













一個有關 V8 漏洞的細節分析 (一)
當開發人員決定使用新的Torque語言重新實現兩個CodeStubAssembler(CSA)函數時,V8中就會出現漏洞。這兩個函數用于在JavaScript中創建新的FixedArray和FixedDoubleArray對象,盡管新的實現乍看之下是有效的,但它們缺少一個關鍵組成部分:最大長度檢查,以確保新創建的數組的長度不會超過預定義的上限。
在一般人看來,這個缺失的長度檢查看起來很正常,但對于攻擊者來說,就可以利用了TurboFan的typer來獲取訪問權限中的一個非常強大的利用原語:數組,其長度字段遠大于其容量。該原語為攻擊者提供了V8堆上的越界訪問原語,這很容易導致代碼執行。
漏洞實現過程
如果要繼續,則需要構建V8版本8.5.51(提交64cadfcf4a56c0b3b9d3b5cc00905483850d6559),建議使用完整符號進行構建(修改args.gn并添加symbol_level = 2行)。
在x64.release目錄中,你可以使用以下命令以零編譯器優化來編譯發行版本:
- find . -type f -exec grep '\-O3' -l {} ";" -exec sed -i 's/\-O3/\-O0/' {} ";" -ls
如果你想繼續閱讀本博文中的一些代碼示例,我仍然建議你構建普通發行版(啟用編譯器優化)。如果不進行優化,某些示例將花費非常長的時間才能運行。
從上面鏈接的bugtracker中獲取概念證明。
2017年之前的V8
在2017年之前,許多JavaScript內置函數(Array.prototype.concat,Array.prototype.map等)都是用JavaScript本身編寫的,盡管這些函數使用了TurboFan(V8的推測性優化編譯器,稍后將進行詳細說明)。為了最大限度地發揮性能,它們的運行速度根本沒有使用本機代碼編寫的速度快。
對于最常見的內置函數,開發人員將以手寫匯編形式編寫非常優化的版本。之所以可行,因為ECMAScript規范(點擊查看示例)中對這些內置函數的描述非常詳細。但是,它有一個很大的缺點:V8針對大量平臺和體系結構,這意味著V8開發人員必須為每個體系結構編寫和重寫所有這些優化的內置函數。隨著ECMAScript標準的不斷發展和新語言函數的不斷標準化,維護所有這些手寫程序集變得非常繁瑣且容易出錯。
遇到此問題后,開發人員開始尋找更好的解決方案。直到TurboFan引入V8才找到解決方案。
CODESTUBASSEMBLER
TurboFan為低層指令帶來了跨平臺的中間表示(IR),V8團隊決定在TurboFan之上構建一個新的前端,他們將其稱為CodeStubAssembler。 CodeStubAssembler定義了一種可移植的匯編語言,開發人員可以使用該語言來實現優化的內置函數。最重要的是,可移植匯編語言的跨平臺性質意味著開發人員只需編寫一次內置函數即可。所有支持的平臺和體系結構的實際本機代碼都由TurboFan進行編譯,你可以在此處閱讀有關CSA的更多信息。
