我嘞個去,慢查詢竟把系統搞崩了
本文轉載自微信公眾號「碼農私房話」,作者GoQeng 。轉載本文請聯系碼農私房話公眾號。
通常情況下,SQL 慢查詢一般只會導致應用服務響應變慢,但在去年雙十一活動時,我碰到了一個慢查詢把整個網站搞崩潰的問題。

慢查詢請求流程
案發現場
在去年雙十一晚,我突然收到產品經理的“催魂電話”并告知:整個網站的頁面一直在轉菊花,無法顯示數據,嚇得我立馬掏出電腦。
登錄服務器后竟發現服務內存占用率接近 100%,CPU 長期負荷高,我迅速地檢查是否代碼中出現死循環、大對象內存泄露等問題,但經過排查發現代碼是正常。
接著使用 jstatck pid 命令把線程堆棧信息 dump 出來,發現很多業務線程均處于 BLOCKED 狀態,同時也用 jstat -gcutil 觀察到 FULL GC 相當頻繁。
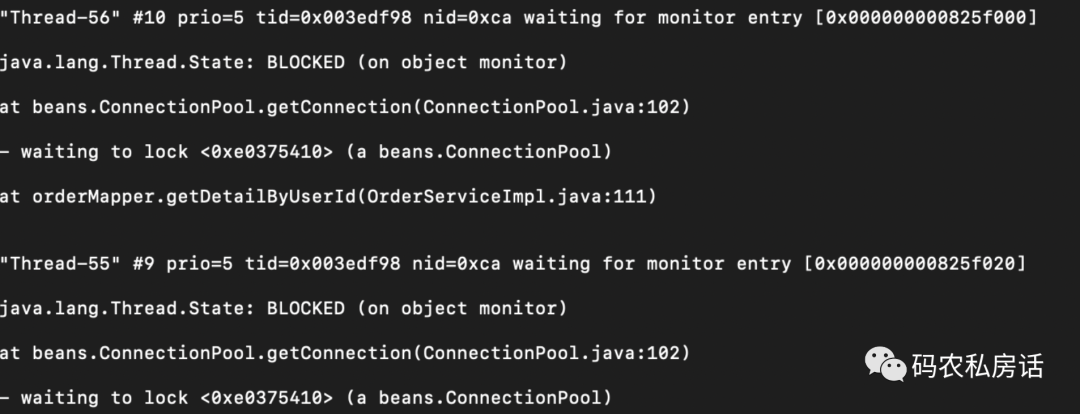
jstack 線程堆棧
經分析 dump 文件的內容及代碼,發現是線程無法獲取數據庫連接,大量處于等待狀態。
隨后使用 show processlist 命令發現某個 SQL 查詢耗時接近 10s 多,查詢的表數據量約在 1500W 左右。
我迫不及待地分析了慢 SQL select * from t_order where merchant_id= 1349865679 limit 0 10; 從表面看起來似乎用到了索引,可是為什么掃描到行還是這么多呢?
我就去看看表結構,期望能從中找到點有價值的東西,通過 show index from t_order;后發現以下有用的信息:

從上述結果中看到 merchant_id 索引的離散程度還算大,它的 Cardinality 值接近于 PRIMARY 的值,說明是比較正常的。
既然 merchant_id 索引沒問題,那么猜想就是使用姿勢不對的問題,我再通過 explain select * from t_order WHERE merchant_id= 1349865679 limit 0,10; 分析運行的SQL,發現確實索引沒生效。

最后經過耐心地對比代碼與 SQL 后,發現 SQL 中 merchant_id 傳的是整形,而數據庫實際上是字符串,于是我更改字段值為字符串,再次執行 explain select * from t_order WHERE merchant_id= '1349865679' limit 0,10; ,發現索引居然生效了。

