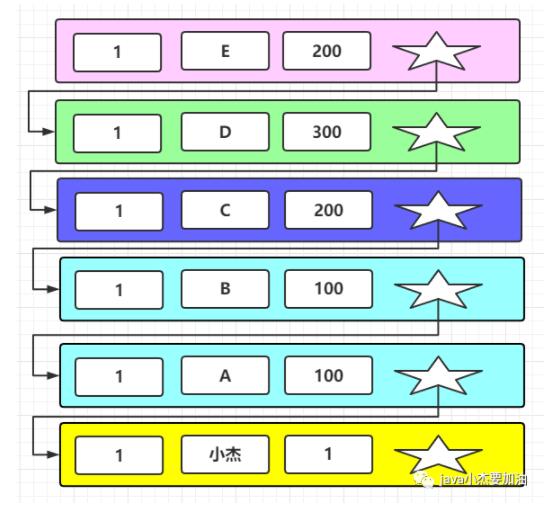
此時 (重新生成一致性視圖ReadView)
-
m_ids 是[300]: 當前活躍的讀寫事務的事務id列表 min_trx_id 是 300: m_ids的最小值 max_trx_id 是 301: m_ids的最大值+1
當前事務id是200,200<min_trx_id ,代表生成這個數據的事務已經在生成ReadView前提交了,此數據可見,所以讀出的數據就是E。
當隔離級別是讀已提交RC的情況下,每次讀都會重新生成 一致性視圖(ReadView)
T4時刻 事務300讀取到的數據是小杰 T7時刻 事務400讀取到的數據是B T10時刻 事務300讀取到的數據是E
可重復讀(RR)與MVCC
所以對于事務300來講,它分別在T4和T10的時候,讀取數據,但是它的一致性視圖,用的永遠都是第一次讀取時的視圖,就是T3時刻產生的一致性視圖
RR和RC的版本鏈是一樣的,但是判斷當前數據可見與否用到的一致性視圖不一樣
在此可重復讀RR隔離級別下,
T4時刻時事務300第一次讀時的分析和結果與RC都一樣,可以見上文分析與結果 T7時刻時事務400第一次讀時的分析和結果與RC都一樣,可以見上文分析與結果 T10時刻時事務300第二次讀時的一致性視圖和第一次讀時的一樣,所以此時到底讀取到什么數據就要重新分析了
此時 (用的是第一次讀時生成的一致性視圖ReadView)
-
m_ids 是[100,200]: 當前活躍的讀寫事務的事務id列表 min_trx_id 是 100: m_ids的最小值 max_trx_id 是 201: m_ids的最大值+1
此時的版本鏈是
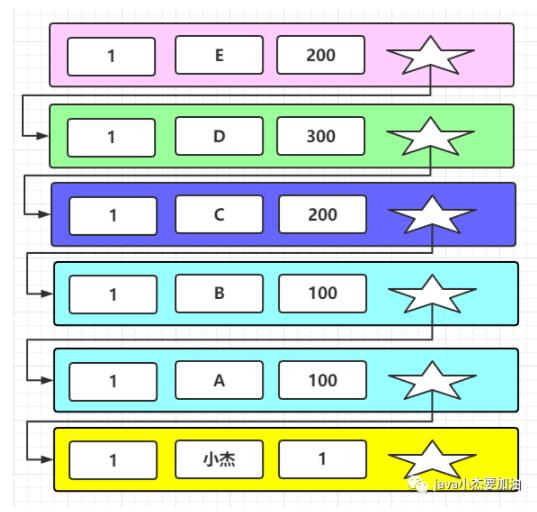
當前數據的事務id是200,數據是E,在當前事務活躍列表里面,所以數據不可見,根據回滾指針找到上個版本,發現事務id是300,當前事務也是300,可見,所以讀取的數據是D
當隔離級別是可重復讀RR的情況下,每次讀都會用第一次讀取數據時生成的一致性視圖(ReadView)
T4時刻 事務300讀取到的數據是小杰 T7時刻 事務400讀取到的數據是B T10時刻 事務300讀取到的數據是D