盡管這是一個很大的改進,但仍然存在一些問題。使用CodeStubAssembler的語言編寫最佳代碼需要開發人員積累很多專業知識。即使掌握了所有這些知識,仍然存在很多容易導致安全漏洞的非常規漏洞,這導致V8團隊最終編寫了一個稱為Torque的新組件。
Torque
Torque是基于CodeStubAssembler構建的語言前端,它具有類似TypeScript的語法,強大的類型系統和強大的漏洞檢查函數,所有這些使得它成為V8開發人員編寫內置函數的理想選擇。Torque編譯器使用CodeStubAssembler將Torque代碼轉換為有效的匯編代碼,它極大地減少了安全漏洞的數量,你可以在此處閱讀更多有關Torque的信息。
漏洞發生的原因
由于Torque仍相對較新,因此仍然需要重新實現大量的CSA代碼。其中包括用于處理創建新的FixedArray和FixedDoubleArray對象的CSA代碼,它們是V8中的“快”數組(“快”數組具有連續的數組后備存儲,而“慢”數組具有基于字典的后備存儲)。
漏洞利用
開發人員將CodeStubAssembler :: AllocateFixedArray函數重新實現為兩個Torque宏,一個用于FixedArray對象,另一個用于FixedDoubleArray對象:
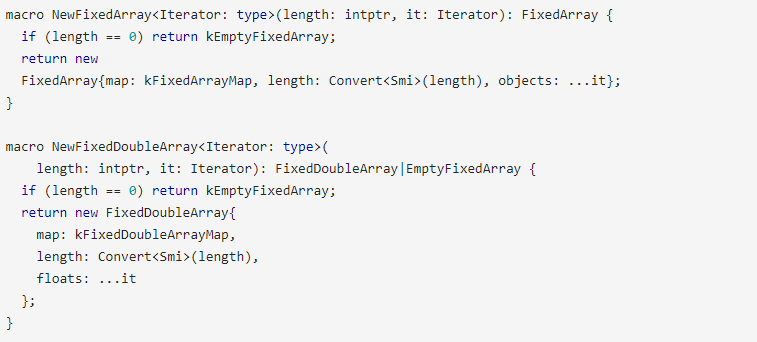
如果將上述函數與CodeStubAssembler :: AllocateFixedArray變體進行比較,則會發現缺少最大長度檢查。
NewFixedArray應確保返回的新FixedArray的長度小于FixedArray :: kMaxLength,即0x7fffffd或134217725。
同樣,NewFixedDoubleArray應該根據FixedDoubleArray :: kMaxLength(為0x3fffffe或67108862)檢查數組的長度。
在我們研究如何使用缺少的長度檢查之前,讓我們先了解一下Sergey是如何Trigger此漏洞的,因為它不像創建一個大于kMaxLength的新數組那樣簡單。
V8中的數組
現在,我們需要更多地了解V8中數組的表示方式。
內存中的數組
讓我們以數組[1、2、3、4]為例,并在內存中查看它。你可以通過運行帶有--allow-natives-syntax標志的V8,創建數組并執行%DebugPrint(array)來獲取其地址來實現此目的,使用GDB查看內存中的地址。
在V8中分配數組時,它實際上分配了兩個對象。請注意,每個字段的長度為4字節/ 32位:
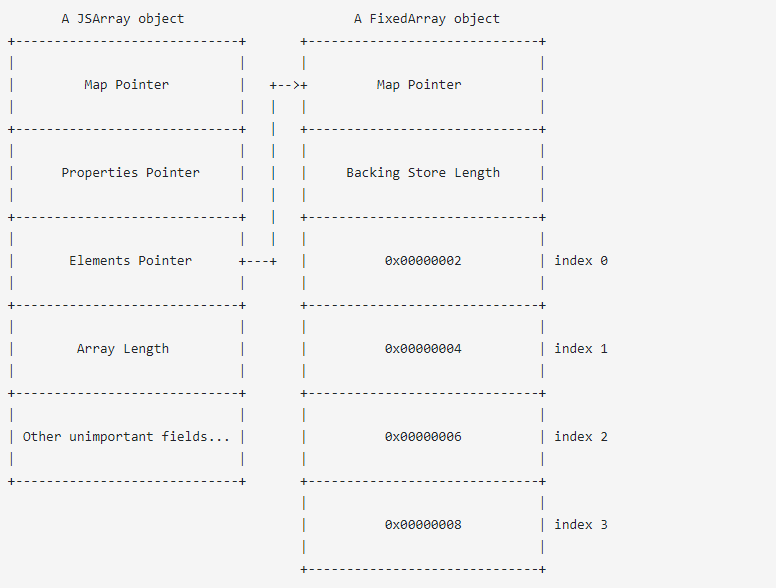
JSArray對象是實際的數組,它包含四個重要字段以及其他一些不重要的字段。
- 映射指針:這決定了數組的“形狀”,具體來說,它確定數組存儲哪種元素,以及其后備存儲對象是什么類型。在這種情況下,我們的數組存儲整數,后備存儲區為FixedArray。
- 屬性指針:指向存儲數組可能具有的任何屬性的對象。在本例中,數組除了長度以外沒有任何屬性,長度被內聯存儲在JSArray對象本身中。
- 元素指針:指向存儲數組元素的對象。這也稱為后備存儲,在本例中,后備存儲指向FixedArray對象,稍后會詳細介紹。
