優(yōu)化Kubernetes上的JVM Warm-up

JVM 預熱(warm-up)是一個臭名昭著的問題。盡管基于JVM的應用程序有著出色的性能,但是需要一個預熱的過程,在預熱期間,性能不是最佳的。它可以歸因于即時(JIT)編譯之類的事情,它通過收集使用情況配置文件信息來優(yōu)化常用代碼。最終的負面影響是,與平均時間相比,在預熱期間收到的請求將具有非常高的響應時間。在容器化,高吞吐量,頻繁部署和自動伸縮的環(huán)境中,此問題可能會加劇。
在這篇文章中,我將討論我們在Kubernetes集群中使用Java服務關于JVM預熱問題的經(jīng)驗和方法。
創(chuàng)世記
幾年前,我們從單體架構(gòu)逐步轉(zhuǎn)為微服務架構(gòu),并且部署到Kubernetes中。大多數(shù)新服務都是用Java開發(fā)的。當我們啟用Java服務時,我們首先遇到了這個問題。通過負載測試執(zhí)行了正常的容量規(guī)劃過程,并確定N個容器足以處理超出預期的峰值流量。
盡管該服務可以毫不費力地處理高峰流量,但我們開始在部署過程中發(fā)現(xiàn)問題。我們的每個Pod在高峰時間處理的RPM都超過10k,而我們使用的是Kubernetes滾動更新機制。在部署期間,服務的響應時間會激增幾分鐘,然后再穩(wěn)定到通常的穩(wěn)定狀態(tài)。在我們的NewRelic儀表板中,我們將看到類似于以下的圖形:
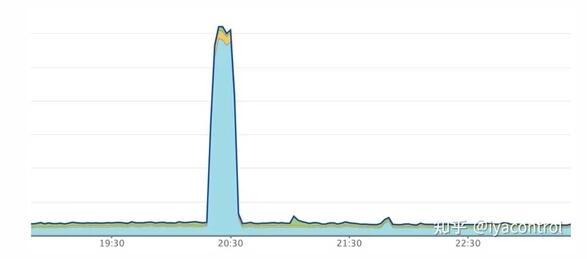
同時,依賴于我們該部署的其他服務在相關時間段內(nèi)也發(fā)生了高響應時間和超時錯誤。
Take 1: 增加應用數(shù)目
我們很快意識到該問題與JVM預熱階段有關,但是由于正在進行其他重要事情,因此沒有太多時間進行排查。因此,我們嘗試了最簡單的解決方案--增加容器的數(shù)量,以減少每個容器的吞吐量。我們將Pod的數(shù)量增加了幾乎三倍,因此每個Pod在高峰時處理的吞吐量約為4k RPM。我們還調(diào)整了部署策略,以確保一次最多25%的部署(使用maxSurge和maxUnavailable參數(shù))。這樣就解決了問題,盡管我們的運行速度是穩(wěn)態(tài)所需容量的3倍,但我們能夠在我們的服務或任何相關服務中毫無問題地進行部署。
在接下來的幾個月中,隨著我們遷移更多服務,我們也開始在其他服務中頻繁注意到該問題。然后,我們決定花一些時間來排查問題并找到更好的解決方案。
Take 2: Warm-Up 腳本
閱讀各種文章之后,我們決定嘗試一下熱身腳本。我們的想法是運行一個預熱腳本,該腳本將綜合請求發(fā)送給該服務幾分鐘,以期預熱JVM,然后才允許實際流量通過。
為了創(chuàng)建預熱腳本,我們從生產(chǎn)流量中抓取了實際的URL。然后,我們創(chuàng)建了一個Python腳本,該腳本使用這些URL發(fā)送并行請求。我們相應地配置了就緒探針的initialDelaySeconds,以確保預熱腳本在Pod準備就緒并開始接受流量之前完成。
令我們驚訝的是,盡管我們看到了一些改進,但這并不重要。我們?nèi)匀挥^察到響應時間和錯誤。另外,預熱腳本引入了新問題。之前,我們的Pod可以在40-50秒內(nèi)準備就緒,但是使用腳本,它們大約需要3分鐘,這在部署過程中成為一個問題,但更重要的是在自動伸縮過程中。我們對熱身機制進行了一些調(diào)整,例如在熱身腳本和實際流量之間進行短暫的重疊,并在腳本本身中進行更改,但并沒有看到明顯的改進。最后,我們認為熱身策略所帶來的小收益是不值得的,因此完全放棄了。
Take 3: 探索啟發(fā)式技術
既然我們的熱身腳本想法破滅了,決定嘗試一些啟發(fā)式技術:
- GC (G1, CMS, and Parallel) and various GC parameters
- Heap memory
- CPU allocated
經(jīng)過幾輪實驗,我們終于取得了突破。我們正在測試的服務配置了Kubernetes資源限制:
- resources:
- requests:
- cpu: 1000m
- memory: 2000Mi
- limits:
- cpu: 1000m
- memory: 2000Mi
我們增加了CPU請求并將其限制為2000m,并部署了該服務以查看影響。與預熱腳本相比,我們在響應時間和錯誤方面看到了巨大的進步。
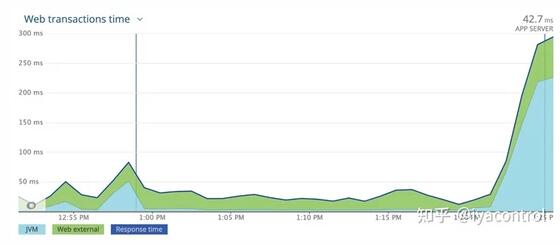
