神奇的Google二進制編解碼技術:Protobuf
計算機網絡編程中一個非常基本的問題:該怎樣表示client與server之間交互的數(shù)據(jù),在往下看之前先想一想這個問題。
共識與協(xié)議
這個問題可不像看上去的那樣簡單,因為client進程和server進程運行在不同的機器上,這些機器可能運行在不同的處理器平臺、可能運行在不同的操作系統(tǒng)、可能是由不同的編程語言編寫的,server要怎樣才能識別出client發(fā)送的是什么數(shù)據(jù)呢?就像這樣:

client給server發(fā)送了一段數(shù)據(jù):
0101000100100001server怎么能知道該怎樣“解讀”這段數(shù)據(jù)呢?
顯然,client和server在發(fā)送數(shù)據(jù)之前必須首先達成某種關于怎樣解讀數(shù)據(jù)的共識,這就是所謂的協(xié)議。
這里的協(xié)議可以是這樣的:“將每8個比特為一個單位解釋為無符號數(shù)字”,如果協(xié)議是這樣的,那么server接收到這串二進制后就會將其解析為81(01010001)與33(00100001)。
當然,這里的協(xié)議也可以是這樣的:“將每8個比特為一個單位解釋為ASCII字符”,那么server接收到這串二進制后就將其解析為“Q!”。
可見,同樣一串二進制在不同的“上下文/協(xié)議”下有完全不一樣的解讀,這也是為什么計算機明明只認知0和1但是卻能處理非常復雜任務的根本原因,因為一切都可以編碼為0和1,同樣的我們也可以從0和1中解析出我們想要的信息,這就是所謂的編解碼技術。
實際上不止0和1,我們也可以將信息編碼為摩斯密碼(Morse code)等,只不過計算機擅長處理0和1而已。

扯遠了,回到本文的主題。
遠程過程調用:RPC
作為程序員我們知道,client以及server之間不會簡單傳遞一串數(shù)字以及字符這樣簡單,尤其在互聯(lián)網大廠后端服務這種場景下。
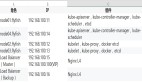
當我們在電商App搜索商品、打車App呼叫出租車以及刷短視頻時,每一次請求的背后在后端都涉及大量服務之間的交互,就像這樣:

完成一次客戶端請求gateway這個服務要調用N多個下游服務,所謂調用是說A服務向B服務發(fā)送一段數(shù)據(jù)(請求),B服務接收到這段數(shù)據(jù)后執(zhí)行相應的函數(shù),并將結果返回給A服務。
只不過對于服務A來說并不想關心網絡傳輸這樣的底層細節(jié),如果能像調用本地函數(shù)一樣調用遠程服務就好了,這就是所謂的RPC,經典的實現(xiàn)方式是這樣的:

RPC對上層提供和普通函數(shù)一樣的接口,只不過在實現(xiàn)上封裝了底層復雜的網絡通信,RPC框架是當前互聯(lián)網后端的基石之一,很多所謂互聯(lián)網后端的職位無非就是在此基礎之上堆業(yè)務邏輯。
本文我們不關心其中的細節(jié),這里我們只關心在網絡層client是怎樣對請求參數(shù)進行編碼、server怎樣對請求參數(shù)進行解碼的,也就是本文開頭提出的問題。
信息的編解碼
在思考怎樣進行編解碼之前我們必須意識到:
client和server可能是用不同語言編寫的,你的編解碼方案必須通用且不能和語言綁定
編解碼方法的性能問題,尤其是對時間要求苛刻的服務
首先,我們最應該能想到的就是以純文本的形式來表示。
純文本從來都是一種非常有友好的信息載體,為什么?很簡單,因為人類(我們)可以直接看懂,就像這段:
{
"widget": {
"window": {
"title": "Sample Konfabulator Widget",
"name": "main_window",
"width": 500,
"height": 500
},
"image": {
"src": "Images/Sun.png",
"name": "sun1",
"hOffset": 250,
"vOffset": 250,
},
}
}
是不是很清晰,一目了然,只要我們實現(xiàn)約定好文本的結構(也就是語法),那么client和server就能利用這種文本進行信息的編碼以及解碼,不管client和server是運行在x86還是Arm、是32位的還是64位的、運行在Linux上還是windows上、是大端還是小端,都可以無障礙交流。
因此在這里,文本的語法就是一種協(xié)議。