- 數組長度:這是數組的長度。在研究人員那發布的概念證明中,這是他將長度字段覆蓋為0x24242424,然后允許他進行越界讀取和寫入。
JSArray對象的元素指針指向后備存儲,這是一個FixedArray對象,有兩個關鍵的事情要記住:
- 不需要考慮FixedArray中的后備存儲長度,你可以將其覆蓋為任何值,但仍然無法讀取或寫入邊界。
- 每個索引存儲在數組的元素上,內存中值的表示形式取決于數組的“元素種類”,而數組的“元素種類”則取決于原始JSArray對象的映射。在本例中,這些值是一個小的整數,它們是31位整數,其最低位設置為零。 1表示為1 << 1 = 2,2表示為2 << 1 = 4,依此類推。
元素種類
V8中的數組也具有“元素種類”的概念,你可以在此處找到所有元素種類的列表,但所有表的基本思想都是一樣的:在V8中每次創建數組時,都會用元素種類標記它,該種類定義了數組包含的元素類型。最常見的三種元素如下:
PACKED_SMI_ELEMENTS:數組被壓縮并且僅包含Smis(31位小整數,第32位設置為0)。
PACKED_DOUBLE_ELEMENTS:與上面相同,但為雙精度(64位浮點值)。
PACKED_ELEMENTS:與上面相同,但數組僅包含引用。這意味著它可以包含任何類型的元素(整數,雙精度數,對象等)。
數組也可以在元素類型之間進行轉換,但是轉換只能針對更通用的元素類型,而不能針對更具體的元素類型。例如,具有PACKED_SMI_ELEMENTS類型的數組可以轉換為HOLEY_SMI_ELEMENTS類型,但不能轉換為HOLEY_SMI_ELEMENTS類型,即填充已經有孔的數組中的所有孔都不會導致轉換為壓縮元素類型的變體。
下面的圖表展示了最常見的元素類型的轉換格:
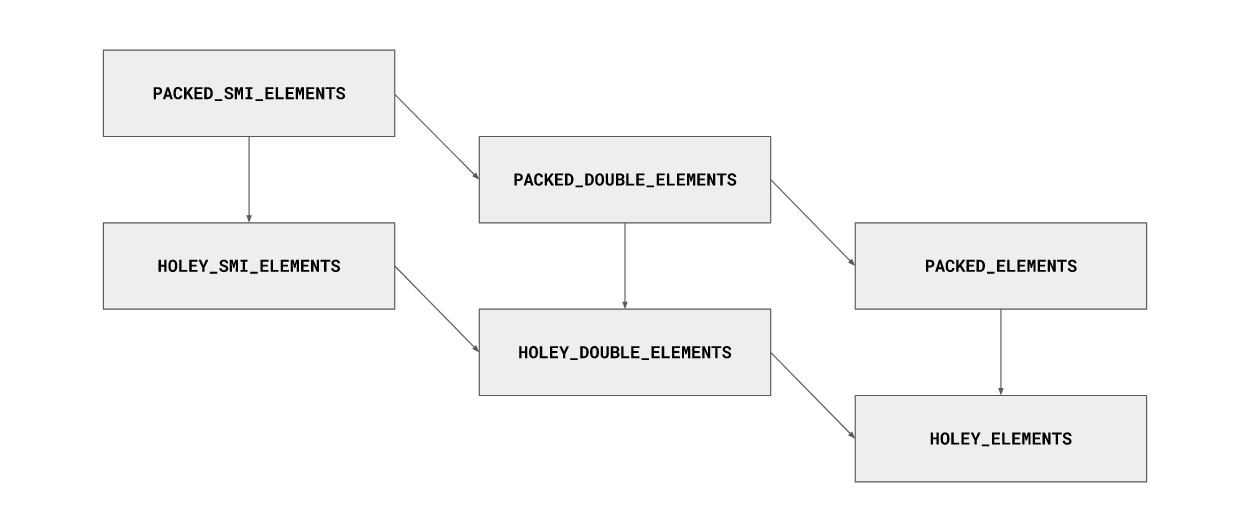
我們實際上只關心與元素類型有關的兩件事:
- SMI_ELEMENTS和DOUBLE_ELEMENTS類型的數組將其元素存儲在連續的數組后備存儲中,作為它們在內存中的實際表示形式。例如,數組[1.1、1.1、1.1]會將0x3ff199999999999a存儲在內存中三個元素的連續數組中(0x3ff199999999999a是1.1的IEEE-754表示形式)。另一方面,PACKED_ELEMENTS類型的數組將存儲對HeapNumber對象的三個連續引用,這些引用又包含1.1的IEEE-754表示形式。還有基于字典的備份存儲的元素種類,但這不是本文的重點。
- 因為SMI_ELEMENTS和DOUBLE_ELEMENTS類數組的元素大小不同(Smis是31位整數,而雙精度是64位浮點型值),所以它們也具有不同的kMaxLength值。
概念驗證
Sergey提供了兩個概念證明:第一個為我們提供了一個數組,類型為HOLEY_SMI_ELEMENTS類型,長度為FixedArray :: kMaxLength + 3,而第二個為我們提供了一個數組,類型為HOLEY_DOUBLE_ELEMENTS類型,長度為FixedDoubleArray :: kMaxLength + 1。他僅利用第二個概念證明來構造最終的越界訪問原語。