此時我自信不疑,就是字段類型轉換導致的慢查詢,MySQL 不會自動幫我們做字段值類型轉換,定位出原因后,剩下只需要把字段的值改為字符串就可以了。
慢查詢會造成系統奔潰?
1、TCP 連接、端口耗盡,無法響應請求
首先我們先看看請求的流程:

從上述圖可發現,用戶的請求在服務器等待數秒后才向數據庫發起執行命令,而當時雙十一活動火爆,請求量高,導致數據庫連接耗盡,大量請求阻塞在服務器上,同時系統不斷地創建 TCP 連接,這些連接直至整個請求結束后才會釋放、銷毀。因此,當堆積大量請求無法及時處理時,則出現服務無法響應,進一步惡化為資源掛占。
2、對象在堆內存無法回收,導致內存不足
相信大家知道,每個用戶發出請求、執行邏輯時都需分配 JVM 內存,當前面的請求線程處于阻塞時,后面又越來越多新請求不斷申請內存分配,但舊請求中的對象無法回收并釋放內存,最終導致內存暴漲、系統響應緩存,進一步演化為系統奔潰,整個請求過程如下:
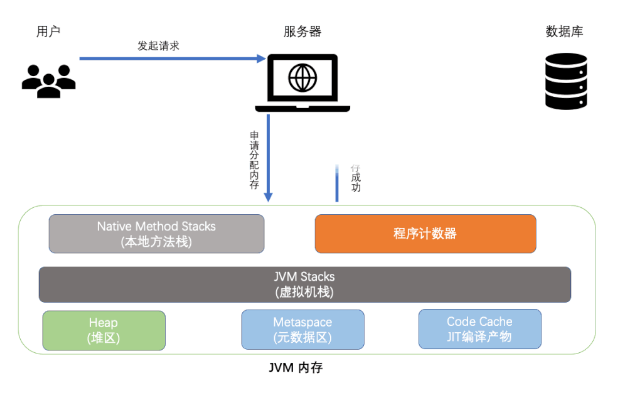
請求時線程申請資源流程
為什么會出現慢查詢?
在遇到慢查詢的情況時, SQL 編寫問題是最常見的因素,但實際上導致慢 SQL 有很多因素,甚至包括硬件和 MySQL 本身的 Bug 等,以下情況都有可能導致慢 SQL 的出現:
- SQL 編寫問題
- 鎖競爭激烈
- 業務實例相互干繞,爭用 IO/CPU 資源
- 服務器硬件配置
- MySQL Bug
而本次的問題是屬于 SQL 編寫導致,其根本原因是索引使用不當,查詢時進行全表掃描。
如何優化 SQL 編寫的慢查詢
針對 SQL 編寫導致的慢查詢,正確地使用索引就能加快查詢速度,避免全表掃描。
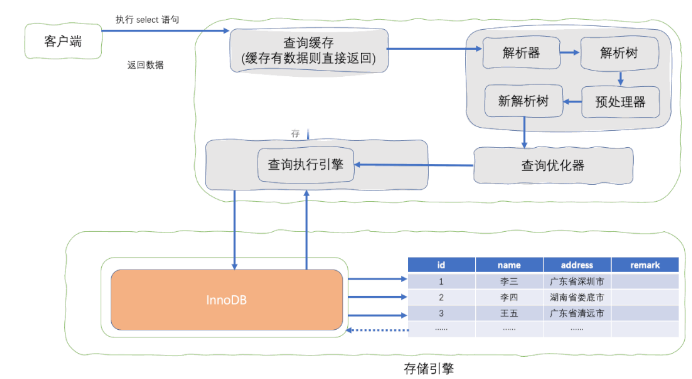
SQL 全表掃描數據流程
然而在編寫 SQL 時需要注意與索引相關的一些規則:
- 字段類型轉換導致索引失效,如字符串類型的不用引號,數字類型的用引號等,這可能使索引失效導致全表掃描;
- MySQL 不支持函數轉換,因此索引字段上不能加函數,否則這將用不到索引;
- 不在索引字段上做計算,對于需要計算的字段,可考慮將計算方法放在“=”后面;
- like 模糊查詢,一般禁止使用 % 前導,防止索引失效,如 like %liew;
- 不使用 select *,應按需加載需要的字段,查詢無用的列在數據傳輸和解析綁定過程中會增加網絡IO及CPU的開銷;
- 排序請盡量使用升序 ,因為倒序多了文件排序操作,執行效率變低,而 MySQL 8 開始支持降序索引解決排序性能問題;
- 盡量使用 union 代替 or,使用 or 可能會導致放棄使用索引而全表掃描;
- 最左匹配原則,索引是有順序的,查詢條件中缺失索引列之后的,其他條件都不會走索引,比如(a, b, c)索引,只使用b, c索引,就不會走索引;
- 在 order by / group by 子查詢的字段盡量建立索引,減少文件排序;
除了上述索引使用規則外,在編寫 SQL 時還需要特別注意一下幾點:
- 盡量規避大事務的 SQL,大事務的 SQL 會影響數據庫的并發性能及主從同步;
- 刪除表所有記錄請使用 truncate,而不用 delete,因為 truncate 執行時不會生成 UNDO 信息;
- 在 InnoDB 引擎上請謹慎使用 select count(*) 語句,該統計可能會全表掃描數據,而 MyISAM內置了一個計數器可直接獲取總數;
- 慎用 oder by rand(),因為 rand() 放在 order by 子句中會被執行多次,效率很低;
- 負向查詢一般都不會走索引,如 !=, <>, not in, not like等;
- 刪除不再使用或很少使用的索引,從而減少索引對更新操作的影響;
避免、發現慢查詢的措施
針對 SQL 編寫導致的慢查詢,正確地使用索引能加快查詢速度,避免全表掃描。
在工作中,每個公司使用 MySQL 的版本可能都大不相同,總會存在一些莫名其妙、不確定的問題,因此為了驗證索引的有效性,推薦把主要的 SQL 都通過 explain 命令查看一下執行計劃,是否會用到索引。
- explain select * from t_order WHERE merchant_id= '1349865679' limit 0 , 10;