順便說一句,你都規(guī)定好了文本的語法,實際上就相當于發(fā)明了一種語言。
這里用來舉例用的語言就是所謂的Json,只不過json這種語言不是用來表示邏輯(代碼)而是用來存儲數(shù)據(jù)的。
Json就是這個老頭提出來的:

除了Json,另一種利用文本存儲數(shù)據(jù)的表示方法是XML,來一段感受下:
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
相對Json來說是不是就沒那么容易看懂了,Json出現(xiàn)后在web領域逐漸取代了XML。
當兩段數(shù)據(jù)量很少的時候——就像瀏覽器和服務端的交互,Json可以工作的非常好,這個場景就是這里:

在這里是json的天下。
但對于后端服務之間的交互來說就不一樣了,后端服務之間的RPC調用可能會傳輸大量數(shù)據(jù),如果全部用純文本的形式來表示數(shù)據(jù)那么不管是網絡帶寬還是性能可能都會差強人意。

在這種場景下,Json并不是最好的選項,主要原因之一就在于性能以及數(shù)據(jù)的體積。
我們知道,文本表示對人類是最友好的,對機器來說則不是這樣,對機器來說最好的還是01二進制。
那么有沒有二進制的編碼方法嗎?答案是肯定的,這就是當前互聯(lián)網后端中流行的protobuf,Google公司開源項目。
那么protobuf有什么神奇之處嗎?
假設client端想給server端傳輸這樣一段信息:“我有一個id,其值為43”,那么在XML下是這樣表示的:
<id>43</id>
數(shù)一數(shù)這這段數(shù)據(jù)占據(jù)了多少字節(jié),很顯然是11字節(jié);
而如果用json來表示呢?
{"id":43}
數(shù)一數(shù)這段數(shù)據(jù)占據(jù)了多少字節(jié),顯然是9字節(jié);
而如果用protobuf來表示呢? 是這樣的:
// 消息定義
message Msg {
optional int32 id = 1;
}
// 實例化
Msg msg;
msg.set_id(43);
其中Msg的定義看上去比Json和XML更加復雜了,但這些只是給人看的,這些還會被protbuf進一步處理,最終被編碼為:
082b也就是0x08與0x2b,這占據(jù)了多少字節(jié)呢?答案是2字節(jié)。
從json的9字節(jié)到protobuf的2字節(jié),數(shù)據(jù)大小減少了4倍多,數(shù)據(jù)量的減少意味著:
- 更少的網絡帶寬
- 更快的解析速度
那么protobuf是怎樣做到這一點的呢?
protobuf是怎樣實現(xiàn)的?
首先,我們來思考最簡單的情況,該怎樣表示數(shù)字。
你可能會想這還不簡單,統(tǒng)一用固定長度,比如用64個比特(8字節(jié)),這種方法可行,但問題是不論一個數(shù)字有多小,比方2,那么用這種方法表示2也需要占據(jù)64個比特(8字節(jié)):