兩種概念證明都使用Array.prototype.concat來首先獲得一個數組,該數組的大小恰好小于相應元素類型的kMaxLength值。完成此操作后,將使用Array.prototype.splice向數組中添加更多元素,這會導致其長度增加到kMaxLength以上。之所以可行,是因為Array.prototype.splice的快路徑間接使用了新的Torque函數,如果原始數組不夠大,則會分配一個新數組。出于好奇,實現此目的的函數調用鏈可能如下:

你可能想知道為什么不能創建一個大小剛好低于FixedArray::kMaxLength的大數組并使用它。讓我們嘗試一下(使用優化的發行版等待的時間會短一些):
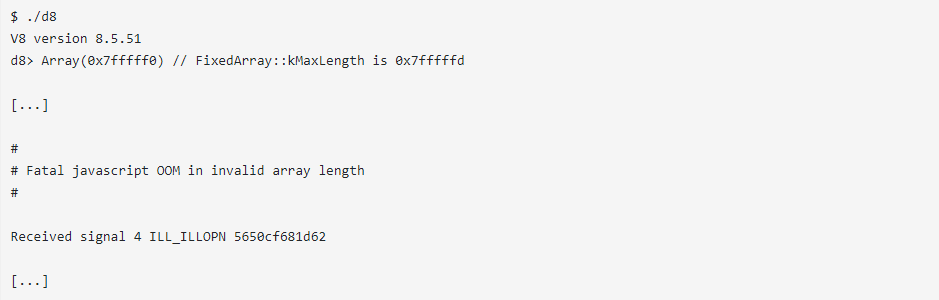
這不僅需要花費一些時間,而且還會收到OOM(內存不足)漏洞!發生這種漏洞的原因是,數組分配不會是一次性完成的。對AllocateRawFixedArray的調用很多,每個調用都分配一個稍大的數組。你可以通過在AllocateRawFixedArray上設置斷點,然后如上所述分配數組,來在GDB中看到這一點。我不完全確定為什么V8會這樣做,但是很多分配都會導致V8很快耗盡內存。
我的另一個想法是改用FixedDoubleArray :: kMaxLength,因為它要小得多(使用優化的發行版):

這確實有效,因為它會返回一個新的HOLEY_DOUBLE_ELEMENTS類型的數組,其長度設置為FixedDoubleArray :: kMaxLength + 1,因此可以使用它代替array .prototype.concat。我相信這樣做的原因是因為分配大小為0x3fffffd的數組所需的分配數量足夠小,以至于不會不會導致引擎進入OOM。
但是,此方法有兩個缺點:分配和填充龐大的數組需要花費大量時間,因此在漏洞利用中并不理想。另一個問題是,嘗試在內存受限的環境(例如舊手機)中以這種方式Trigger漏洞,可能會導致引擎運行OOM。
另一方面,Sergey的第一個概念證明在我的計算機上花費了大約2秒鐘,并且內存效率很高。以下是具體分析過程。
第一個概念證明
第一個概念證明如下,請確保你使用優化的發行版版本來運行它,否則將需要很長時間才能完成:

讓我們一步一步來分析,在[1]的位置,創建了一個大小為0x80000的數組,并使用1填充。這種大小的數組需要分配大量內存,但幾乎沒有使引擎成為OOM的條件。由于數組最初是空的,因此它得到的是HOLEY_SMI_ELEMENTS類型,即使將其填充為1也會保留該元素的類型。
我們稍后會回到[2],但是在[3]中,使用0xff元素創建了一個新的args數組,每個元素都被設置為在[1]處創建的數組。這使args數組總共為0xff * 0x80000 = 0x7f80000個元素。在[4]處,將另一個大小為0x7fffc的數組壓入args數組,這使其總數為0x7f80000 + 0x7fffc = 0x7fffffc個元素,0x7fffffc僅比FixedDoubleArray :: kMaxLength = 0x7fffffd小1。
