圣迭戈大學博士首次證明:Deepfake探測器并非牢不可破

研究人員表明,通過在每個視頻幀中插入被稱為對抗性樣本(adversarial examples )的輸入,探測器就可以被擊敗。對抗性的例子是稍微被操縱的輸入,會導致人工智能系統,如機器學習模型犯錯誤。此外,研究小組還發現,在視頻被壓縮后,這種攻擊仍然有效。
來自UC San Diego 的計算機工程專業博士生 Shehzeen Hussain 說:
我們的研究表明,對deepfake探測器的攻擊可能是對真實世界的威脅,更令人震驚的是,我們證明,即使不知道探測器使用的機器學習模型的內部工作原理,也有可能制造出非常robust的對抗樣本。

在deepfake中,主體的臉部被修改,以創造令人信服的真實事件當中的鏡頭,而這些事件從未真正發生過。
因此,典型的deepfakes探測器會將焦點集中在視頻中的人臉上: 首先跟蹤它,然后將裁剪后的人臉數據傳遞給神經網絡,由神經網絡來判斷這些人臉是真是假。
例如,眨眼在deepfakes中不能很好地復制,所以探測器將注意力集中在眼睛的運動上,以此作為確定假的一種方法。最先進的“deepfakes探測器”依靠機器學習模型來識別假視頻。
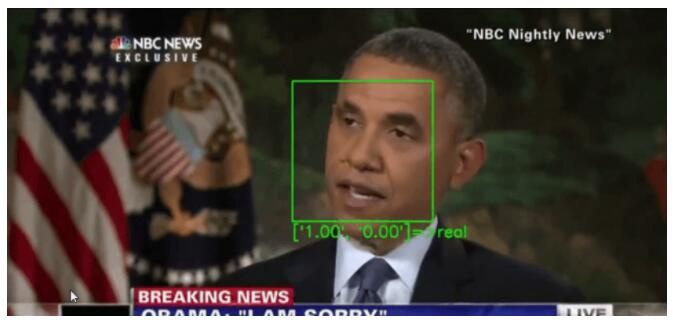
研究人員指出,虛假視頻在社交媒體平臺上的廣泛傳播引起了全世界的重大關切,尤其是影響了媒體的可信度。
“如果攻擊者對探測系統有一定的了解,他們就可以設計輸入信號,瞄準探測器的盲點,并繞過它,”論文的另一位合著者、來自加州大學圣地亞哥分校計算機科學專業的學生帕爾斯 · 尼卡拉(Paarth Neekhara)說。
研究人員為視頻畫面中的每一張臉創建了一個對抗性的樣本。但是,雖然標準的操作,例如視頻壓縮和調整大小,通常會從圖像中去除對抗性的樣本,這些例子是建立來承受這些過程的。
攻擊算法通過估計一組輸入轉換來實現這一點,模型將圖像排序為真或假。從那里,它使用這種估計轉換圖像的方式,使得即使在壓縮和解壓縮后,對抗性的圖像仍然有效。
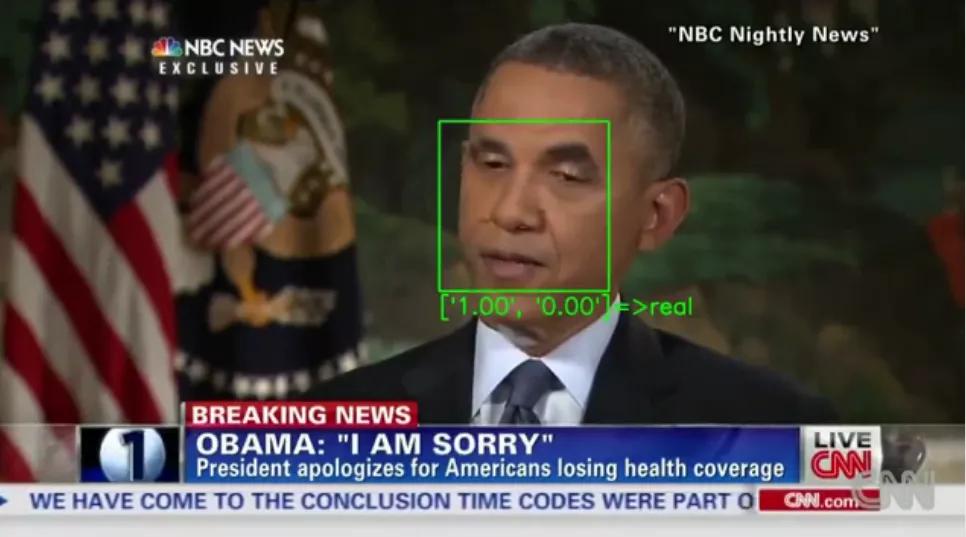
XceptionNet,一個deepfake探測器,將研究人員制作的對抗性視頻標記為真。
將修改后版本的面部插入到所有的視頻幀,然后對視頻中的所有幀重復這個過程,以創建一個deepfake的視頻。這種攻擊還可以應用于對整個視頻幀進行操作的探測器,而不僅僅是對面部。
成功率高
研究人員在兩個場景中測試了他們的攻擊: 一個場景中攻擊者可以完全訪問檢測器模型,包括人臉提取pipeline和分類模型的結構和參數; 另一個場景中攻擊者只能查詢機器學習模型來計算被分類為真或假的幀的概率。
在第一種情況下,對未壓縮視頻的攻擊成功率超過99% 。對于壓縮視頻,這個比例是84.96% 。在第二種情況下,對未壓縮視頻攻擊的成功率為86.43% ,壓縮視頻的成功率為78.33% 。
這是第一個展示了成功攻擊最先進的deepfake探測器的工作。

“為了在實踐中使用這些deepfake探測器,我們認為,有必要對這些探測器進行評估,以對抗一個了解這些防御的適應性對手,這個對手正在有意地試圖挫敗這些防御”,研究人員表示,“如果敵方對探測器有完全甚至部分的了解,目前最先進的deepfake探測方法可以很容易地被繞過。”
為了改進探測器,研究人員還推薦了一種類似于對抗性訓練的方法: 在訓練期間,一個適應性的對手繼續生成新的deepfake結果,這些假的結果可以繞過當前最先進的探測器; 為了檢測新的deepfake結果,探測器繼續改進。