













如何評價一款App的穩定性和質量?
「崩潰」與「卡頓」、「異常退出」等一樣,是影響App穩定性常見的三種情況。相關數據顯示,當iOS的崩潰率超過0.8%,Android的崩潰率超過0.4%的時候,活躍用戶有明顯下降態勢。它不僅會造成關鍵業務中斷、用戶留存率下降、品牌口碑變差等負面影響,而且會直接帶來卸載和流失。也同時給開發者帶來不可小覷的資本損失。
那么,崩潰率低的App質量就高么?是否可以通過崩潰率直接判斷App的穩定性?
首先,衡量一個App質量好壞時我們需要定義一個統一的口徑,即哪些指標可以作為穩定性的評估口徑?以友盟+的U-APM定義的穩定率這個概念為例,評價一個App的穩定性和質量,一般從以下三點綜合考慮:
- 發生了崩潰,如java崩潰和Native崩潰,即用崩潰率這個指標來評估計算;
- 異常退出,如:low memory killer、任務列表中劃掉、系統異常、斷電、用戶觸發關機/重啟等,即用異常率這個指標來評估計算。
- 崩潰,也就是程序出現異常,導致程序退出。包括:
- Java崩潰,也就是在Java代碼中出現了未捕獲異常,導致程序異常退出。如:空指針異常、數組越界異常等。
- Native異常,也就是在Native代碼中,出現錯誤產生相應的signal信號,導致程序異常退出。如:訪問非法地址、地址對其 問題等。
Java崩潰的捕獲相對會簡單一些,Native崩潰的捕獲可能要求我們對系統底層知識要有一定的掌握。我們知道Android是基于Linux系統的,系統中的崩潰大多是由于編碼錯誤或硬件錯誤導致的。當系統遇到不可恢復的錯誤時會通過異常中斷的方式觸發異常處理流程,這些中斷的處理被統一為了信號量。當應用程序接收到某個信號量時會按照內核默認的動作處理,如Term、lgn、Core、Stop、Cont。同時我們也可以通過sigaction注冊接收信號來指定處理動作,比如捕獲崩潰信息等。當然捕獲過程中也會有一些困難點,尤其在極端環境中,比如棧溢出時,由于棧空間已經被用完,造成我們的信號處理函數沒法被調用,以至于無法捕獲到崩潰信息,這時我們需要考慮使用signalstack,使我們的信號處理函數可以在堆里面分配到一塊內存空間作為“可替換信號棧”來處理崩潰信息。
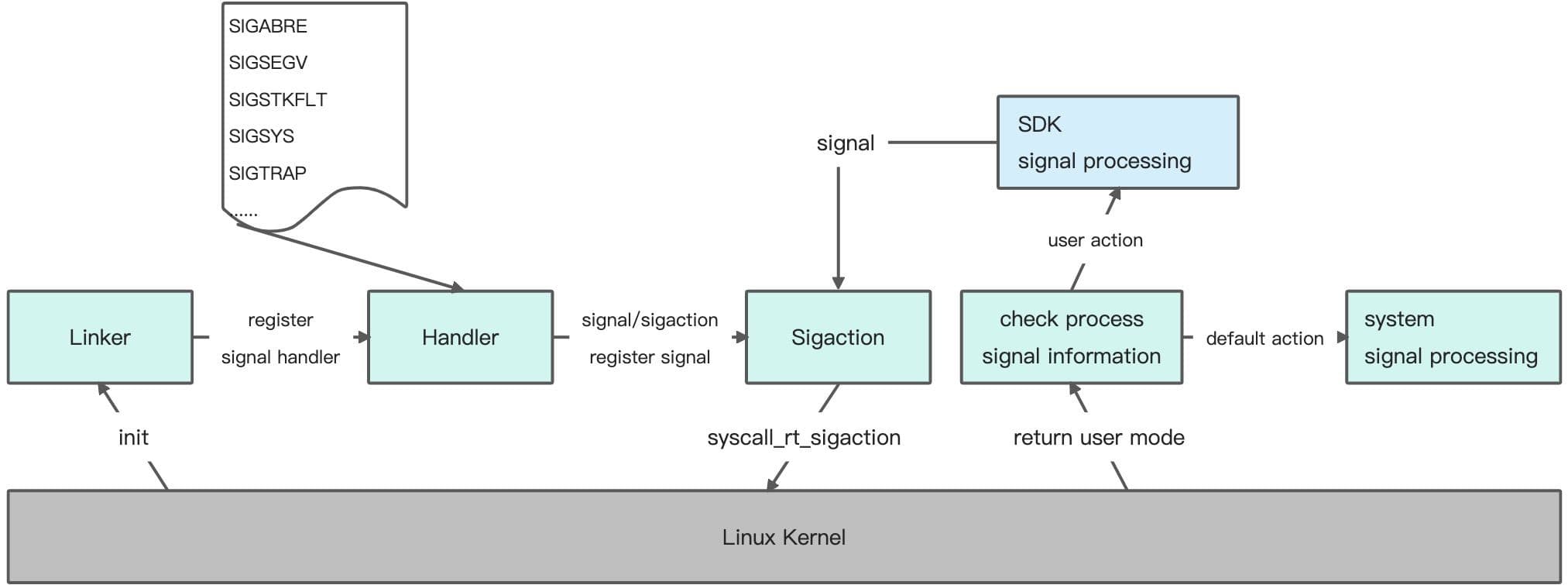
當然,除了穩定、安全的捕獲能力外,還需要豐富崩潰現場的上下文信息,比如Logcat信息、調用棧信息、設備信息、環境信息等等,為我們后續定位和解決問題提供全面的參考。
對于發生崩潰的情況,我們使用崩潰率作為數據指標。包括:
- UV崩潰率,也就是發生崩潰錯誤的去重用戶/去重活躍總用戶;
- PV崩潰率,也就是發生崩潰錯誤的次數/啟動次數;
啟動崩潰率,也就是應用啟動過程中發生的崩潰,很容易被忽略但又非常重要的崩潰指標,因為啟動是APP生命周期中非常重要的一個階段,很多廣告、閃屏、活動等內容都在這個過程中透出,同時啟動時又需要加載各種初始化,并且如果啟動出現錯誤,往往熱修復、降級融災策略都無法彌補。