然而 explain 工具分析的結果只是 MySQL 評估反饋的執行計劃,最終還是依賴 MySQL 執行引擎會根據一定算法落地:
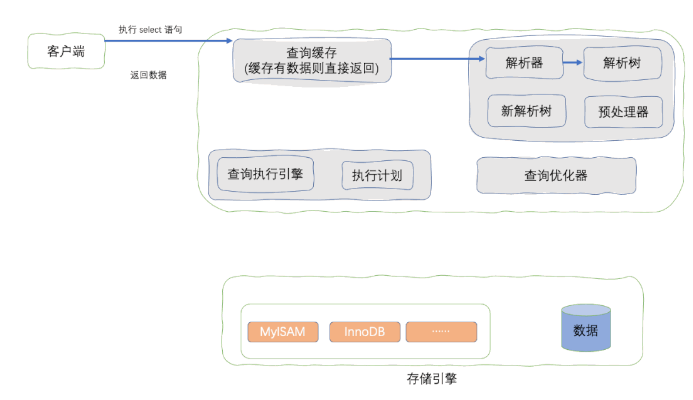
SQL 執行流程
因此有可能 explain 分析的結果顯示索引生效,但實際執行 SQL 語句時卻是全表掃描。
這時候就需要開啟 MySQL 的慢查詢功能,再通過監控工具 Zabbix 或Grafana輔助及時發現慢查詢 SQL 、連接數過多等問題并告警 。
寫在最后
慢查詢的破壞力很大,輕則出現系統響應緩慢,重則導致系統癱瘓、無法使用。
因此在日常開發中,我們需合理地設計、使用索引,避免出現慢查詢,同時利用工具實時監控數據庫的連接數、慢查詢語句等,并建立告警機制,以便能主動地及時發現、定位問題,盡可能減少給客戶帶來的損失。