在[5],Array.prototype.concat.apply將args數組中的每個元素連接到空數組[],你可以在此處閱讀有關Function.prototype.apply()如何工作的更多信息,但它實際上將args視為參數數組,并將每個元素連接為最終的數組。我們知道元素總數為0x7fffffc,因此最終數組將具有那么多元素。這種連接發生得比較快(在我的設備上大約需要2秒鐘),盡管它比我前面演示的簡單地創建數組要快得多。
最后,在[6]處,Array.prototype.splice向該數組追加了4個額外的元素,這意味著其長度現在為0x8000000,即FixedArray :: kMaxLength + 3。
唯一需要說明的是[2],其中將屬性添加到原始數組。要了解這一點,你必須首先了解幾乎所有V8內置函數的約定是有一個快路徑和一個慢路徑。在Array.prototype.concat的情況下,采用慢路徑的一種簡單方法是向要連接的數組添加屬,快路徑具有以下代碼:

可以看到,快路徑檢查確保最終數組的長度不超過kMaxLength值。由于FixedDoubleArray::kMaxLength是FixedArray::kMaxLength的一半,所以上述概念證明將永遠不會通過此檢查。隨意嘗試在不使用array.prop = 1的情況下運行代碼;看看會發生什么!
另一方面,慢路徑(Slow_ArrayConcat)沒有任何長度檢查(但是,如果長度超過FixedArray :: kMaxLength,它仍然會崩潰并產生致命的OOM漏洞,因為它調用的其中一個函數仍然會檢查長度。這就是為什么研究者會使用慢路徑的原因,因為可以繞過快路徑中存在的檢查。
第二個概念證明(第一部分)
盡管第一個概念證明演示了漏洞,并且可以用于利用(在第二個概念證明中,你只需稍微修改一下trigger函數),但它需要幾秒鐘才能完成,這可能也不太理想。Sergey選擇使用HOLEY_DOUBLE_ELEMENTS類數組。這可能是因為FixedDoubleArray::kMaxLength值明顯小于它的FixedArray變體,從而導致更快的Trigger。如果你理解了第一個概念證明,,那么第二個概念證明的第一部分的以下注釋版本就很好理解了:

此時,giant_array的長度為0x3ffffff,即FixedDoubleArray :: kMaxLength +1。現在的問題是,我們如何在漏洞利用程序中使用此數組?我們沒有任何有用的原語,因此我們需要找到引擎的其他部分,這些部分的代碼取決于數組長度不能超過kMaxLength值。
對于大多數研究人員來說,該漏洞本身確實很容易被發現,因為你只需要將函數的新的Torque實現與舊的實現進行比較即可。盡管知道如何利用它,但需要對V8本身有更深入的了解。 Sergey采取的利用途徑利用了V8的推測性優化編譯器TurboFan,它需要自己引入。
本文翻譯自:https://www.elttam.com/blog/simple-bugs-with-complex-exploits/#content




















