













Protobuf vs CBOR:新一代的二進制序列化格式
在以前的文章中,我們講到了什么時候用 Yaml,什么時候用 JSON,什么時候用 Protobuf:
- 人寫機器讀,用 Yaml
- 機器寫,人讀,用 JSON
- 機器寫,機器讀,用 JSON 或者 Protobuf
JSON 作為幾乎每一個語言都支持的序列化格式,在很多地方都得到了廣泛應用。但有個弊端,JSON 里面充斥了大量的大括號、中括號和雙引號,導致冗余的字符太多,數據量非常大,在對傳輸速度有高要求的場景下,數據量越大,占用的傳輸帶寬就越大,單位時間傳輸的數據也就越少。
Protobuf 是 Google 開發的一個二進制序列化格式,與 JSON 相比,Protobuf 的數據非常精簡,甚至連數據的字段名都沒有。例如有這樣一段數據:
- a = {'name': 'kingname', 'salary': 99999, 'address': '上海', 'skill': ['Python', '爬蟲', 'Golang']}
如果用 Protobuf 來表示,那么數據的二進制形式是這樣的:
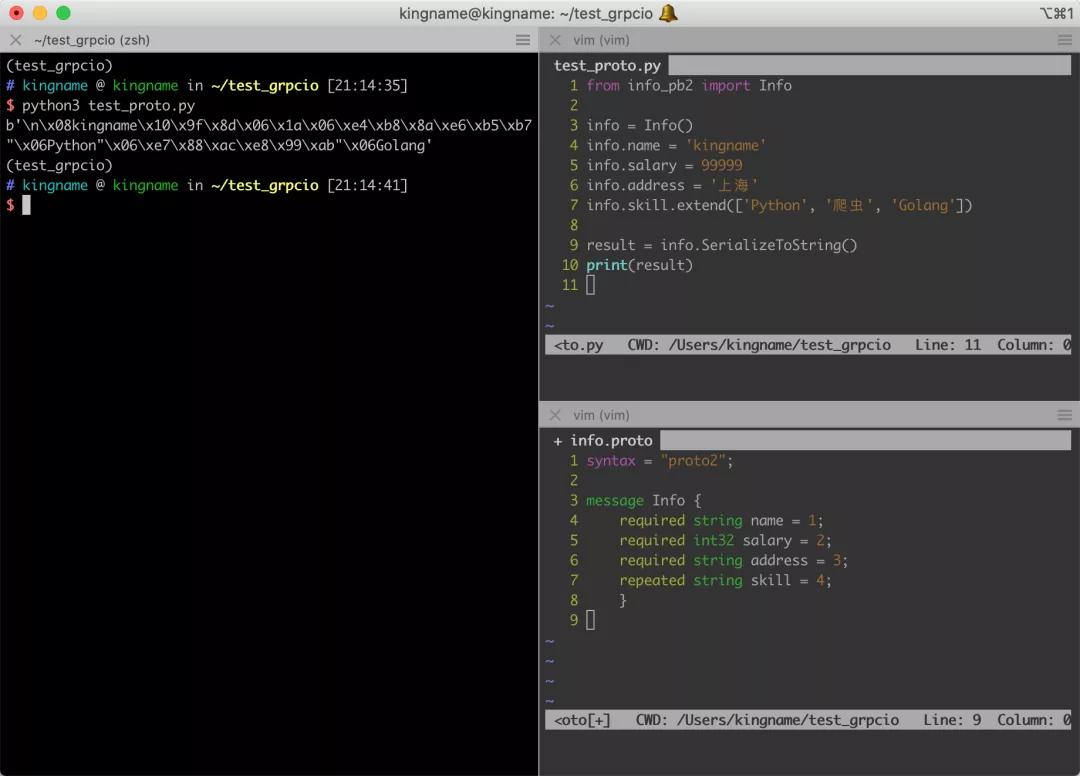
這個二進制數據只有值,但沒有字段名,所以要解析這些數據,必須在代碼里面額外把字段名帶上。所以需要定義一個xxx.proto文件,在里面標記每一個字段的信息。在任何時候任何語言中,需要序列化和反序列化的地方,都要提前使用protoc命令,基于這個.proto文件,生成一個xxx_pb2文件,通過從這個 xxx_pb2文件中導入數據對象來對數據進行處理。
因此,我們說,proto 格式,雖然確實精簡了網絡中的數據傳輸量,但卻給開發者增加了相當大的工作量。
而最近,又新出來一種二進制序列化格式:CBOR,它的數據比 JSON 小,但是開發起來又比 Protobuf 簡單得多。
我們來看看使用 CBOR 對上面的數據進行序列化操作。首先在 Python 中安裝CBOR:
- python3 -m pip install cbor2
安裝完成以后,我們來對數據進行序列化:
- import cbor2
- a = {'name': 'kingname', 'salary': 99999, 'address': '上海', 'skill': ['Python', '爬蟲', 'Golang']}
- result = cbor2.dumps(a)
- print(result)
運行效果如下圖所示:
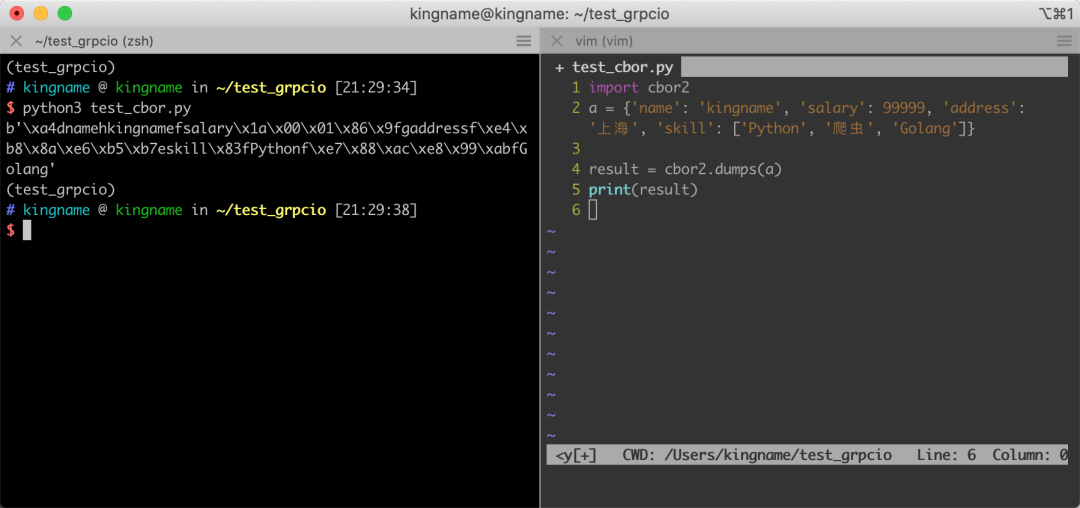
注意,打印出來的是二進制數據,不是字符串。可以看到,數據是自帶字段名的,字段名與值之間會有特殊的字符進行分割,CBOR 能夠自動識別這些特殊符號,從而區分字段名和字段值。
經過我的測試,一個150MB 的大 JSON文件,讀入到內存,然后重新通過 CBOR 序列化以后寫文件,這個文件大小可以縮減到60MB 左右。雖然壓縮比例不如 Protobuf,可讀性不如 JSON;但是壓縮比例比 JSON 高,可讀性比 Protobuf 好,而且幾乎不增加額外工作量。
大家在寫微服務或者網站前后端通信的時候,可以考慮試一試 CBOR — Concise Binary Object Representation | Overview[1]。
參考資料
[1]CBOR — Concise Binary Object Representation | Overview: https://cbor.io/
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。
