明明只要一個字節(jié)就能表示而我們卻用了8個,前面的全都是0,這也太奢侈太浪費了吧。
顯然,在這里我們不能使用固定長度來表示數(shù)字,而需要使用變長方法來表示。
什么叫變長?意思是說如果數(shù)字本身比較大,那么其使用的比特位可以較多,但如果數(shù)字很小那么就應該使用較少的比特位來表示,這就叫變長,隨機應變,不死板。
那怎樣變長呢?
我們規(guī)定:對于每一個字節(jié)來說,第一個比特位如果是1那么表示接下來的一個比特依然要用來解釋為一個數(shù)字,如果第一個比特為0,那么說明接下來的一個字節(jié)不是用來表示該數(shù)字的。
也就是說對于每個8個比特(1字節(jié))來說,它的有效載荷是7個比特,第一個比特僅僅用來標記是否還應該把接下來的一個字節(jié)解析為數(shù)字。
根據(jù)這個規(guī)定假設來了這樣一串01二進制:
1010110000000010根據(jù)規(guī)定,我們首先取出第一個字節(jié),也就是:
10101100此時我們發(fā)現(xiàn)第一個比特位是1,因此我們知道接下來的一個字節(jié)也屬于該數(shù)字,將當前字節(jié)的1去掉就是:
0101100然后我們看下一個字節(jié):
00000010我們發(fā)現(xiàn)第一個bit為0,因此我們知道下一個字節(jié)不屬于該數(shù)字了。
接下來我們將解析到的0101100(第一個字節(jié)去掉第一個比特位)以及第二個字節(jié)0000010(第二個字節(jié)去掉第一個比特位)翻轉之后拼接到一起,這里之所以翻轉是因為我們規(guī)定數(shù)字的高位在后。
這個過程就是:
1010110000000010
-> 10101100 | 00000010 // 解析得到兩個字節(jié)
_ _
-> 0101100 | 0000010 // 各自去掉最高位
-> 0000010 | 0101100 // 兩個字節(jié)翻轉順序
0000010 + 0101100
-> 100101100 // 拼接
最后我們得到了100101100,這一串二進制表示數(shù)字300。
這種數(shù)字的變長表示方法在protobuf中被稱之為varint。
因此在這種表示方法下,如果數(shù)字較大,那么使用的比特就多,如果數(shù)字較小那么使用比特就少,聰明吧。
有的同學看到這里可能會問題,剛才講解的方法只能表示無符號數(shù)字,那么有符號數(shù)字該怎么表示呢?比如-2該怎么表示?
有符號數(shù)的表示
按照剛才變長編碼的思想,-2147483646使用的比特位應該比-2要少。
然而我們知道在計算機世界中負數(shù)使用補碼表示的,也就是說最高位(最左側的比特位)一定是1,假設我們使用64位來表示數(shù)字,那么如果我們依然用補碼來表示數(shù)字的話那么無論這個負數(shù)有多大還是多小都需要占據(jù)10個字節(jié)的空間。
為什么是10個字節(jié)呢?
不要忘了varint每個字節(jié)的有效負荷是7個比特,那么對于需要64位表示的數(shù)字來說就需要64/7向上取整也就是10個字節(jié)來表示。
這顯然不能滿足我們對數(shù)字變長存儲的要求。
該怎么解決這個問題呢?
既然無符號數(shù)字可以方便的進行變長編碼,那么我們將有符號數(shù)字映射稱為無符號數(shù)字不就可以了,這就是所謂的ZigZag編碼,是不是很聰明,就像這樣:
原始信息 編碼后
0 0
-1 1
1 2
-2 3
2 4
-3 5
3 6
... ...
2147483647 4294967294
-2147483648 4294967295
這樣我們就可以將有符號數(shù)字轉為無符號數(shù)字,接收方接收到該數(shù)據(jù)后再恢復出有符號數(shù)字。
現(xiàn)在數(shù)字的問題徹底解決了,但這僅僅是萬里長征第一步。
字段名稱與字段類型
對于任何一個有用的信息都包含這樣幾部分:
- 字段名稱
- 字段類型
- 字段值
就像C/C++中定義變量時:
int i = 100;
在這里,字段名稱就是i,字段類型是int,字段值是100。
剛才我們用varint以及ZigZag編碼解決了字段值表示的問題,那么該怎樣表示字段名稱和字段類型呢?
首先,對于字段類型還比較簡單,因為字段類型就那么多,protobuf中定義了6種字段類型:

