大數據全系技術概覽
什么是大數據?
大數據(big data),指無法在一定時間范圍內用常規軟件工具進行捕捉、管理和處理的數據集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的信息資產。
在維克托·邁爾-舍恩伯格及肯尼斯·庫克耶編寫的《大數據時代》中大數據指不用隨機分析法(抽樣調查)這樣捷徑,而采用所有數據進行分析處理。大數據的5V特點(IBM提出):Volume(大量)、Velocity(高速)、Variety(多樣)、Value(低價值密度)、Veracity(真實性)。
大數據應用現狀

大數據技術共性
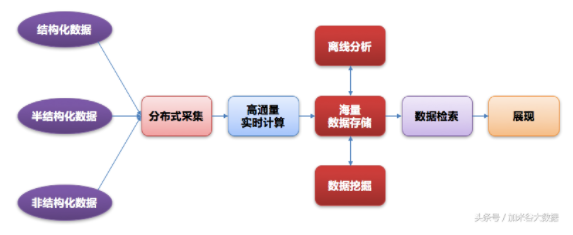
業界主流大數據技術框架
- 磁盤存儲HDFS、HBASE、S3、Cassandra、MongoDB、Redis
- 內存存儲Alluxio 、Redis
- 數據分析Spark(SQL、Streaming、MLlib、GraphX)、Storm、MapReduce、Mahout、Hive、Pig
- 分步式協調服務ZooKeeper
- 集群系統監控CDH-CMS, Metrics, Grafana、Ambari
- 消息總線kafka、ActiveMQ、Apollo、 Redis
- 索引系統Solr、Lucene、ElasticSearch
大數據組件應用分類
- 數據采集flume、kafka connector、sqoop、socket、sftp、mina
- 實時處理Spark Streaming、Kafka Streams、Storm、Samza、Flink
- 數據存儲HDFS、HBASE、S3、Cassandra、MongoDB、Redis、Solr、ElasticSearch
- 離線處理Spark SQL、Hive、Map Reduce、Pig、Impala
- 交互式查詢Drill、PresTO、Kylin
- 數據展現Echarts、Tableau、d3js
大數據組件簡介
1、Hadoop是Apache開源組織的一個分布式計算框架,提供了一個分布式文件系統 (HDFS)、MapReduce分布式計算及統一資源管理框架(Yarn)的軟件架構。
- 為大規模數據的存儲提供解決方案(HDFS);
- 解決大規模分步式計算( MapReduce );
- 作為其周邊軟件Hbase、Hive、Pig、Mahout等的基礎平臺。

2、HBase是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化存儲集群。
- 解決海量數據的存儲;
- 解決隨機、實時讀寫大數據;
- 提供簡化訪問HDFS的編程接口。
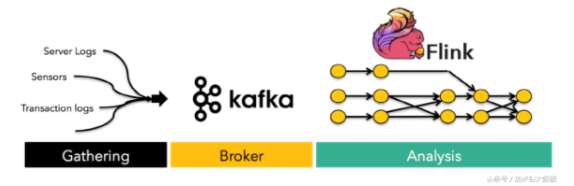
3、kafka是Apache旗下的一個高性能,高吞吐量的分步式消息總線系統。
- 分布式系統相互通信;
- 數據復制、同步;
- 日志同步;
- Delay Queue;
- 廣播通知。

4、Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供簡單的sql查詢功能,可以將sql語句轉換為MapReduce任務進行運行。 其優點是學習成本低,可以通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。
- 解決海量數據的存儲;
- 解決大規模數據的分析:SQL。

5、MongoDB 是一個高性能,開源,無模式的文檔型數據庫,它在許多場景下可用于替代傳統的關系型數據庫或鍵/值存儲方式。MongoDB不支持SQL,但有自己功能強大的查詢語法。MongoDB使用BSON作為數據存儲和傳輸的格式。BSON是一種類似JSON的二進制序列化文檔,支持嵌套對象和數組。
- 解決海量數據在線存儲;
- 許多情況下可以代替傳統關系數據庫;
- 代替鍵/值存儲方式。

6、Redis是一個開源的使用ANSI C語言編寫、支持網絡、可基于內存亦可持久化的日志型、Key-Value數據庫,并提供多種語言的API。從2010年3月15日起,Redis的開發工作由VMware主持。從2013年5月開始,Redis的開發由Pivotal贊助。
7、Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是——Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
8、Storm是一個分布式的、容錯的實時計算系統。使用Storm進行實時大數據分析。
9、Flink 是可擴展的批處理和流式數據處理的數據處理平臺,設計思想主要來源于Hadoop、MPP數據庫、流式計算系統等,支持增量迭代計算。
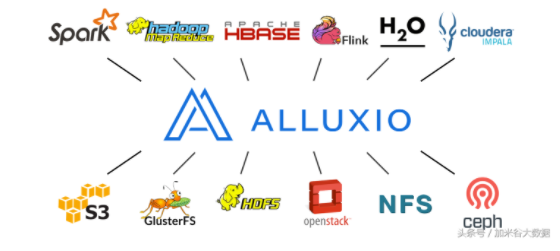
10、Alluxio A memory speed virtual distributed storage. Alluxio是一個高容錯的內存分布式文件系統,允許文件以內存的速度在集群框架中進行可靠的共享。典型特點就是加速讀寫數據的速度。
11、ElasticSearch是一個基于Lucene的搜索服務器。它提供了一個分布式多用戶能力的全文搜索引擎,基于RESTful web接口。其典型特點是全文快速檢索。