為了進一步測試,我們將配置升級到3000m CPU,令人驚訝的是,問題完全消失了。如下所示,響應時間沒有峰值。
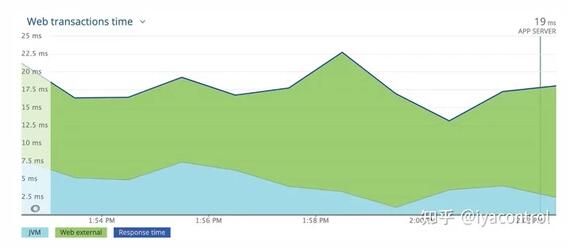
很快就發(fā)現(xiàn)問題出在CPU節(jié)流。顯然,在預熱階段,JVM需要比平均穩(wěn)態(tài)更多的CPU時間,但是Kubernetes資源處理機制(CGroup)正在按照配置的限制來限制CPU。
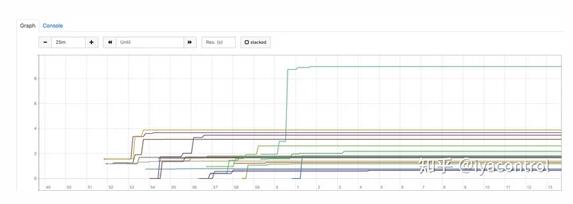
有一種直接的方法可以驗證這一點。 Kubernetes公開了每個容器的度量標準 container_cpu_cfs_throttled_seconds_total ,它表示自此容器啟動以來已為它節(jié)流了多少秒的CPU。如果我們在1000m配置下遵守此指標,則應該在開始時看到很多節(jié)流,然后在幾分鐘后穩(wěn)定下來。我們使用此配置進行了部署,這是Prometheus中所有Pod的 container_cpu_cfs_throttled_seconds_total 圖表:

正如預期的那樣,在容器啟動的前5到7分鐘內(nèi)會有很多節(jié)流--通常在500秒到1000秒之間,但是隨后它穩(wěn)定下來,證實了我們的假設。
當我們使用3000m CPU配置進行部署時,我們觀察到下圖:
CPU節(jié)流幾乎可以忽略不計(幾乎所有Pod不到4秒),這就是部署順利進行的原因。
Take 4: 配置 Burstable Qos
盡管我們發(fā)現(xiàn)了造成此問題的瓶頸,但從成本方面來看,該解決方案(增加CPU請求/限制三倍)并不可行。此解決方案實際上可能比運行更多的Pod更糟糕,因為Kubernetes根據(jù)請求調(diào)度Pod,這可能會導致集群自動伸縮器頻繁觸發(fā),從而向集群添加更多節(jié)點。
再次思考這個問題:
在最初的預熱階段(持續(xù)幾分鐘),JVM需要比配置的限制(1000m)更多的CPU(〜3000m)。預熱后,即使CPU限制為1000m,JVM也可以充分發(fā)揮其潛力。 Kubernetes使用“請求”而不是“限制”來調(diào)度Pod。
一旦我們以清晰,平靜的心態(tài)閱讀問題陳述,答案就會出現(xiàn):Kubernetes Burstable QoS。
Kubernetes根據(jù)配置的資源請求和限制將QoS類分配給Pod。
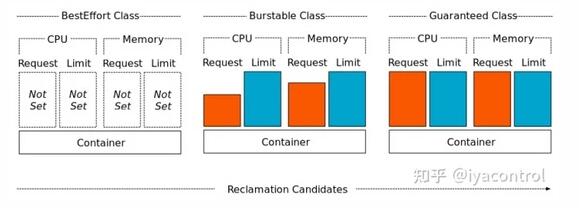
到目前為止,我們一直在通過使用相等值(最初都是1000m,然后都是3000m)指定請求和限制來使用保證的QoS類。盡管QoS保證有其好處,但在整個Pod生命周期的整個周期中,我們不需要3個CPU的全部功能,我們只需要在最初的幾分鐘內(nèi)使用它即可。 Burstable QoS類就是這樣做的。它允許我們指定小于限制的請求,例如
- resources:
- requests:
- cpu: 1000m
- memory: 2000Mi
- limits:
- cpu: 3000m
- memory: 2000Mi
由于Kubernetes使用請求中指定的值來調(diào)度Pod,因此它將找到具有1000m備用CPU容量的節(jié)點來調(diào)度此Pod。但是,由于此限制在3000m處要高得多,因此,如果應用程序在任何時候都需要超過1000m的CPU,并且該節(jié)點上有可用的CPU備用容量,則不會在CPU上限制應用程序。如果可用,它可以使用長達3000m。
最后,是時候檢驗假設了。我們更改了資源配置并部署了應用程序。而且有效!我們再進行了幾次部署,以測試我們是否可以重復結(jié)果,并且該結(jié)果始終如一。此外,我們監(jiān)控了 container_cpu_cfs_throttled_seconds_total 指標,這是其中一種部署的圖表:
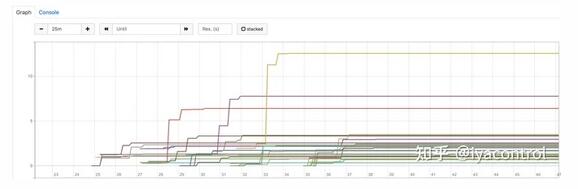
如我們所見,此圖與3000m CPU的“保證的QoS”設置非常相似。節(jié)流幾乎可以忽略不計,它證實了具有Burstable QoS的解決方案有效。
結(jié)論
Kubernetes資源限制是一個重要的概念,我們在所有基于Java的服務中實施了該解決方案,并且部署和自動擴展都可以正常工作,沒有任何問題。
以下三個關鍵點需要大家注意:
- container_cpu_cfs_throttled_seconds_total