ANR,也就是Application Not Responding,當應用程序一段時間無法及時響應,則會彈出ANR對話框,讓用戶選擇繼續等待,還是強制關閉。從用戶體驗的角度看,有時候ANR可能要比崩潰會帶來更糟糕的體驗,所以開發者重視崩潰的同時也要非常重視ANR。
ANR捕獲的準確性一直是不斷升級打怪、不斷完善的過程。早期我們通過FileObserver 監聽/data/anr/traces.txt文件的變化進行捕獲和上報,但很遺憾隨著版本升級,系統和廠商開始收緊系統文件的權限,此方案的覆蓋設備情況越來越低,造成ANR捕獲的準確性也一直降低。
隨后我們改進為監控消息隊列的運行時間的方式捕獲ANR,也就是向主線程Looper中放入一個空消息,監聽該空消息在5秒后是否被執行,但該方案無法真實的捕獲ANR情況(存在漏報和誤報情況),并且也無法得到完整的ANR內容。后續我們參考Android ANR的實現原理,實現了一套實時、準確的ANR捕獲方案,并且可以兼容所有系統版本。我們知道系統的system_server 進程在檢測到 APP 出現 ANR 后,會向出現ANR 的進程發送 SIGQUIT (signal 3) 信號。默認情況,系統的 libart.so 會收到該信號,并調用 Java 虛擬機的 dump 方法生成 traces。
我們通過攔截SIGQUT,在出現ANR時優先接收到信號,并生成traces和ANR日志,在處理完信號后,將信號繼續傳遞給系統讓系統生成traces文件,生成traces文件時,在保證內容與系統原生的一致性的同時還對生成traces文件的速度進行了明顯的提升,有效地避免了可能因生成 traces 時間過長,而被 system_server 使用 SIGKILL (signal 9) 再次強殺,同時我們對捕獲到的內容進行了豐富,包括:觸發 ANR 的原因、手機中 TOP 進程CPU 使用率、ANR 進程中 TOP 線程 CPU 使用率、CPU 各核心處理時間分布情況、磁盤 IO 操作等待時長等重要信息,對分析、定位和解決 ANR 問題,提供了更加強有力的支撐!
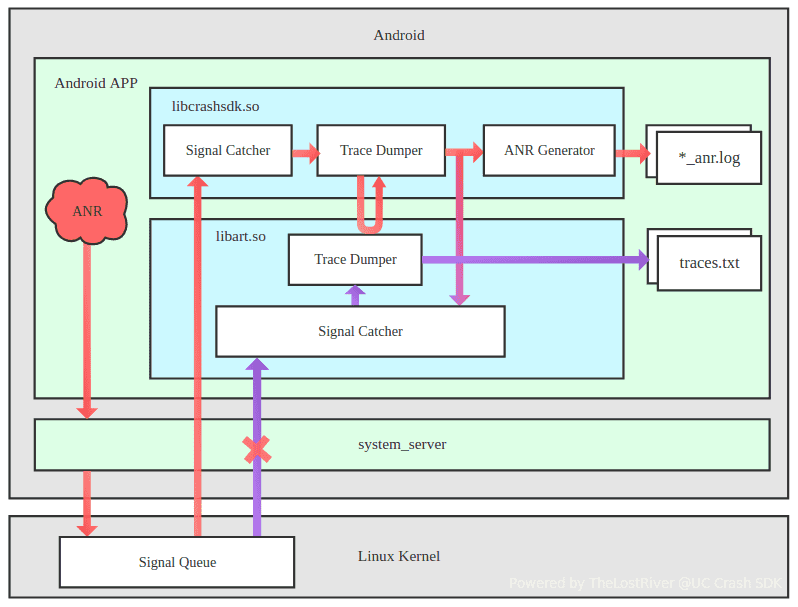
同樣對于發生ANR的情況,我們也分為UV ANR率和PV ANR率,算法可參考如上崩潰率的計算。
當然,除了崩潰和ANR,我們往往忽略了異常退出這種場景,但往往通過異常退出我們可以發現如low memory killer、系統重啟等無法正常捕獲到的問題。比如兼容性問題導致的閃退、設備重啟、三方庫主動調用exit函數,導致應用閃退次數增加等難以發現的問題,所以通過異常退出率我們可以比較全面的了解和衡量應用的穩定性。
綜上,對于文章開始的那個問題,我想大家都應該有答案了吧。當然,我們不應該為了掩蓋代碼質量問題,通過手動try catch去規避某些問題,這樣有可能會打斷用戶的正常使用,并造成感知性的阻斷反饋,應該從用戶使用APP時的真實感知出發,當出現問題時及時捕獲和處理問題。
App的穩定性是一個長期不斷迭代的過程,在這個過程中U-APM是一個很好的提升效率降低成本的工具,他提供了收集、解析、聚合、分析的能力,下一期我們會從如何通過U-APM解決和處理崩潰、ANR等問題進行講解,敬請期待。




