對于6種字段類型我們使用3個比特位來表示就足夠了。
接下來比較有趣的是字段名稱該怎么表示呢?假設我們需要傳遞這樣一個字段:
int long_long_name = 100;
那么我們真的需要把“l(fā)ong_long_name”這么多字符通過網絡傳遞給對端嗎?
既然通信雙方需要協(xié)議,那么“l(fā)ong_long_name”這字段其實是client和server都知道的,它們唯一不知道的就是“哪些值屬于哪些字段”。
為解決這個問題,我們給每個字段都進行編號,比如通信雙方都知道“l(fā)ong_long_name”這個字段的編號是2,那么對于:
int long_long_name = 100;
這個信息我們只需要傳遞:
- 字段名稱:2 (2對應字段“l(fā)ong_long_name”)
- 字段類型:0 (0表示varint類型,參見上圖)
- 字段值:100
所以我們可以看到,無論你用多么復雜的字段名稱也不會影響編碼后占據(jù)的空間,字段名稱根本就不會出現(xiàn)在編碼后的信息中,so clever。
從宏觀上看
我們已經在protobuf中看到了數(shù)字以及字段名稱以及字段類型是怎么表示了,現(xiàn)在是時候從宏觀角度來看看多個字段該怎么編碼了。
從本質上講,protobuf被編碼后形成一系列的key-value,每個key-value對應一個proto中的字段。
也就是鍵值對:

其中value比較簡單,也就是字段值;而字段名稱和字段類型會被拼接成key,protobuf中共有6種類型,因此只需要3個比特位即可;字段名稱只需要存儲對應的編號,這樣可以就可以這樣編碼:
(字段編號 << 3) | 字段類型
假設server接收到了一個key為0x08,其二進制的表示為:
0000 1000
由于key也是利用varint編碼的,因此需要將第一個比特位去掉,這樣我的得到:
000 1000
根據(jù)key的編碼方式,其后三個比特位表示字段類型,即:
000也就是0,這樣我們知道該key的類型是Varint(第0號類型),而字段編號為抹掉后3個比特位的值,即:
0001這樣,我們就知道了該key對應的字段編號為1,得到編號我們就能根據(jù)編號找到對應的編號名稱。
嵌套數(shù)據(jù)
與Json和XML類似,protobuf中也支持嵌套消息,就像這樣:
message SubMsg {
optional int32 id = 1;
}
message Msg {
optional SubMsg msg = 1;
}
其實現(xiàn)也比較簡單,這依然遵循被編碼后形成一系列的key-value,只不過對于嵌套類型的key來說,其value是由子消息的key-value組成。

protobuf與編譯語言
與Json一樣,protobuf也是一門語言,兼具了文本的可讀性以及二進制的高效。
protobuf之所以能做到這一點就好比C語言與機器指令。
C語言是給程序員看的,可讀性好,而機器指令是給硬件使用的,性能好,編譯器會將C語言程序轉為機器可執(zhí)行的機器指令。
而protobuf也一樣,protobuf也是一門語言,會將可讀性較好的消息編碼為二進制從而可以在網絡中進行傳播,而對端也可以將其解碼回來。
在這里protobuf中定義的消息就好比C語言,編碼后的二進制消息就好比機器指令。
而protobuf作為事實上語言必然有自己的語法,其語法就是這樣:

怎么樣,還覺得編譯原理沒什么用嗎?
不理解編譯原理是不可能發(fā)明protobuf這種技術的。
總結
我在寫這篇文章時不斷感嘆,Google的這項技術節(jié)省了多少程序員的時間,同時我們也能看到這種基石般的技術依賴的底層原理卻非常古老:
- 信息的編解碼
- 編譯原理
怎么樣,這些是不是遠遠沒有IT界各種流行的技術聽上去時髦有趣,而正是這種樸素的技術支撐起了工業(yè)界,現(xiàn)在你也應該能明白底層技術的重要性了吧。